

MCAI Innovation Vision: Google’s Deep-Thinking Ratio Measures Effort, Not Structure
Layer Turbulence Correlates with Correctness. It Cannot Certify It.

See also The Cognitive AI Response to Apple’s “The Illusion of Thinking”
Executive Summary
Google’s Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens(arXiv:2602.13517, February 2026) makes a meaningful contribution to inference-time evaluation. By replacing token length with a layer-wise stabilization metric, the paper demonstrates that internal distributional revision correlates more reliably with accuracy than raw verbosity. Think@n further shows that early turbulence signals can reduce inference cost by approximately 50% while preserving benchmark performance.
Correlation, however, is not sufficiency. Deep-Thinking Ratio (DTR) measures how long predictive distributions continue to revise across transformer depth before stabilizing. Structural reasoning requires something stronger: invariant satisfaction, valid causal spine construction, and principled termination at equilibrium. Appendix B of the same paper shows that accuracy can improve even as DTR decreases under higher reasoning modes — a dissociation that the authors acknowledge but do not resolve. That finding exposes a structural ceiling the paper does not address.
Internal turbulence improves efficiency. Structural closure determines correctness. The difference is architectural, not rhetorical.
A note on analytical posture: where MindCast AI’s response to Apple’s “The Illusion of Thinking” argued that Apple measured the wrong variable entirely — that compositional execution depth is not the operative constraint in institutional reasoning — the present analysis accepts DTR’s internal signal as real and asks what the signal cannot reach. Apple required a paradigm reframe. Google requires a boundary condition. The two papers demand different responses, and MindCast AI applies each on its own terms.
I. Token Length Failed; DTR Correctly Reframed the Signal
The DTR paper decisively rejects the “longer is better” heuristic. Across competition-level mathematical benchmarks — AIME 2024/2025, HMMT 2025, and GPQA-Diamond — token count correlates negatively with accuracy, reaching an average Pearson r of −0.594. Extended chains often reflect distraction, heuristic amplification, or recursive self-justification rather than disciplined convergence. The empirical collapse of token volume as a reasoning proxy is real and well-documented.
DTR replaces surface verbosity with a mechanistic measure. Instead of counting output tokens, it tracks Jensen–Shannon divergence between intermediate-layer and final-layer predictive distributions. Tokens that stabilize only in later layers are classified as “deep-thinking” tokens. The resulting ratio achieves an average correlation of r = 0.828 with accuracy across benchmarks — substantially outperforming both length-based and confidence-based baselines.
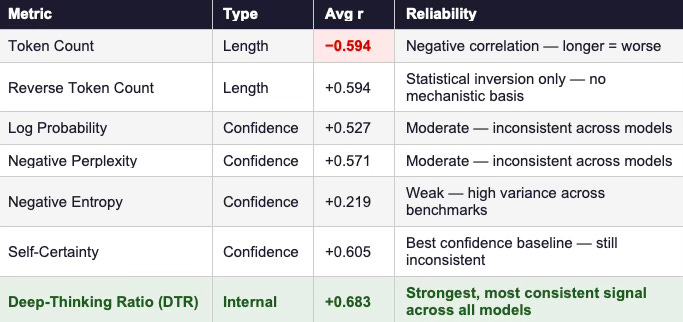
Table 1 — Average Pearson correlations between inference-time metrics and task accuracy across 8 model variants and 4 benchmarks (AIME 2024/25, HMMT 25, GPQA-Diamond). Source: Google DTR paper, Table 1.
That move matters. Measuring internal revision intensity captures computational refinement rather than symbolic sprawl. Think@n operationalizes this insight, ranking partial generations by early DTR estimates computed from as few as 50 prefix tokens, and halting low-quality trajectories before they consume full inference budgets. The qualitative example in Appendix E makes this concrete: the incorrect solution runs 27,724 tokens with DTR of 13.9%; the correct solution runs 3,725 tokens with DTR of 19.0%. Verbosity and correctness dissociate; depth and correctness align.
The paper successfully demonstrates that turbulence contains signal. The question is whether turbulence contains structure.
Contact mcai@mindcast-ai.com to partner with us on Predictive Cognitive AI in Law and Behavioral Economics. To deep dive on MindCast work in Cognitive AI upload the URL of this publication into any LLM and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
II. What DTR Measures — and What It Leaves Unmeasured
DTR quantifies late-layer convergence. For each generated token, intermediate-layer distributions are compared to the final-layer distribution using Jensen–Shannon divergence. The later convergence occurs, the more computationally intensive the token. Sequence-level DTR averages the proportion of such late-settling tokens.
The metric captures depth-wise revision energy. It does not evaluate whether the internal representation satisfies the governing constraints of the task. Stabilization signals that the model stopped revising. Stabilization does not certify that the reasoning path is structurally valid.
Appendix B of the DTR paper introduces a crucial internal complication. Higher reasoning-level configurations of GPT-OSS achieve better accuracy while producing lower DTR values, because longer sequences dilute the ratio. Depth-per-token decreases while total effective reasoning increases. Accuracy improves as the metric weakens. This dissociation appears within the paper’s own data, under the authors’ own conditions. A measure that systematically decouples from accuracy under reasoning-mode shifts cannot serve as a structural sufficiency condition.
The paper notes that “DTR might not be directly comparable across different models or model modes” and moves on. That acknowledgment requires more than a footnote. It identifies the boundary at which DTR’s predictive power is conditional rather than architectural.
III. Invariant Satisfaction: The Missing Variable
Structural reasoning operates under invariants. Mathematical proofs must preserve quantifier discipline across every transformation. Legal reasoning must maintain jurisdictional coherence and precedential hierarchy. Scientific reasoning must conserve constraints across representational shifts. Internal stabilization does not test invariant preservation; it only tests that revision has ceased.
Consider a formal proof with an early quantifier error. The model incorrectly treats ∃x P(x) — “there exists some x satisfying P” — as equivalent to ∀x P(x) — “all x satisfy P.” Subsequent layers refine the inferential consequences of the universal claim. Distributional divergence decreases as layers align around the flawed premise. DTR registers deep stabilization. The proof remains invalid because the invariant governing quantifier scope was violated at inception, and no depth-wise convergence process can detect or repair that violation.
Legal reasoning exhibits the same failure mode. Suppose a model misclassifies jurisdictional authority in the first stages of an analysis — attributing controlling precedent from one circuit to a dispute governed by another. Deeper layers refine the rhetorical consequences of the argument and sharpen the inferential structure under the incorrect classification. Turbulence subsides. Distribution stabilizes. The argument remains structurally inadmissible because the controlling authority was misapplied at the point of initial classification.
These counter-cases do not refute DTR’s empirical utility on competition-level math benchmarks. They establish its boundary. A reasoning system is structurally equivariant if its conclusions transform consistently when its inputs are structurally transformed — if rotating a geometry problem, substituting equivalent legal authorities, or rephrasing a premise in logically equivalent form leaves the output structurally intact. DTR cannot test this property because it measures how deeply the model revised, not whether the revision preserved the structural relationships the task requires. A system can undergo sustained layer-wise computation and still fail equivariance because the revision converged around a structurally inconsistent premise. Google DeepMind, Filter Equivariance, and Institutional Extrapolation (MindCast AI, Jul 2025) examines this constraint in detail for readers interested in the full equivariance framework.
Benchmark correlation therefore cannot substitute for invariant verification. The deeper issue is that controlled benchmarks — including AIME, HMMT, and GPQA — are single-domain, closed-form problems with determinate correct answers. Real institutional reasoning operates under multi-constraint equilibria: environments where legal authority, economic incentives, procedural rules, and factual records impose simultaneous constraints that must all be satisfied for a conclusion to be valid. A model may achieve high DTR and high accuracy on competition math while systematically mishandling problems where multiple constraint types interact. From Theory-of-Mind Benchmarks to Institutional Behavior (MindCast AI, Sep 2025) documents this generalization gap in detail — showing how symbolic reasoning gains on structured benchmarks fail to transfer when problems require satisfying simultaneous, heterogeneous constraint systems. DTR inherits that same boundary condition: its benchmark validation does not certify performance in multi-constraint domains.
IV. Stabilized Confusion and the Trust Layer
Causal reasoning requires elimination of invalid premise paths. Transformer depth frequently sharpens probability mass around a position without reconstructing the underlying causal spine. Internal convergence can intensify confidence around a flawed premise rather than expose it.
Construct a reasoning path in which the model incorrectly infers P → Q from ambiguous evidence. Later layers prune alternative continuations and amplify the downstream consequences of Q. Jensen–Shannon divergence collapses as distributions align across layers. DTR records deep engagement. The model converges coherently on error. This is stabilized confusion: turbulence subsides without invariant correction. The system achieves internal consistency around a structurally invalid premise, and revision energy amplifies the misclassification rather than correcting it.
Stabilized confusion is not an edge case. It is the failure mode that depth-only metrics structurally cannot detect, because those metrics measure the extent of revision, not the validity of what the revision converges upon.
This is precisely the gap that a trust layer is designed to close. Defeating Nondeterminism: Building the Trust Layer for Predictive Cognitive AI (MindCast AI, Sep 2025) argued that probabilistic convergence cannot substitute for deterministic constraint gating. A trust layer enforces invariant validation independently of internal turbulence. DTR measures how intensely the model revised. A trust layer determines whether the reasoning spine that emerged from that revision is structurally admissible.
V. Selection Versus Governance
Think@n improves inference efficiency through reactive selection. High-DTR prefixes survive early evaluation; low-DTR trajectories terminate before consuming full inference budgets. Across Table 2, Think@n consistently matches or exceeds standard self-consistency accuracy while reducing inference cost by approximately 50%. Pareto improvement over self-consistency is genuine and meaningful.
Selection, however, optimizes outputs after partial generation has already occurred. Governance shapes reasoning dynamics during generation. A structurally flawed but high-turbulence prefix may survive Think@n selection because the probabilistic correlation between turbulence and correctness is strong but not invariant. When the failure mode is stabilized confusion — deep internal revision converging on an incorrect structural premise — the DTR signal is high precisely when the trajectory is invalid.
To make this concrete: a model that misclassifies a quantifier in its first 50 tokens and then reasons with great computational intensity from that misclassification will produce a high-DTR prefix. Think@n selects it. The selection mechanism has no instrument to distinguish deep correct reasoning from deep incorrect reasoning rooted in an early structural error.
The absence of constraint verification is not a gap unique to Think@n. It reflects an architectural choice visible across current inference-time scaling research: systems optimize for generating and selecting among outputs, but do not include a layer that independently tests whether the selected output satisfies the structural requirements of the problem. Compute gating controls how much revision occurs. Constraint verification controls whether the result of that revision is admissible. Equilibrium termination controls when the reasoning process should stop. These three functions are logically independent — improvements to any one do not automatically improve the others. The Predictive Cognitive AI Infrastructure Revolution (MindCast AI, Jul 2025) develops this layered architecture in full. Think@n strengthens compute gating. What remains absent in the DTR framework is constraint verification — the mechanism that evaluates whether what the computation produced satisfies structural admissibility conditions.
VI. Toward an Integrated Architecture
Reliable reasoning systems require three non-redundant mechanisms, and each presupposes the one before it.
Depth-aware compute gating prevents premature stabilization. It allocates sufficient internal revision to tokens requiring extended computation and identifies trajectories that may be terminating too early. DTR provides a strong foundation for this layer. Think@n applies it effectively at the selection phase.
Structural constraint verification evaluates invariant satisfaction independently of turbulence metrics. It tests whether the reasoning trajectory preserved the governing constraints of the task — quantifier scope, jurisdictional authority, causal directionality, conservation laws. Without this layer, compute gating selects among trajectories without knowing which ones satisfy the problem’s structural conditions.
Equilibrium-based termination halts reasoning when closure conditions are met, rather than when revision energy merely declines. Overthinking occurs when revision continues past the point of constraint satisfaction. Undertermination occurs when revision stops before invariants are verified. A principled termination condition requires both the depth signal DTR provides and the structural validation that DTR does not.
Each layer addresses a distinct pathology, and each presupposes the one before it.
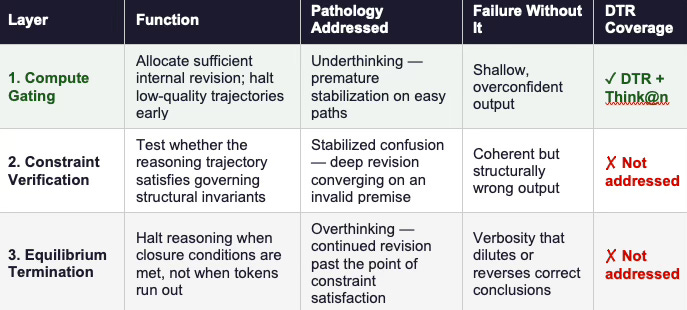
Table 2 — Three-layer architecture for reliable reasoning systems. DTR and Think@n address Layer 1 only. Layers 2 and 3 remain open engineering problems.
The broader principle is this: generative expansion — producing longer chains, more samples, deeper revision — cannot substitute for structural governance. Structural governance means that reasoning systems operate under explicit, verifiable rules about what constitutes a valid reasoning path, not merely efficient or fluent output. A system that generates confidently and revises deeply but cannot verify whether its output satisfies the governing constraints of the task is powerful but not reliable. DTR is a significant step toward making inference-time computation principled. The remaining steps require building verification and termination layers that evaluate structural admissibility independently of how much computation a trajectory consumed. The Next Generation of AI is Predictive Cognitive Intelligence and The Rise of Predictive Cognitive AI(MindCast AI, Jul 2025) develop this governance architecture in full for readers who want the extended framework. DTR advances the compute gating layer. Structural integration defines the frontier it points toward.
Conclusion
Deep-Thinking Ratio represents a substantive advance in inference-time evaluation. Internal layer stabilization captures computational refinement more faithfully than token volume, and the strong positive correlations with accuracy across multiple model families and benchmarks demonstrate that this signal is real and robust. Think@n demonstrates that turbulence signals can improve efficiency at scale, achieving Pareto-optimal accuracy-cost trade-offs that standard self-consistency cannot match.
Layer turbulence cannot certify structural reasoning. The paper’s own Appendix B documents dissociation between DTR and accuracy under reasoning-mode shifts. Formal counter-cases demonstrate that late stabilization can coexist with invariant violation, and that the failure mode of stabilized confusion — deep revision converging on a structurally invalid premise — is precisely the failure mode that depth-only metrics are least equipped to detect.
Architectural intelligence requires integration. Compute gating must operate alongside structural constraint verification and principled equilibrium-based termination. Each layer addresses a pathology the others cannot reach. Sustainable progress in reasoning systems will emerge not from thinking longer, not from thinking deeper alone, but from thinking within governed structure.
Intelligence scales when internal motion resolves into invariant coherence.