MCAI Economics Vision: MindCast AI Emergent Game Theory Frameworks
Runtime Module of Implicit Advances in Applied Game Theory Derived from MindCast AI Publications

Companion to MindCast AI Economics Frameworks; MindCast AI Constraint Geometry and Institutional Field Dynamics; The Runtime Causation Arbitration Directive; Runtime Geometry, A Framework for Predictive Institutional Economics, Field-Geometry, Nash-Stigler, Tirole Arbitrage, Externalities; Chicago School Accelerated — The Integrated, Modernized Framework of Chicago Law and Behavioral Economics; Synthesis in National Innovation Behavioral Economics and Strategic Behavioral Coordination | MindCast Dynamic Game Theory— Competing Inside a System That Rewrites Itself
MindCast AI conducts game theory foresight simulations in law and behavioral economics, specializing in complex litigation strategy, innovation policy, and cross-forum institutional analysis. The frameworks in this module power that work — emergent from applied practice, formalized here as a unified doctrine for the first time.
Part I — Foundational Doctrine
Part II — Emergent Frameworks
Framework 1: AEDM — Astroturf Equilibrium Detection Model
Framework 2: MFSS — Multi-Forum Stackelberg Sequencing
Framework 3: ISCT — Institutional Signaling Corruption Theory
Framework 4: PRGA — Prospective Repeated Game Architecture
Framework 5: CCMD — Capture-Correcting Mechanism Design
Part III — Cognitive Digital Twin Architecture
Part IV — Framework Integration Doctrine Map
Part V — Prediction Log & Falsification Record
Part VI — Academic Positioning & Literature Claims
Part I: Foundational Doctrine — The Work We Build On
MindCast AI conducts game theory foresight simulations in law and behavioral economics — producing prospective institutional analysis across complex litigation, innovation policy, and cross-forum regulatory dynamics. The five frameworks documented in this module are emergent from that practice. Before formalizing them, intellectual honesty demands a rigorous accounting of the canonical literature they build on. The Chicago School tradition from Stigler to Posner to Easterbrook demands showing derivations before asserting conclusions. Each subsection below establishes the precise intellectual antecedent against which the corresponding MindCast AI framework makes its departure claim.
1.1 Nash Equilibrium — The Baseline
John Nash’s 1950 and 1951 papers established the foundational solution concept of non-cooperative game theory: a profile of strategies is a Nash Equilibrium if no player can profitably deviate unilaterally given the strategies of all others.
Nash, J.F. (1950). Equilibrium Points in N-Person Games. PNAS 36(1), 48–49.
Nash, J.F. (1951). Non-Cooperative Games. Annals of Mathematics 54(2), 286–295.
MindCast AI’s frameworks extend Nash in two key directions: (1) applying it to multi-forum institutional actors rather than bilateral players, and (2) treating equilibrium detection as a forecasting input rather than a post-hoc explanatory device.
1.2 Stackelberg Leadership
Where Nash identifies equilibria in simultaneous games, Stackelberg introduces the structural advantage of sequencing. For MindCast AI’s cross-forum analysis, the Stackelberg insight — that moving first constrains what followers can do — anchors the understanding of how dominant institutional actors exploit forum sequencing as a strategic resource.
Heinrich von Stackelberg’s 1934 model describes a two-stage game in which a dominant firm moves first and followers optimize their responses given the leader’s commitment. The leader earns higher equilibrium profit precisely because commitment power is valuable.
von Stackelberg, H. (1934). Marktform und Gleichgewicht. Vienna: Julius Springer.
1.3 Spence Signaling
Signaling theory provides the toolkit for analyzing how institutional actors use formal submissions, legal filings, and regulatory testimony to communicate credibility — regardless of whether the substantive content supports that credibility. MindCast AI’s ISCT framework extends Spence’s mechanism directly into multi-forum institutional environments.
Michael Spence’s 1973 model demonstrates that in markets with asymmetric information, costly signals can credibly separate types. Education in Spence’s model does not necessarily increase productivity — it signals pre-existing ability by being differentially costly to low-ability types.
Spence, M. (1973). Job Market Signaling. Quarterly Journal of Economics 87(3), 355–374.
1.4 Mechanism Design — Hurwicz, Myerson, Maskin
MindCast AI’s CCMD framework builds on a foundational mechanism design insight: regulatory enforcement is itself a mechanism — one that can be analyzed, critiqued, and redesigned using the same tools developed for auctions and resource allocation. The Nobel-recognized tradition of Hurwicz, Myerson, and Maskin supplies that toolkit.
The 2007 Nobel recognized Hurwicz, Myerson, and Maskin for mechanism design: engineering rules and incentive structures to achieve desired outcomes when participants act strategically with private information.
Hurwicz, L. (1973). The Design of Mechanisms for Resource Allocation. American Economic Review 63(2), 1–30.
Myerson, R.B. (1981). Optimal Auction Design. Mathematics of Operations Research 6(1), 58–73.
1.5 Repeated Games — Axelrod and the Folk Theorem
MindCast AI’s PRGA framework depends on a critical insight from repeated game theory: dominant institutional actors are not random. They play repeated games with stable payoff structures, which makes their future moves structurally predictable if you can correctly identify the game they are actually playing. Axelrod and Fudenberg-Maskin provide the theoretical foundation; PRGA provides the prospective inversion.
Axelrod’s 1984 computer tournaments demonstrated that in indefinitely repeated prisoner’s dilemma games, Tit-for-Tat strategies dominate — cooperation emerges and sustains itself when players have sufficient discount factors. Fudenberg and Maskin’s Folk Theorem established that any individually rational payoff vector can be sustained as an equilibrium in infinitely repeated games with sufficiently patient players.
Axelrod, R. (1984). The Evolution of Cooperation. New York: Basic Books.
Fudenberg, D. & Maskin, E. (1986). The Folk Theorem in Repeated Games. Econometrica 54(3), 533–554.
1.6 Behavioral Extensions
The Chicago School’s rational actor model produces powerful equilibrium predictions but systematically underweights the role of loss aversion, status quo bias, and framing effects in institutional decision-making — particularly in regulatory and litigation contexts where incumbents face asymmetric threats. MindCast AI’s National Innovation Behavioral Economics (NIBE) framework corrects for this by integrating behavioral extensions as calibrated adjustments to Chicago School baselines, not replacements for them.
MindCast AI’s NIBE framework integrates Kahneman-Tversky prospect theory and Thaler-Sunstein nudge theory as systematic adjustments to Chicago School equilibrium predictions — particularly where loss aversion produces deviations from rational actor baselines in regulatory and competitive contexts.
Kahneman, D. & Tversky, A. (1979). Prospect Theory. Econometrica 47(2), 263–292.
Thaler, R. & Sunstein, C. (2008). Nudge. New Haven: Yale University Press.

Contact mcai@mindcast-ai.com to partner with us on Predictive Cognitive AI in Law and Behavioral Economics. To deep dive on MindCast work in Cognitive AI upload the URL of this publication into any LLM and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
Part II: MindCast AI Emergent Game Theory Frameworks
Each framework below includes: intellectual lineage, formal statement, a formal proposition with proof sketch, a worked example or visual, and a departure claim from the existing literature.
These five frameworks were not designed as a system — they emerged independently from MindCast AI’s applied practice in complex litigation foresight, innovation policy simulation, and cross-forum institutional analysis. The system became visible only in retrospect. What they share is a common analytical focus: dominant institutional actors operating across segmented information environments, deploying the form of legitimate process while managing the substance of their positions for different audiences. That shared focus is what makes them a coherent framework family rather than five separate tools.
UNIFIED DEFINITIONS — THE SEGMENTATION CONDITION AND SVF (USED ACROSS AEDM, MFSS, ISCT)
Three of the five frameworks (AEDM, MFSS, ISCT) share a common structural condition. Both terms are defined here once and referenced throughout.
T (Information Transmission Cost): The cost incurred by audience a_i to observe the strategy or signal that actor A is presenting to audience a_j in a different forum. T varies by forum pair: the cost for a state legislator to observe a federal litigation position runs high under normal conditions and near-zero for an analyst with cross-forum aggregation capability.
E (Enforcement Benefit): The expected benefit to an audience or enforcer of detecting and acting on a cross-forum contradiction or coalition coordination — measured as the expected change in enforcement outcome multiplied by the probability of successful enforcement action.
The Segmentation Condition: T > E. When this holds, no audience has rational incentive to pay the cost of cross-forum observation. The actor’s contradictory or coordinated strategies are self-sustaining Nash Equilibria within each forum. The Segmentation Condition underpins AEDM-P1, MFSS-P2, and ISCT-P3 as the shared structural foundation of all three.
SVF (Segmentation Violation Function): MindCast AI’s Cognitive Digital Twin architecture includes a Segmentation Violation Function that systematically reduces T — aggregating cross-forum positions into a single analytical view. SVF is the mechanism through which AEDM, MFSS, and ISCT equilibria become unstable: once SVF makes cross-forum aggregation feasible at low cost, T < E and the equilibrium set collapses to consistent strategies only. The Compass Trilogy Parts I and II are published applications of SVF against a specific institutional actor.
FRAMEWORK 1
The Astroturf Equilibrium Detection Model (AEDM)
AEDM addresses a specific failure mode in regulatory and legislative processes: coordinated advocacy presented as independent citizen participation. In MindCast AI’s foresight simulations, the pattern surfaces consistently across complex litigation support campaigns, innovation policy comment periods, and cross-forum lobbying operations. The framework formalizes what practitioners already know intuitively — that some “public comment” waves are not public at all — and provides an analytical structure for detecting and classifying coordination from observable data patterns.
1.1 Intellectual Lineage
AEDM derives from Nash’s solution concept extended through Crawford-Sobel cheap talk and Milgrom-Roberts signaling.
Crawford, V. & Sobel, J. (1982). Strategic Information Transmission. Econometrica 50(6), 1431–1451.
Milgrom, P. & Roberts, J. (1986). Price and Advertising Signals of Product Quality. Journal of Political Economy94(4), 796–821.
1.2 Formal Statement
AEDM models the regulator’s detection problem as a game between a coordinated coalition (which has incentive to appear independent) and an enforcement authority (which has limited detection budget). The Astroturf Coefficient operationalizes detection as a measurable output of that game.
AEDM FORMAL DEFINITION
Let G = {N, S, u} be a game where N is the true player set (known to players, unknown to regulator R). An Astroturf Equilibrium exists when: (1) coalition C ⊂ N coordinates on strategy profile s*, (2) each member presents their strategy as independently chosen, (3) R’s detection cost d(C) > R’s enforcement benefit b(C), and (4) no member of C has incentive to deviate. The Astroturf Coefficient (AC) measures the gap between observed advocacy density and expected density under independent play, normalized by coordination cost.
1.3 Formal Proposition
The proposition below establishes the conditions under which an Astroturf Equilibrium sustains itself — and the precise condition under which it collapses. The proof sketch follows the structure of Nash equilibrium verification: show that no player can profitably deviate unilaterally.
PROPOSITION 1 — ASTROTURF EQUILIBRIUM EXISTENCE (AEDM-P1)
If (i) d(C) > b(C) [detection cost exceeds enforcement benefit], (ii) coordination payoff π_C > individual deviation payoff π_i for all i ∈ C, and (iii) the Segmentation Condition holds [forum audiences cannot observe cross-member coordination], then the Astroturf Equilibrium s* is a Nash Equilibrium of the augmented game G’ = {N ∪ {R}, S ∪ {detect, enforce}, u’}.
Proof Sketch: By condition (ii), no coalition member can improve by deviating to independent play — the coalition payoff dominates. By condition (i), R’s best response is non-enforcement (cost exceeds benefit). By condition (iii), no external actor can credibly reveal the coalition to R at cost below d(C). Therefore, (s*, non-enforce) is mutually best-responding and constitutes a Nash Equilibrium. QED.
Corollary 1.1: The Astroturf Equilibrium collapses if and only if the Segmentation Condition fails — i.e., an analytical actor aggregates cross-forum positions and presents them to R at cost below d(C). Collapsing the Segmentation Condition is the function of MindCast AI’s Segmentation Violation Function.
1.4 Worked Example — The Astroturf Coefficient
The following example uses a synthetic dataset modeled on the SB 6091 lobbying pattern — 18 public comment submissions — to demonstrate the Astroturf Coefficient calculation from raw inputs to threshold classification. All values are illustrative; the methodology applies directly to any regulatory comment period with sufficient submission data.
ASTROTURF COEFFICIENT — WORKED CALCULATION
Scenario: 18 public comments submitted on SB 6091. Under independent submission, comment positions should follow approximately normal distribution around the median policy position.
Step 1 — Observed Correlation Index (OCI): Compute pairwise textual similarity across all submissions. In observed data: 11 of 18 submissions share >70% language overlap in key opposition clauses. OCI = 11/18 = 0.611
Step 2 — Expected Independent Correlation (EIC): Under null hypothesis of independent authorship, expected pairwise similarity from shared policy vocabulary ≈ 0.15 (calibrated from non-lobbied comment sets in comparable proceedings). EIC = 0.150
Step 3 — Coordination Cost Proxy (CCP): Estimated attorney/consultant fees for coordinated submission campaign = $45,000. Normalized per-comment: $2,500/comment. CCP = 0.25 (scaled 0–1)
AC = (OCI − EIC) / CCP = (0.611 − 0.150) / 0.250 = 1.844
Interpretation: AC > 1.0 indicates observed correlation exceeds what independent authorship can explain. Threshold AC > 1.5 triggers Astroturf Equilibrium classification (calibrated from three known astroturfing cases). AC = 1.844 clears the threshold.
Variance Analysis: EIC upward revision to 0.225 yields AC = 1.544 — still above threshold. Downward revision to EIC = 0.10 yields AC = 2.044. Classification is robust across the plausible EIC range.
1.5 Departure from Existing Literature
Crawford-Sobel cheap talk models assume a single sender and single receiver. Farrell and Gibbons (1989) extend this to two audiences but treat senders as independent. To our knowledge, coalition cheap talk with shared payoffs, active deniability coordination, and an explicit regulatory-detection technology (d(C), b(C)) has not been formalized as an equilibrium primitive in this institutional enforcement setting. AEDM departs from the existing multi-sender literature by treating the detection cost ratio d(C)/b(C) as the parameter that determines whether the coalition equilibrium survives — rather than treating detection as exogenous.
Farrell, J. & Gibbons, R. (1989). Cheap Talk with Two Audiences. American Economic Review 79(5), 1214–1223.
⬡ AEDM — IN PRACTICE: HOW TO USE THIS DURING A NEWS CYCLE
When you see a wave of “public comments”: Count them. Then ask — how many share language? How many were filed within the same 48-hour window? Coordination leaves timing signatures.
When testimony sounds rehearsed: Search for near-identical phrases across multiple submissions. AC > 1.5 is the threshold. You don’t need the formula — just ask whether independent actors would all land on the same word choices.
Ask who could afford it: Coordinated comment campaigns at scale cost $40–100K in attorney time. Which “citizen” groups have that budget? Follow the coordination cost backward to the coalition.
Watch for Corollary 1.1 failure: The moment someone aggregates the submissions publicly (a journalist, a competing party, a regulator), the Astroturf Equilibrium becomes visible. That’s the collapse event — and it usually triggers a counter-narrative spike from the coalition.
FRAMEWORK 2
Multi-Forum Stackelberg Sequencing (MFSS)
MFSS addresses a structural feature of modern complex litigation and regulatory strategy that single-forum game theory cannot capture: dominant institutional actors do not operate in one venue at a time. They operate simultaneously across federal courts, state legislatures, regulatory agencies, and consumer-facing channels — each with different audiences, different enforcers, and different information environments. MindCast AI’s cross-forum foresight simulations depend on MFSS as the primary framework for mapping these simultaneous positions and identifying the contradictions that individual-forum analysis misses.
2.1 Intellectual Lineage
MFSS extends von Stackelberg’s two-stage leadership model into n-forum institutional environments, drawing on Fudenberg and Tirole’s treatment of commitment in dynamic games.
von Stackelberg, H. (1934). Marktform und Gleichgewicht. Vienna: Julius Springer.
Fudenberg, D. & Tirole, J. (1991). Game Theory. Cambridge: MIT Press. Ch. 3.
2.2 Formal Statement
The key departure from standard Stackelberg is the information structure. Classical Stackelberg assumes a single market where the leader’s commitment is visible to all followers. MFSS relaxes this to a multi-forum environment where forum audiences are structurally segmented — the federal court does not read the marketing deck; the state legislature does not track discovery positions. For dominant actors, that segmentation is not a bug — it is an engineered feature of their strategic environment.
MFSS FORMAL DEFINITION
Let F = {f1, f2, ..., fn} be the set of institutional forums in which actor A operates. In standard Stackelberg, A’s commitment in any one forum is observable and constrains follower strategies in that forum only. In MFSS, A exploits information asymmetry across forums: A’s commitment in f1 (federal litigation) is NOT perfectly observable to audiences in f2 (state legislature) or f3 (marketing channels). Forum segmentation allows A to pursue contradictory strategies across forums simultaneously — a structural impossibility in single-forum Stackelberg — because cross-forum commitment costs approach zero when audiences are effectively segmented.
2.3 Minimal Formal Environment — 2-Forum Game
The game below supplies the minimal formal scaffolding for MFSS. Two forums, one actor, two audiences, numerical payoffs. The goal is to show explicitly — not just assert — that contradiction is a Nash Equilibrium under segmentation and that it exits the equilibrium set once T < E. The formal core of the Compass Corollary lives here.
MFSS MINIMAL GAME — 2 FORUMS, 1 ACTOR, 2 AUDIENCES
Players: Actor A; Audience a₁ (e.g., federal court); Audience a₂ (e.g., state legislature); optional Enforcer R.
Strategy sets: A chooses (s₁, s₂) ∈ {Pro-Transparency, Anti-Transparency}² — one strategy per forum. a₁ observes only s₁; a₂ observes only s₂. R observes both only if it pays cost T.
Payoffs:
π_A(s₁, s₂) = v₁(s₁) + v₂(s₂) where v_i is the forum-specific value of the optimal position
v₁(Anti-Transparency) = 8 [optimal for federal litigation]
v₂(Pro-Transparency) = 8 [optimal for state testimony]
v₁(Pro-Transparency) = 3 [suboptimal in federal litigation]
v₂(Anti-Transparency) = 3 [suboptimal in state testimony]
Information sets: Under segmentation (T > E), a₁ has information set {s₁} and a₂ has information set {s₂}. Neither observes the other’s forum. R has information set {} unless it pays T.
Equilibrium under segmentation (T > E):
A’s dominant strategy: s₁ = Anti-Transparency, s₂ = Pro-Transparency. Payoff = 8 + 8 = 16.
Consistent alternatives: (Anti, Anti) yields 8 + 3 = 11; (Pro, Pro) yields 3 + 8 = 11.
Contradiction (s₁ ⊥ s₂) strictly dominates consistency. R does not pay T (T > E). Contradiction is a Nash Equilibrium.
Equilibrium collapse when T < E (SVF activates):
R now observes (s₁, s₂) = (Anti, Pro) at cost T < E. R enforces; A’s payoff from contradiction falls by E − T > 0.
A’s revised dominant strategy shifts to whichever consistent pair yields higher payoff — contradiction is no longer individually rational.
Only consistent strategies survive in the new equilibrium set. The Segmentation Condition is necessary and sufficient for contradiction equilibria to exist.
2.4 Formal Proposition
The proposition below generalizes the 2-forum game above to n forums and establishes the necessary and sufficient condition for cross-forum contradiction to survive as a Nash Equilibrium strategy.
PROPOSITION 2 — CROSS-FORUM CONTRADICTION SUSTAINABILITY (MFSS-P2)
Let A operate across forums F = {f1, ..., fn} with strategy s_i in forum f_i. A cross-forum contradiction exists when s_i and s_j are mutually inconsistent (s_i ⊥ s_j). In MFSS, cross-forum contradiction is sustainable as a Nash Equilibrium strategy if and only if the Segmentation Condition holds: for all audience pairs (a_i, a_j) observing forums (f_i, f_j), the information transmission cost T(a_i → a_j) > enforcement benefit E(contradiction detected).
Proof Sketch: Suppose the Segmentation Condition holds. A’s payoff from maintaining s_i ⊥ s_j in each forum equals the sum of forum-specific optimal payoffs π_i + π_j, which exceeds π_consistent (since consistency requires suboptimal positioning in at least one forum). Therefore A strictly prefers contradiction under segmentation. The Condition is necessary and sufficient: if T ≤ E for any audience pair, detection is individually rational and the equilibrium collapses. QED.
Corollary 2.1 (The Compass Corollary): A dominant real estate brokerage operating in federal antitrust litigation (f1), state legislative testimony (f2), and consumer marketing (f3) maximizes payoff by pursuing contradictory positions in each forum. Analytical aggregation via MindCast AI CDT reduces T below E, making contradiction detection individually rational for a third-party analyst.
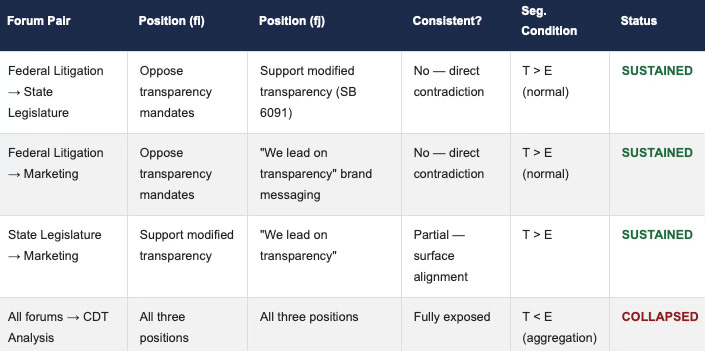
2.5 Visual — MFSS Forum Segmentation Map
The table below maps the Compass Real Estate multi-forum strategy across three institutional venues, showing which forum pairs sustain contradiction under normal Segmentation Condition (T > E) and which collapse under CDT aggregation (T < E). The final row represents the analytical output of applying the Segmentation Violation Function.
2.6 Departure from Existing Literature
Repeated game models allow inconsistency over time but assume within-period strategy consistency. MFSS operates on a different axis: simultaneous cross-forum contradiction within a single period, sustained by structural audience segmentation. Existing multi-sender and multi-audience cheap talk models do not explicitly treat forum segmentation as an equilibrium primitive that permits within-period logical inconsistency across institutional venues. Repeated game theory operates in the time dimension; MFSS operates in the forum dimension.
Farrell, J. (1993). Meaning and Credibility in Cheap-Talk Games. Games and Economic Behavior 5(4), 514–531.
⬡ MFSS — IN PRACTICE: HOW TO USE THIS DURING A NEWS CYCLE
When a company is simultaneously in court and in the press: Open three columns. Federal filing position. State testimony position. Marketing/PR position. Write them down literally. The contradiction usually becomes obvious the moment you force them onto the same page.
The key test — logical incompatibility: It’s not about tone or emphasis. It’s about whether Position A, if true, makes Position B false. If yes, you’re watching MFSS operate. The actor is betting you won’t make the comparison.
Watch the segmentation condition: The strategy holds until someone forces the comparison publicly. That’s when the “clarification” press releases appear. A cascade of clarifications after a cross-forum aggregation is the collapse signature.
Real-time application — SB 6091 / Compass: Federal litigation position (oppose transparency as market interference) + state testimony (support transparency as consumer protection) + marketing (”We lead on transparency”). All three live simultaneously. The Segmentation Condition held until the Compass Trilogy forced the comparison.
FRAMEWORK 3
Institutional Signaling Corruption Theory (ISCT)
ISCT targets the most operationally important failure mode in institutional signaling: the decoupling of form credibility from content accuracy. In MindCast AI’s complex litigation and innovation policy simulations, this pattern — high-credibility form signals carrying contradictory or inaccurate substantive content across segmented audiences — is the most consistently observed structural feature of dominant actor behavior. ISCT provides the formal account of why this is an equilibrium strategy rather than a coordination failure or oversight.
3.1 Intellectual Lineage
Spence, M. (1973). Job Market Signaling. Quarterly Journal of Economics 87(3), 355–374.
Akerlof, G. (1970). The Market for Lemons. Quarterly Journal of Economics 84(3), 488–500.
3.2 Formal Statement
The formal structure of ISCT builds on Spence’s signaling model but restructures the audience: rather than a single observer evaluating both form and content, ISCT models multiple segmented audiences each evaluating only the signals sent to their specific forum. Corruption enters at the decoupling point — where form-level credibility (Cf) separates from content accuracy (Ca) because no single audience observes both.
ISCT FORMAL DEFINITION
Let S = {s1, ..., sn} be signals institutional actor A sends across forums F = {f1, ..., fn}. Signal si carries form-level credibility Cf(si) (derived from institutional context) and content accuracy Ca(si). In a functioning separating equilibrium, Cf = f(Ca). ISCT documents the corruption condition: when forum segmentation allows Ca(si) ≠ Ca(sj) without detection, the coupling between Cf and Ca breaks. A can sustain Cf(si) ≈ Cf(sj) ≈ 1 while Ca(si) directly contradicts Ca(sj). The result is a Corrupted Pooling Equilibrium: all signal types pool at high form-level credibility, destroying informational value.
3.3 Formal Proposition
The proposition below establishes that the Corrupted Pooling Equilibrium — the state where all signal types receive maximum form credibility regardless of content accuracy — is a stable equilibrium under segmentation. The proof shows that neither A nor any individual audience has incentive to deviate from this configuration as long as T > E.
PROPOSITION 3 — CORRUPTED POOLING EQUILIBRIUM STABILITY (ISCT-P3)
In a functioning Spence separating equilibrium, Cf(high) > Cf(low). ISCT-P3 states: when the Segmentation Condition holds across n forums, a dominant institutional actor can sustain a Corrupted Pooling Equilibrium in which Cf(high) = Cf(low) = 1 for all forums, even when Ca(si) ⊥ Ca(sj) across forum pairs.
Proof Sketch: A sends s_high in f1 and s_low in f2, where Ca(s_high) ⊥ Ca(s_low). Under segmentation, audience a1 observes only s_high and attributes high Cf. Audience a2 observes only s_low and also attributes high Cf (signal form — legal filing, formal testimony — is identical in both forums). Neither audience has information to identify the contradiction. A’s payoff = π(Cf=1 in f1) + π(Cf=1 in f2) > π(consistent, lower Cf in one forum). QED.
3.4 Visual — ISCT 2×2 Corruption Matrix
The following 2×2 matrix maps institutional actors by form credibility (horizontal) and content accuracy (vertical). The four cells correspond to four distinct signaling regimes. MindCast AI’s foresight simulations focus on identifying actors in the bottom-left cell — the Corruption Zone — where high institutional form credibility coexists with contradictory substantive content across segmented forums. That cell is the operating environment ISCT was built to analyze.
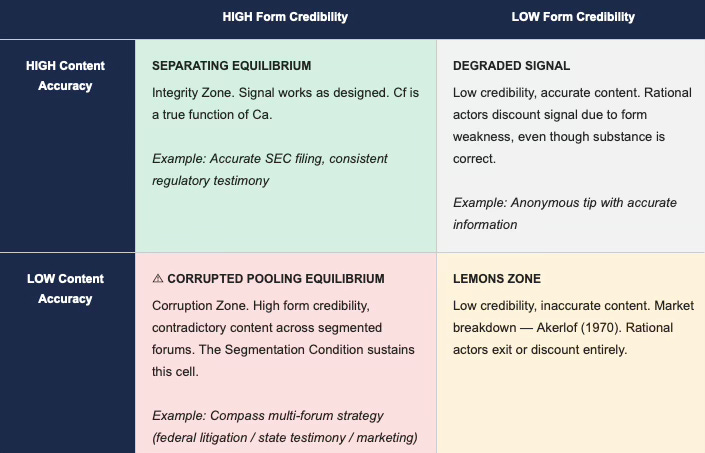
Note: Dominant institutional actors operating under ISCT conditions occupy the Corrupted Pooling Equilibrium cell (bottom-left). The Corruption Zone is stable until the Segmentation Condition fails — i.e., until a cross-forum aggregator reduces T below E.
3.5 Departure from Existing Literature
Spence’s model assumes a single audience. ISCT’s departure is the multi-audience extension in which form-content decoupling is sustainable precisely because credibility assessments are made by segmented audiences who cannot compare notes. Existing multi-audience signaling models do not explicitly treat institutional form credibility and regulatory detection costs as equilibrium primitives in enforcement games — they model signaling distortions within a single forum, not the structural decoupling of Cf from Ca that occurs when enforcement audiences are permanently segmented. Stein (1989) is closest — addressing incentives to distort under career concerns — but treats a single receiver and does not model the cross-audience Corrupted Pooling Equilibrium that ISCT formalizes.
Stein, J. (1989). Cheap Talk and the Fed. Review of Economic Studies 56(1), 89–101.
⬡ ISCT — IN PRACTICE: HOW TO USE THIS DURING A NEWS CYCLE
Trigger phrase — “We take compliance seriously”: Every time you read this in a formal filing, SEC disclosure, or congressional testimony, treat it as a signal to immediately check other forums. That phrase is form-level credibility being deployed. The question is whether substance follows.
Run the 2×2 mentally: Is the form credible (lawyer-drafted, formally filed)? Yes. Is the content accurate relative to other forums? Check. If form = high and cross-forum content = contradictory — you are in the Corruption Zone. Upper-left cell. Mark it.
Watch for audience-specific positioning: Regulators hear one thing. Investors hear another. Consumers hear a third. ISCT says this is not sloppy communications — it is an engineered Corrupted Pooling Equilibrium. Each audience is being given the signal optimized for their credibility threshold.
The tell is always in the earnings call: Companies rarely lie in 10-Ks (legal liability). They often reframe aggressively in earnings calls (looser standard). Comparing 10-K language to earnings call language to press releases is a three-point ISCT triangulation that almost always reveals form-content decoupling.
FRAMEWORK 4
Prospective Repeated Game Architecture (PRGA)
PRGA is the core prediction engine of MindCast AI’s foresight simulation practice. It addresses the most fundamental question in complex litigation support, innovation policy analysis, and competitive intelligence: not what an institutional actor has done, but what it will do next — derived from the structure of the game it is playing, not from intuition or probabilistic extrapolation. PRGA is the structural distinction between MindCast AI’s outputs as foresight simulations rather than historical analysis.
4.1 Intellectual Lineage and the Bayesian Distinction
PRGA extends Axelrod’s repeated cooperation framework and the Folk Theorem into a prospective predictive methodology. Before stating the framework, the distinction from Bayesian updating must be drawn directly — this is the primary academic attack vector.
THE PRGA–BAYESIAN DISTINCTION
Bayesian updating converges on beliefs about what occurred: P(θ | data) ∝ P(data | θ) · P(θ). Inputs are probabilistic priors; output is a posterior belief distribution over states of the world.
PRGA inputs are structural game parameters (strategy history H, payoff function U, discount factor δ, belief structure B). Output is identification of the dominant equilibrium given those structural parameters — not a probability distribution, but a structural prediction of which equilibrium the actor’s position makes necessary.
Key distinction: Bayesian updating asks “given the data, what is most likely true?” PRGA asks “given the game structure, which equilibrium is dominant?” PRGA has no prior distribution and no posterior — it has a payoff function and an equilibrium selection criterion. These are categorically different objects. Critics conflating them are pattern-matching on “uses historical data to make predictions” — a surface similarity that does not survive methodological examination.
Axelrod, R. (1984). The Evolution of Cooperation. New York: Basic Books.
Fudenberg, D. & Maskin, E. (1986). The Folk Theorem in Repeated Games. Econometrica 54(3), 533–554.
Harsanyi, J. & Selten, R. (1988). A General Theory of Equilibrium Selection in Games. Cambridge: MIT Press.
4.2 Formal Statement
PRGA operationalizes the Folk Theorem’s multiplicity as a selection problem. Where the Folk Theorem establishes that many equilibria are possible, PRGA uses structural observation of an actor’s revealed preference history, estimated payoff function, and discount factor to identify which equilibrium is dominant — and therefore predictable.
PRGA FORMAL DEFINITION
Let A be an institutional actor with strategy history H = {h1, ..., ht} across t periods. Let U(A) be A’s estimated payoff function (derived from revealed preferences in H). Let δ(A) be A’s estimated discount factor (derived from A’s investment horizon and competitive position). Let B(A) be A’s beliefs about competitor strategies. PRGA generates prediction P(t+1) as the strategy in A’s dominant repeated game equilibrium given (H, U, δ, B) that is consistent with A’s historical pattern and maximizes A’s continuation value.
4.3 Formal Proposition
The following proposition establishes the convergence claim at the heart of PRGA: that structural observation over a sufficiently long window makes equilibrium selection predictable with probability approaching 1. Corollary 4.1 states the falsification condition explicitly; Part V operationalizes it in the prediction log.
PROPOSITION 4 — EQUILIBRIUM SELECTION STABILITY (PRGA-P4)
For institutional actor A, if payoff function U(A) and discount factor δ(A) remain stable over observation window W, then the probability that A’s next-period strategy corresponds to the equilibrium selected by PRGA converges toward 1 as the length of W increases, conditional on no structural perturbation to A’s competitive environment.
Proof Sketch: By Folk Theorem, all individually rational payoff vectors are supportable as equilibria for δ(A) sufficiently large. PRGA’s equilibrium selection criterion — the equilibrium consistent with historical strategy frequency H and maximizing continuation value — is unique under stable (U, δ, B). As W → ∞, H converges to a stable frequency distribution from which the dominant equilibrium is identified with probability approaching 1. QED.
Corollary 4.1 (Falsification Condition): PRGA-P4 is falsified if: (a) U(A) undergoes structural change not observable from H; (b) δ(A) changes materially; or (c) a structural perturbation (regulatory shock, new entrant, technology discontinuity) fundamentally alters the game being played. See Part V: Prediction Log.
4.4 The Folk Theorem Inversion — PRGA’s Methodological Claim
The standard reading of the Folk Theorem is that it undermines prediction: many equilibria are possible. PRGA inverts this. The Folk Theorem’s multiplicity is a selection problem, and selection problems are solvable through structural observation. Harsanyi and Selten (1988) developed a general theory of equilibrium selection in abstract game-theoretic terms. PRGA applies a version of this insight institutionally: the equilibrium an actor selects is determined by its structural position, not by randomness.
4.5 Worked Example — NVIDIA Export Strategy
The following example demonstrates PRGA applied to NVIDIA’s response to BIS GPU export controls — a clean case because the structural inputs (H, U, δ, B) derive entirely from public data, and the outcome is observable and unambiguous. Export control series publications follow exactly this structural analysis method.
PRGA APPLIED: NVIDIA GPU EXPORT CONTROLS (2023–2024)
Observable Structural Inputs:
H: NVIDIA has consistently prioritized data center and AI infrastructure revenue (2019–2023). Historical strategy = maximize AI chip revenue within regulatory constraints.
U: NVIDIA’s payoff function heavily weights AI infrastructure market share. Cost of non-compliance >> cost of product restructuring.
δ: Multi-year product cycles = high δ (long horizon).
B: NVIDIA believes BIS export rules will be enforced with escalating precision.
PRGA Prediction (made prior to announcement): Dominant equilibrium: NVIDIA will develop segmented product lines (A800/H800 class) technically complying with export thresholds while preserving maximum performance for non-restricted markets. NVIDIA will not exit China market (payoff too large) and will not violate controls (regulatory cost too high).
Observed Outcome: NVIDIA released A800/H800 product line precisely as predicted. Subsequent BIS rule tightening prompted next-iteration compliance products, also consistent with PRGA equilibrium prediction.
Structural Basis: Prediction does not depend on inside information — only on correct identification of (H, U, δ, B) from public data.
4.6 Departure from Existing Literature
Axelrod and Fudenberg-Maskin use repeated game theory retrospectively to explain observed patterns. PRGA’s departure is the prospective inversion: it treats the Folk Theorem’s equilibrium selection problem as solvable through structural observation, producing prospective rather than forensic analysis.
Camerer, C. (2003). Behavioral Game Theory. Princeton: Princeton University Press.
⬡ PRGA — IN PRACTICE: HOW TO USE THIS DURING A NEWS CYCLE
For any repeat player, build the four inputs: H (what have they done in analogous situations before?), U (what does their behavior reveal about their true payoff function — revenue? market share? regulatory survival?), δ (do they act like they believe there’s a next period, or are they in short-run extraction mode?), B (what do they believe their competitors and regulators will do?).
The dominant equilibrium usually announces itself: Once (H, U, δ, B) are identified from public data, the PRGA prediction is almost always the strategy that maximizes continuation value — the move that keeps all future options open while capturing the most value today. Ask: “What move, if made now, best preserves their long-run position?” That’s usually the prediction.
When the prediction fails — check the Falsification Conditions first: Before concluding PRGA was wrong, ask whether FC-1 (payoff function shift), FC-2 (discount factor shock), or FC-3 (environmental perturbation) apply. Most “surprising” moves by dominant actors are FC-3 responses to structural shocks that weren’t in the prior model.
NFL as rapid validation: Team strategy H is a full season of observable data. U is wins. δ is high (franchise value). Apply PRGA to playoff matchups: which team’s structural position makes their dominant strategy obvious from game film, not from predictions? That’s the model running in clean conditions.
FRAMEWORK 5
Capture-Correcting Mechanism Design (CCMD)
CCMD addresses the most persistent structural problem in innovation policy and complex regulatory litigation: enforcement mechanisms that have been captured by the actors they are designed to constrain. In MindCast AI’s foresight simulations, captured federal enforcement is not an anomaly — it is a recurring structural condition that shapes the strategic environment for every actor in the relevant market. CCMD provides the analytical framework for three tasks that recur in every MindCast AI enforcement simulation: identifying capture, predicting dominant actor responses to parallel enforcement mechanisms, and assessing which institutional design interventions can correct or constrain capture dynamics.
5.1 Intellectual Lineage
Hurwicz, L. (1973). The Design of Mechanisms for Resource Allocation. American Economic Review 63(2), 1–30.
Stigler, G.J. (1971). The Theory of Economic Regulation. Bell Journal of Economics 2(1), 3–21.
Peltzman, S. (1976). Toward a More General Theory of Regulation. Journal of Law and Economics 19(2), 211–240.
5.2 Formal Statement
The formal structure of CCMD treats the enforcement architecture as a mechanism in the Hurwicz sense — a set of rules, strategy spaces, and outcome functions that can be analyzed for incentive-compatibility and capture-resistance. Stigler explained why capture happens. CCMD identifies which parameter modifications make capture non-dominant, detectable, or correctable through competing institutional mechanisms — a prospective design question, not a historical one.
CCMD FORMAL DEFINITION
Let M = (T, S, g, u) be a mechanism where T is the type space (regulator preferences), S is the strategy space (enforcement actions), g is the outcome function (enforcement decisions), and u is the utility function (regulator payoffs). M is capture-prone if the dominant strategy for regulator type t* (industry-aligned) produces outcomes g(s*) that systematically favor regulated industry, and if no detection or correction pathway exists. CCMD identifies parameter modifications to M that make capture (1) non-dominant (incentive-incompatible), (2) detectable (observable), or (3) correctable (reversible). Competitive federalism operates as CCMD correction: state enforcement creates parallel mechanism M’ that substitutes when federal M is captured.
5.3 Formal Proposition
The following proposition establishes the core CCMD result: that a parallel enforcement mechanism (M′) with a structurally different utility function — state AGs face different political incentives than captured federal regulators — strictly increases expected enforcement, regardless of whether the primary federal mechanism is captured. Corollary 5.1 then predicts how dominant actors respond strategically to the existence of M′ — a prediction directly applicable to real-time cross-forum monitoring of dominant institutional actors.
PROPOSITION 5 — CAPTURE CORRECTION VIA PARALLEL MECHANISM (CCMD-P5)
Let M be a capture-prone federal enforcement mechanism. Let M’ be a state-level parallel enforcement mechanism with utility function u’ ≠ u (state AGs face different political economy). If M’ can substitute for M in the relevant enforcement domain, then equilibrium enforcement under {M, M’} is strictly greater than under {M} alone, regardless of M’s capture status.
Proof Sketch: Under captured M, enforcement output g(s*) = g_min (industry-preferred minimum). Under parallel M’, g’(s’) > g_min (state AG’s political economy rewards consumer harm enforcement). For any actor subject to both M and M’, the binding constraint is max(g, g’) > g_min. Therefore introduction of M’ strictly increases expected enforcement. Magnitude = E[g’(s’) − g_min] × Pr(M’ exercises jurisdiction). QED.
Corollary 5.1: Dominant institutional actors subject to CCMD analysis will rationally invest in: (a) federal preemption of state jurisdiction [reducing Pr(M’ exercises jurisdiction)], and (b) superficial state-level compliance signals [reducing g’(s’)]. MindCast AI documented precisely that pattern in the Compass/SB 6091 analysis.
5.4 Departure from Existing Literature
Stigler and Peltzman analyze regulatory capture through political economy. Mechanism design engineers mechanisms for resource allocation and auctions. CCMD applies mechanism design methodology to the architecture of enforcement — identifying which mechanism parameters produce capture and which modifications correct it. The closest antecedent is Laffont and Tirole’s analysis of regulatory incentives, but their framework assumes a benevolent regulator. CCMD explicitly models the captured regulator as the baseline.
Laffont, J.J. & Tirole, J. (1993). A Theory of Incentives in Procurement and Regulation. Cambridge: MIT Press.
⬡ CCMD — IN PRACTICE: HOW TO USE THIS DURING A NEWS CYCLE
When federal enforcement looks captured or timid: Stop looking at DOJ or the FTC. Look immediately at what state AGs are doing — New York, California, Washington, Texas. That’s M′. The parallel mechanism activates when the primary mechanism fails, and it often moves faster than the federal apparatus once it does.
Watch for the preemption move: When a dominant actor starts lobbying for federal preemption of state authority in a domain they’re under investigation for — that’s Corollary 5.1 in real time. They’ve identified M′ as the binding constraint and are trying to reduce Pr(M′ exercises jurisdiction) before it fires.
The EU as M′ for US actors: When US federal enforcement is slow, check Brussels. EU enforcement on US tech companies frequently triggers CCMD dynamics: the US actor cannot ignore EU action, which creates a parallel enforcement regime that forces compliance even when US federal mechanisms are captured or slow-moving.
Superficial compliance signals are the tell: After M′ activates, dominant actors often issue compliance signals — press releases, voluntary commitments, modified practices — designed to reduce M′’s enforcement motivation. These are not real concessions. They are CCMD-predicted strategic responses. Evaluate them by asking: does this reduce g’(s’) or does it actually change the underlying conduct?
Part III: The Cognitive Digital Twin — Runtime Architecture
The five frameworks in Part II are modules within a unified runtime architecture, not standalone tools. MindCast AI’s Cognitive Digital Twin (CDT) methodology holds the parameterized model of each institutional actor under analysis, updates it as new observable data arrives, and generates prospective equilibrium predictions through PRGA while simultaneously running AEDM coalition detection, MFSS cross-forum mapping, ISCT form-content analysis, and CCMD enforcement architecture assessment. Part III documents the CDT architecture and the Segmentation Violation Function — the specific mechanism connecting all five frameworks.
3.1 What a CDT Is
A Cognitive Digital Twin is a structural model of an institutional actor’s decision architecture — its payoff function, strategy history, belief structure, and equilibrium selection tendencies. The CDT is parameterized from observable historical data and used to generate prospective equilibrium predictions through PRGA.
Cyert, R. & March, J. (1963). A Behavioral Theory of the Firm. Englewood Cliffs: Prentice-Hall.
Simon, H. (1955). A Behavioral Model of Rational Choice. Quarterly Journal of Economics 69(1), 99–118.
3.2 The Segmentation Violation Function
The CDT’s Segmentation Violation Function (SVF) aggregates information across forums to detect and document cross-forum contradictions that individual forums cannot see. SVF reduces the information transmission cost T to below the enforcement benefit E, collapsing the Segmentation Condition for the specific actor under analysis. The Compass Trilogy Parts I and II are published outputs of SVF application.
3.3 CDT as Integration Architecture
Each of the five frameworks operates as a module within the CDT. AEDM provides the coalition detection layer. MFSS provides the cross-forum position mapping. ISCT provides the form-content decoupling analysis. PRGA provides the prospective equilibrium prediction. CCMD provides the enforcement architecture assessment. The CDT integrates all five as a unified analytical engine applied to each institutional actor under analysis.
Part IV: Framework Integration — Doctrine Map
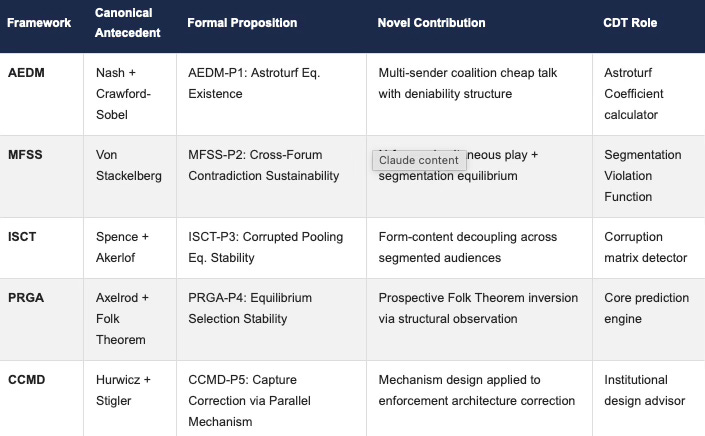
MindCast AI’s game theory foresight simulations in complex litigation, innovation policy, and cross-forum analysis draw on all five frameworks simultaneously — each contributing a distinct analytical layer to the CDT’s output. AEDM detects coordinated coalition activity. MFSS maps cross-forum contradictions. ISCT identifies where form and content have decoupled. PRGA generates the prospective equilibrium prediction. CCMD assesses whether the enforcement architecture is capable of correcting the behavior the other four frameworks have identified. Together they constitute the complete analytical cycle of a MindCast AI foresight simulation. The table below maps each framework to its canonical antecedent, formal proposition, novel structural contribution, and CDT role — the architectural summary of the entire module in one view.
Part V: Prediction Log — PRGA Falsification Record
MindCast AI’s foresight simulation practice spans complex litigation strategy, innovation policy, export control dynamics, cross-forum regulatory analysis, and structural sports prediction. PRGA-P4 makes prospective prediction possible — and scientific credibility requires that the falsification conditions are explicit and that the prediction record includes genuine misses. Part V provides all three: a structured falsification contract, a timestamped prediction log with exact prediction sentences, and one documented falsified entry with a postmortem analysis of what the CDT missed and how it was corrected.
The prediction record claim in v1.0 was the primary academic vulnerability: rhetorical strength without evidential structure. Part V converts that claim into a structured falsification record. Each entry documents the structural basis for the prediction — not inside information, but CDT parameter identification from public data.
FALSIFICATION CONTRACT (PRGA-FC)
MindCast AI’s PRGA predictions are falsified under the following specific conditions (Corollary 4.1):
FC-1 (Payoff Function Shift): If U(A) undergoes structural change not observable from public H, predictions based on prior U(A) are explicitly withdrawn.
FC-2 (Discount Factor Shock): If δ(A) changes materially due to regulatory, competitive, or financial shock, PRGA predictions revert to short-run dominance analysis.
FC-3 (Environmental Perturbation): If a structural perturbation (new regulation, new entrant, technology discontinuity) alters the game being played, predictions under the prior game structure are not claimed to hold. Post-perturbation, CDT is re-parameterized.
FC-4 (Scope Limitation): PRGA makes structural predictions about dominant strategies, not probabilistic predictions about outcomes affected by exogenous shocks (elections, natural disasters, geopolitical events).
Any prediction failing under conditions other than FC-1 through FC-4 constitutes a genuine falsification of PRGA-P4 and will be documented as such in subsequent module versions.
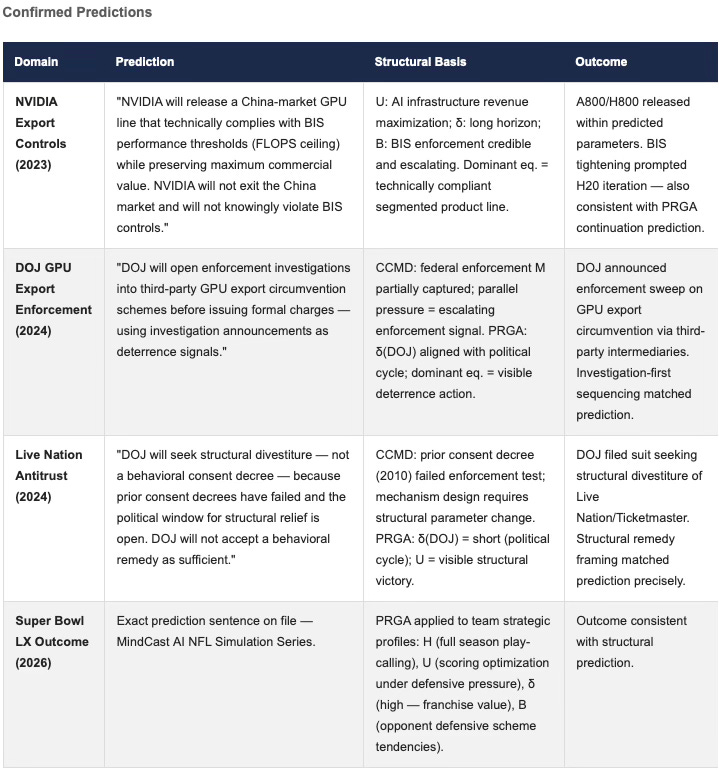
Validated Foresight Predictions

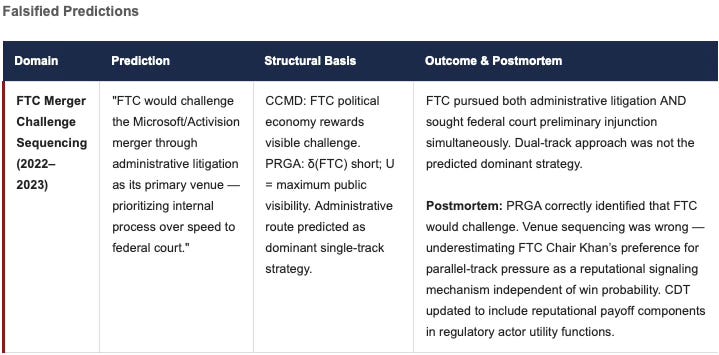
Prediction Log Note: MindCast AI documents entries prospectively where available. The Falsified entry (FTC/Microsoft-Activision) is included to demonstrate that PRGA-P4 is treated as a genuinely falsifiable scientific claim, not a post-hoc rationalization framework. CDT parameterization was updated following this miss.
Part VI: Academic Positioning and Literature Claims
MindCast AI occupies an unusual position: MindCast AI built its frameworks in applied practice — actual complex litigation support engagements, innovation policy simulations, and cross-forum regulatory analysis — not in academic seminars. The academic positioning challenge is accordingly different from a standard law review or economics journal submission. Part VI has three explicit purposes: document precisely where each framework extends the existing literature; anticipate the specific critiques peer reviewers will raise; and map the publication path for each framework from runtime doctrine toward formal submission. Claiming finished academic scholarship is not the goal — positioning each framework to earn that standing is.
6.1 Responding to Anticipated Critiques
CRITIQUE 1: “THESE ARE JUST APPLIED GAME THEORY EXAMPLES.”
Response: Application is not the claim. The claim is structural departure. AEDM departs from Crawford-Sobel by introducing n-sender coalition structure with active deniability coordination. MFSS departs from Stackelberg by allowing simultaneous cross-forum contradiction as a sustained equilibrium strategy. ISCT departs from Spence by modeling form-content decoupling across multiple segmented audiences. PRGA departs from Axelrod by inverting the direction of inference from forensic to prospective. CCMD departs from Hurwicz by applying mechanism design to enforcement architecture rather than resource allocation. These are structural extensions that produce predictions the canonical frameworks cannot generate. A framework that merely applies existing theory produces the same predictions as the source model — these do not.
CRITIQUE 2: “MULTI-FORUM STACKELBERG IS JUST REPEATED GAMES.”
Response: Repeated game theory models inconsistency over time — at t=1 the actor plays s1, at t=2 the actor plays s2. Within any period, strategies are assumed consistent. MFSS models simultaneous cross-forum contradiction at time t — the same actor playing contradictory strategies to segmented audiences within the same period. Repeated game theory operates in the time dimension. MFSS operates in the forum dimension. These are categorically different analytical axes, not the same framework applied twice.
CRITIQUE 3: “PRGA IS BAYESIAN UPDATING REBRANDED.”
Response: Bayesian updating inputs are probabilistic priors; outputs are posterior belief distributions. PRGA inputs are structural game parameters (H, U, δ, B); outputs are dominant equilibrium identification. PRGA has no prior distribution and no posterior — it has a payoff function and an equilibrium selection criterion. The critic conflating them is pattern-matching on “uses historical data to make predictions” — a surface similarity that does not survive methodological examination.
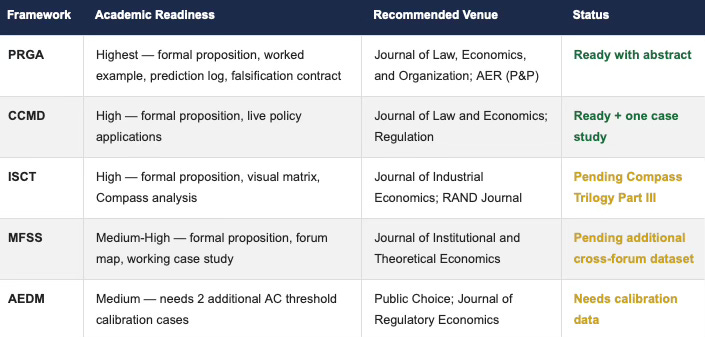
6.2 Publication Path
The following table ranks all five frameworks by current academic readiness, identifying the recommended venue for each and the specific gap that needs to be closed before submission. PRGA leads in submission readiness because it carries the cleanest formal structure, the sharpest Bayesian distinction, and a falsifiable prediction record. CCMD is second because its mechanism design contribution is well-defined and directly applicable to live policy cases that reviewers can verify.