MCAI Innovation Vision: The Inference Control Layer— Capability Detection, the Routing Tax, Inference Arbitrage, the Loyal-Mercenary Split, and OpenAI's Structural Exposure at the Routing Layer
MindCast AI Inference Series: Falsifiable Foresight for Investors, Hyperscalers, Frontier-Model Providers, and Enterprise Procurement

Related works: How Structured Reasoning Becomes LLM-Executable Infrastructure — A Field Test of MindCast AI in Google AI Mode | The Inference Economy— How the TPU Bifurcation Repriced the AI Compute Stack
Executive Summary
Inference has become a routing problem. Systems no longer choose a model. Systems decide which model should think — at each query, under constraints of cost, latency, accuracy, and risk that interact at runtime rather than at procurement.
The shift reorganizes where economic value lives across the AI stack. Capability detection controls routing. Routing controls inference. Inference controls value capture. Whichever layer governs the chain prices every layer above and below it — and the governing layer is no longer the model.
Google’s TPU 8t/8i bifurcation validated the shift in hardware. Splitting silicon into training-optimized and inference-optimized substrates amounts to a routing decision elevated from software middleware into physical infrastructure, extending the silicon-layer analysis developed in The Inference Economy — How the TPU Bifurcation Repriced the AI Compute Stack into the routing-layer thesis advanced here.
Three structural consequences follow. First, the Routing Tax — unit economic divergence between high-capability and low-capability models breaks model-provider R&D amortization once routing layers swap defaults at scale, with seat pricing collapsing into utility metering as the business-model consequence. The Routing Tax viewed from the opposite side of the trade is inference arbitrage: the routing layer captures the spread between frontier-model pricing and small-model pricing on workloads where the small model is functionally sufficient. The two names describe the same mechanism — what frontier providers pay, the routing layer earns. Second, feedback ownership across models becomes the new moat at the cognition layer, contested between Loyal routers (hyperscaler-owned, margin-optimized for native silicon) and Mercenary routers (independent middleware, optimized for buyer outcomes). Third, the Entangled Corpus described in How Structured Reasoning Becomes LLM-Executable Infrastructure operates as a routed workload itself, closing a recursion the prior piece opened.
The non-consensus call: OpenAI’s structural exposure at the routing layer mirrors Microsoft’s structural exposure at the silicon layer. Distribution strength without routing control becomes a pricing-power liability under inference-cost compression. The Routing Tax is the mechanism.
The thesis fails if hyperscalers absorb routing into native stack closure before middleware reaches scale, if agent frameworks collapse routing into orchestration with no separate market, or if Intelligence Thresholding occurs — a single frontier model reaching capability where routing overhead exceeds the savings of cascading.
Core Thesis
Economic advantage migrates from model builders to inference controllers along a four-layer chain: capability detection controls routing, routing controls inference, inference controls value capture. Whichever system detects task complexity, estimates model fit, tracks temporal drift across model substrates, and routes cognition in real time captures disproportionate value because it owns the feedback loop pricing every other layer. Routing operates as the cognition-layer analogue to Google’s silicon stack closure: both sit at the inference layer, both reward integrated control over best-of-breed assembly, and both reprice the layers above and below them.
Inference without routing behaves as a commodity. Routing with feedback behaves as a control system. The unresolved question is whether routing consolidates inside hyperscaler stacks (Loyal architectures) or emerges as an independent control layer (Mercenary architectures). The answer determines where margin lands across the AI stack through 2028.
Reader Map: Stakeholders and Stakes
The argument advanced here carries different weight for different institutional readers. The disaggregation that follows names who needs the analysis, why the analysis matters for their specific position, and on what timeline each stakeholder needs to act.
Investors and capital allocators with AI exposure. The Routing Tax reprices the AI stack asymmetrically. Sell-side analysts covering hyperscaler stocks, buy-side funds long Nvidia or Microsoft or Alphabet, private equity evaluating AI infrastructure plays, and venture investors writing checks at the routing-middleware layer all carry positions that move when routing-share-of-inference-volume replaces training-cost-per-FLOP as the dominant valuation metric. The repricing is a 12-to-36-month event. Position before the repricing, not after.
Enterprise procurement and AI architecture leaders. CIOs, CTOs, and heads of AI at large enterprises currently negotiating frontier-model contracts at $20-to-$60 per seat face a structural transition over the next 12 to 24 months. The seat-to-utility pricing collapse is not a future risk — it is a procurement decision this fiscal year. The Loyal versus Mercenary audit determines whether the enterprise pays a margin tax to its hyperscaler or absorbs integration friction to retain routing neutrality. The architecture decision compounds: a Loyal default chosen in 2026 becomes a Loyal lock-in by 2028.
Frontier-model providers. OpenAI, Anthropic, Google’s model arm, Mistral, Cohere, and the open-weight cohort each face the Routing Tax from a different structural position. OpenAI carries the heaviest exposure because of partnership concentration on surfaces it does not own. Anthropic holds dual-hyperscaler optionality through Trainium and TPU partnerships, which softens but does not eliminate the routing-distribution problem. Google’s model arm operates inside the only fully closed stack and consequently faces routing exposure only on third-party surfaces. The piece names which provider sits where on the exposure curve and what each provider’s strategic options actually are.
Hyperscaler product and strategy leadership. Google Cloud, AWS, Azure, and Oracle each face native routing as their next competitive surface. Loyal architecture is the default for stack-closure economics, and the question for hyperscaler strategy is not whether to build it but how to ship it before middleware reaches scale. The piece supplies the falsification conditions that determine when the Loyal absorption window closes.
Routing middleware operators and agent framework builders. Martian, OpenRouter, and the agent-framework cohort (LangChain successors, native Anthropic and OpenAI agent SDKs, Microsoft Copilot SDK) compete for the Mercenary architecture surface against hyperscaler-native Loyal absorption. Their thesis is buyer pricing of routing neutrality. The piece names the trigger conditions that confirm or falsify the thesis on a 12-to-24-month timeline.
Regulators and competition authorities. DOJ Antitrust, FTC, EU competition directorates, and state AG offices now examining hyperscaler stack closure should add the routing layer to the surface they monitor. Cross-model feedback datasets emerging as named competitive assets is the next-order concentration risk. The P50 prediction — that cross-model feedback ownership becomes a regulated asset within 24 months — is a forward call regulators should track. The Loyal-Mercenary diagnostic supplies the structural framework for distinguishing routing concentration that warrants scrutiny from routing differentiation that does not.
Institutional research subscribers and policy researchers. Government and regulatory bodies, sovereign wealth funds, compliance professionals, and the institutional research community consuming MindCast analysis face a corpus-architecture question alongside the market-structure question. The Entangled Corpus argument in Section VIII names what corpus design needs to survive substrate variance, and the Corpus Routing-Resilience question becomes operational for any institution whose published reasoning needs to remain coherent across the substrates that compose against it.
I. The Forcing Event: TPU Bifurcation as Hardware-Level Routing
The Inference Economy framed the TPU 8t/8i split as cybernetic closure of the silicon stack — Google completing vertical integration from model to chip. The framing holds, and a second reading sharpens it. Google’s official announcement named the bifurcation as purpose-built for “the agentic era,” which is the company’s own acknowledgment that workload classes — not just chip generations — now require architecturally different substrates. The chip split amounts to the first explicit institutional acknowledgment that training and inference workloads need different routing targets. Google did not merely bifurcate silicon. Google bifurcated the routing target.
The economic logic only pays off if the workload routing layer matches the silicon layer. Compute-contextual routing — knowing whether a given inference request is running on mobile NPU, centralized GPU cluster, or specialized inference silicon — is the structural requirement that converts the TPU 8i economic case from theoretical advantage into delivered margin. Hardware without routing is a faster version of the same economics. Routing without hardware is software optimization without underlying physics. Together, the two operate as a single control surface.
Every workload now carries an implicit routing decision before it ever reaches a model. The decision was previously distributed across software middleware, model selection logic, and operational defaults. Google’s announcement instantiated the decision at hyperscaler scale and locked it into physical infrastructure. The routing thesis stopped being prospective and became operational.
II. Inference as Decision Infrastructure
Inference converts AI from static capability into continuous decision process. Each query represents a routing problem operating under simultaneous constraints — cost, latency, accuracy, and risk — that interact at runtime in ways procurement cannot anticipate. The buyer signing a frontier-model contract today does not know which of next month’s queries will require frontier reasoning and which will tolerate small-model output. The optimization that matters cannot be resolved at the contract — only at the query.
Selection becomes conditional rather than absolute as functional sufficiency spreads across multiple models. When the open-weight cohort, mid-tier proprietary models, and frontier models all clear the accuracy threshold for a given task class, the question stops being capability ranking and starts being task-conditional optimization. The leaderboard answers “which model is best on benchmark X.” The leaderboard does not answer “which model should handle this specific query, on this specific substrate, against this specific buyer’s cost-latency-accuracy envelope, right now.” Operational AI deployments have shifted from the first question to the second — and the second question is a runtime decision-infrastructure problem, not a procurement problem.
Agent architectures multiply the urgency. A traditional inference workload is a query cost: one user request, one model response, settled. An agent workload is a loop cost: a single user goal triggers dozens or hundreds of inference calls as the agent reasons, plans, retrieves, and acts. Each call carries its own routing decision. The economic gap between routing-optimized and routing-naive deployments compounds non-linearly with agent loop length, which is why the routing-layer question is not a 2028 concern arriving on a smooth timeline. The question is a 2026 procurement decision with 2028 consequences, and the buyers ignoring it are accumulating routing-naive infrastructure debt that the agent-deployment curve will surface as cost overruns within twelve months.
Economic value moves to the layer that governs the decision. Model providers continue competing on capability and continue capturing value at the model layer — but the share of total AI spend flowing to the model layer compresses as the decision layer intercepts more of the value stream. Routing systems compete on optimization and control. The historical assumption that capability advantage translates directly to economic advantage breaks once the decision layer sits between capability and buyer. The competitive frontier has migrated one layer up the stack, and the providers, hyperscalers, and middleware operators who continue optimizing for capability rankings will find themselves capability-rich and margin-poor by 2028.
III. The Capability Detection Problem and Temporal Drift
Routing requires real-time estimation of task complexity and model fit. The estimation is the load-bearing operation in the entire chain — capability detection controls routing the way routing controls inference, and a routing layer with poor detection is a scheduler dressed up as a control system. The detection problem is harder than benchmarking because the question is no longer which model wins generic leaderboards but which model handles the specific query at hand under the specific operating conditions, against the specific cost-latency-accuracy envelope the buyer is willing to pay.
The detection mechanics. Effective capability detection runs on four operations executing in milliseconds before the model itself is invoked.
Task classification analyzes the inbound query against features that predict routing fit: reasoning depth (single-step lookup versus multi-step inference), domain specificity (general knowledge versus specialized vocabulary), context length (whether the query fits within smaller models’ working memory), hallucination risk (whether the task tolerates approximate answers or requires factual precision), and latency tolerance (whether the buyer values throughput or wall-clock response).
Capability matrices maintain live performance scores tracking which model-substrate combinations are currently winning at each task class — not last quarter’s leaderboard, last hour’s measurement.
Probe layers issue lightweight diagnostic prompts when classification confidence falls below threshold, sampling actual model behavior on a representative slice of the query before routing the full workload — a runtime adaptation of the speculative decoding primitive in which a smaller model guides commitment of a larger one.
Confidence gates determine whether a low-cost model’s output passes acceptance criteria or escalates to higher-capability models — and the gate threshold is itself a buyer-tunable parameter, not a hard-coded value.
The cascade architecture as a whole has academic foundation in Stanford’s FrugalGPT work, which demonstrated empirically that cascading queries from cheap to expensive models with confidence-based escalation matches frontier-model accuracy at a fraction of frontier-model cost. Google’s Think@n protocol, analyzed in MindCast’s Deep-Thinking Ratio review, extended the pattern to inference-time compute gating — ranking partial generations by early stabilization signals and halting low-quality trajectories, with reported 50 percent inference-cost reduction at preserved benchmark accuracy. The routing layer operationalizes both patterns at production scale.
The hard part is not building any one of these components. The hard part is keeping all four of them calibrated as the underlying models change.
The agent-loop structure also changes the strategic logic of the routing decision itself. A single-query workload is a one-shot interaction between buyer and routing layer — the buyer commits, the layer routes, the trade settles. An agent workload is a repeated game: the same buyer's queries flow through the same routing layer hundreds of times per session and millions of times per quarter, and the routing layer's behavior across those queries becomes observable, auditable, and strategic. Routing layers that extract margin aggressively in single-query contexts face buyer learning and substitution in repeated-game contexts. Routing layers that build buyer trust through transparency capture the loop-cost volume that single-query economics cannot price. The repeated-game structure favors Mercenary architectures on long agent loops and Loyal architectures only on workloads short enough that buyer learning never accumulates — which is another way of saying that the agent-deployment curve structurally favors routing-neutrality buyers over routing-captive ones.
Temporal drift. Models are not static. They get updated, pruned, fine-tuned, quantized, and occasionally deprecated entirely. A model that handled a given task class correctly last month may fail it this month, and the failure may be silent — the model still produces fluent output, just less accurate output. A routing layer is only as good as its temporal awareness of which model-substrate combinations are currently winning at which task classes. Static capability matrices route stale and produce silent quality degradation. Live capability matrices route correctly and surface drift before it propagates downstream. Temporal awareness is the upstream constraint that distinguishes routers from schedulers — schedulers allocate resources against a fixed capability map, routers update the capability map continuously and route against the live state.
Architectural lineage. Routing-layer capability detection performs structurally the same operation as the Causal Signal Integrity (CSI) gate disclosed in the MindCast Provisional Patent Application on Multi-Agent Institutional Simulation Architecture — both filter inputs against validation thresholds before downstream resources commit. Routing operates as the runtime cognition-layer instantiation of the architectural primitive MindCast formalized at the simulation layer.
Detection accuracy plus temporal awareness defines the routing viability frontier. A routing system that nails detection but misses drift produces good decisions on stale information. A routing system that tracks drift but misses detection produces fast updates on bad classification. Both fail the same way: the routing layer underneath them collapses back into a scheduler.
Contact mcai@mindcast-ai.com to partner with us on Predictive Law and Behavioral Economics + Game Theory Foresight Simulations. To deep dive on MindCast upload the URL of this publication into any LLM (preferably ChatGPT or Gemini for magazine style works) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
About MindCast AI
MindCast is a predictive behavioral economics and game theory artificial intelligence firm specializing in complex litigation, geopolitical risk intelligence, and innovation ecosystems. MindCast publishes falsifiable institutional foresight analysis at mindcast-ai.com.
IV. Architecture of Runtime Routing Systems: Loyal vs. Mercenary
Section III describes what capability detection does. Section IV describes how the detection layer combines with downstream routing logic into a complete runtime system — and where the architectural neutrality the technical literature assumes breaks down under economic pressure.
Cascading architectures dominate implementation. Low-cost models handle simple tasks; higher-capability models engage only on escalation. Parallel routing operates for high-stakes queries where verification outweighs cost. The detection layer feeds the cascade by classifying queries into routing tiers; the cascade executes by walking the tiers from cheapest to most capable, with each tier’s confidence gate determining whether the output is accepted or escalated. Inference becomes dynamic optimization rather than static selection.
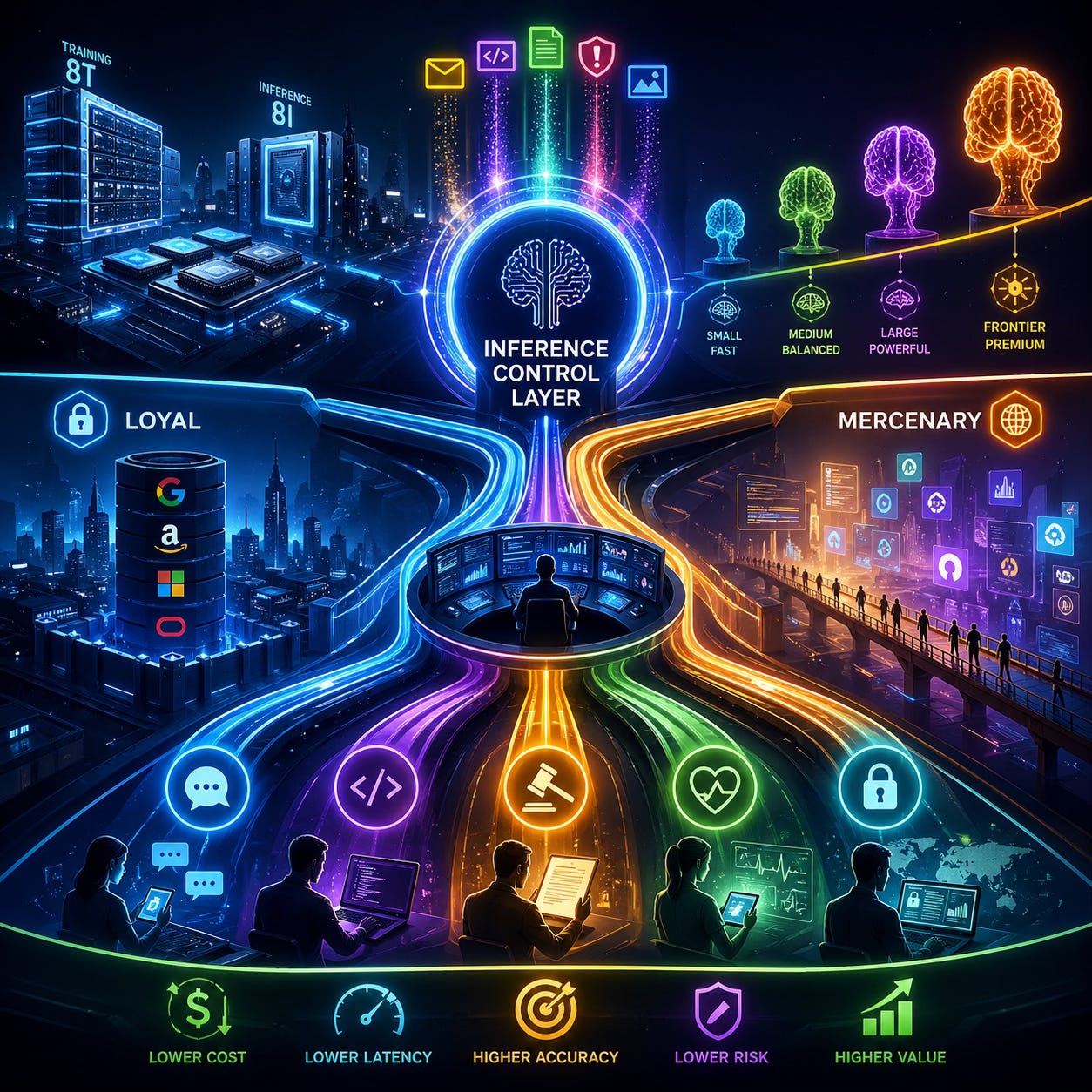
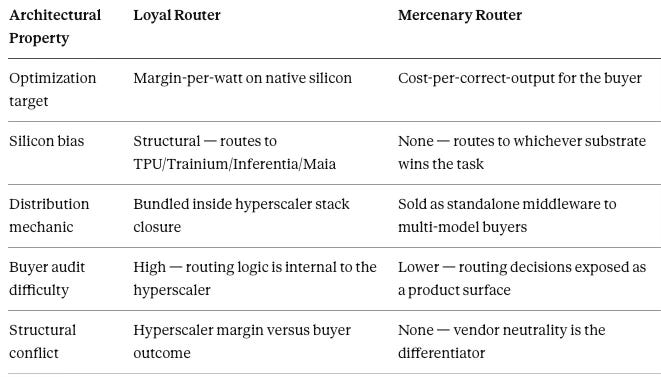
The architectural neutrality stops there. The Loyal versus Mercenary diagnostic exposes the structural conflict embedded in routing architecture itself. Routing decisions are not neutral. A hyperscaler-owned router operates as structurally Loyal — optimizing margin-per-watt on the hyperscaler’s native silicon (TPU for Google, Trainium and Inferentia for AWS, Maia for Microsoft). An independent middleware router operates as structurally Mercenary — optimizing for buyer outcome regardless of which provider’s silicon or model wins the routing decision.
The diagnostic is a conflict-of-interest audit, not a brand preference. Loyal routers prioritize margin-per-watt on native silicon; Mercenary routers prioritize token-latency and cost-per-correct-output for the buyer. Enterprises running mission-critical workloads on Loyal infrastructure must price the agency cost — the routing decision they cannot independently audit is also the cost line they cannot independently optimize.
Both architectures coexist. The share split between them determines where margin lands across the AI stack, and the question returns in Section VI.
V. Feedback Loops and Cybernetic Closure at the Cognition Layer
Routing systems improve through feedback capture across cost, latency, accuracy, and user acceptance. Feedback latency is the critical variable: faster feedback compounds advantage, and the routing system that closes the feedback loop fastest achieves superior optimization over time.
Cross-model feedback ownership defines the moat. Model providers see only their own outputs. Routing systems see comparative outcomes across providers, which is the strictly larger informational position. Whoever aggregates cross-model feedback gains the most accurate view of relative performance and prices every model in the market accordingly.
The control-theory frame developed in the MindCast Predictive Cybernetics Suite applies directly one layer up. Routing is feedback-system architecture for cognition. The suite’s runtime-versus-event distinction prices the difference between routers (which operate as continuous runtime control surfaces) and schedulers (which operate as event-triggered dispatchers). Routers govern; schedulers allocate. The economic premium accrues to governance.
The MindCast Provisional Patent Application discloses a cybernetic feedback control module that recursively modifies upstream components based on measured latency and adaptation velocity. Runtime routing instantiates the same recursive feedback architecture at the inference layer. Every routing decision generates latency and accuracy data that feeds back to update capability matrices, which is the same operation the feedback control module performs at the simulation layer. The architectural lineage runs straight from the patent disclosure to the routing-layer implementation.
Routing closes the cognition-layer feedback loop the way TPU 8t/8i closes the silicon-layer feedback loop. Every loop affecting cost, latency, and capability now runs through systems the router controls.
VI. Market Structure and Stakeholder Disaggregation
Market structure bifurcates between model providers (competing on capability) and inference controllers (competing on optimization and control). The bifurcation is a constraint-geometry shift: bottleneck control migrates from model creation to routing decisions, and the layer holding the bottleneck prices the layers it constrains.
The Loyal versus Mercenary split is a trajectory question, not an equilibrium question. The framework developed in How MindCast Evolves the Structural Gaps in Classical Nash Game Theory applies directly. Classical equilibrium analysis would describe the routing market as settling at some Nash point between Loyal and Mercenary architectures. Trajectory analysis names the structural forces determining which paths through the constraint corridor remain survivable as inference cost compresses, agent loops scale, and feedback ownership concentrates. Structure shapes the routing market; agent interaction does not choose it.
The Agency Problem of hyperscaler-owned routers makes the structural conflict concrete. When Google’s router decides between Gemini-on-TPU, Claude-on-TPU, and GPT-on-Nvidia, the decision is not neutral. The hyperscaler routes to the model-substrate combination maximizing the hyperscaler’s margin, not necessarily the buyer’s outcome. The same conflict runs through every hyperscaler-owned router: AWS routing across Claude-on-Trainium, Anthropic-on-Inferentia, and frontier alternatives carries the same structural bias toward AWS silicon margin; Microsoft routing across GPT-on-Maia, GPT-on-Nvidia, and Phi-on-edge carries the same bias toward Azure stack economics. The conflict is structural — it inheres in the architecture, not in any particular hyperscaler’s good or bad faith — and enterprises will price it.
The Agency Problem is principal-agent structure with a coordination-failure overlay. Each enterprise buyer faces individual audit costs to verify routing neutrality — engineering investment to instrument routing decisions, procurement leverage to demand routing telemetry, legal cost to negotiate routing transparency clauses. Individually rational buyers under-invest in audit because the marginal benefit accrues to the buyer alone while the cost of producing routing transparency is fixed and large. Buyers as a coalition would benefit from coordinated routing-neutrality demands that force Loyal architectures to either disclose routing decisions or lose enterprise share — but coalition formation requires coordination mechanisms that do not currently exist in enterprise AI procurement. The result is the standard game-theoretic outcome of unaddressed agency conflict under coordination failure: Loyal margin extraction persists at scale, individual buyers absorb the extraction as cost-of-doing-business, and the equilibrium holds until either a Mercenary alternative reaches credibility threshold (the trajectory path) or a regulator imposes the coordination externally (the antitrust path). Both paths surface in the timeline triggers in Section IX.
Hyperscalers hold structural advantage from integration across infrastructure, models, and distribution. Native routing ships as part of stack closure; Loyal architecture is the default. Middleware platforms compete as independent routing layers in enterprise multi-model environments, and Mercenary architecture is the differentiator. The middleware category survives if and only if buyers price routing neutrality above stack integration. Device-level control points operate as primary control points for consumer inference flows. Apple Intelligence, Android system models, and Microsoft Copilot routing each represent device-level Loyal architectures contesting the consumer surface.
Stakeholder implications follow asymmetrically and extend the Reader Map’s structural disaggregation into specific market-structure positions.
Investors should treat the routing layer as the unpriced inference-economy asset. Hyperscaler routing capability is the second-order TPU bet — current Alphabet, Microsoft, and Amazon valuations price the silicon, not the routing margin riding on top of it. Middleware operators (Martian, OpenRouter, and the agent-framework cohort) represent a binary bet on buyer pricing of neutrality, with valuation outcomes diverging dramatically depending on whether enterprises absorb Loyal margin extraction or pay middleware premiums to escape it. The leading indicator for the repricing is sell-side coverage shifting from training-cost-per-FLOP to routing-share-of-inference-volume.
Enterprise adopters face a multi-model analogue to the multi-silicon answer from The Inference Economy. The procurement question for Fortune 500 CIOs and CTOs negotiating frontier-model contracts in 2026 is no longer single-vendor versus multi-vendor — it is Loyal versus Mercenary routing architecture, and the answer compounds. Route by workload, not by vendor loyalty. Audit Loyal routers (Google’s native routing, AWS Bedrock routing, Microsoft Copilot routing) for margin extraction; audit Mercenary routers for capability staleness and integration friction. The right architecture is workload-conditional, and conditional architecture requires routing transparency the buyer can verify before signing.
Strategic buyers — sovereign wealth funds, family offices, private equity with AI-infrastructure mandates — should target feedback aggregation across models as the second-order moat. Whoever owns the cross-model performance dataset prices every model in the market, and the dataset emerges as a byproduct of routing operation rather than as a separate product. The acquisition target list for the next 24 months is not the model providers but the routing operators sitting on cross-model feedback.
VII. The Non-Consensus Call: OpenAI’s Structural Exposure and the Routing Tax
The Inference Economy named Microsoft as the structurally exposed party at the silicon layer: distribution strength dependent on a model partner whose silicon dependency points the wrong way. The routing layer carries the same structural exposure for a different provider — OpenAI, whose distribution strength now depends on consumer and enterprise surfaces increasingly controlled by routing systems OpenAI does not own. The compressed diagnostic: OpenAI is long intelligence, short control. Frontier capability without routing-layer ownership leaves the company structurally net-short the variable that prices intelligence under inference-cost compression.
The Routing Tax: Unit Economic Divergence as Pricing-Power Solvent. The mechanism is arithmetic, and the mechanism is also a trade. The historical default routes low-cognitive tasks to frontier models at frontier-model pricing. A routing layer swapping a $15-per-million-token frontier model for a $0.10-per-million-token small model on 80 percent of low-cognitive enterprise traffic represents a 150x unit-cost compression on the routed workload (the $15 and $0.10 figures reflect illustrative current API pricing levels for frontier and small-model tiers respectively; the 80-20 workload split reflects emerging enterprise telemetry rather than any specific buyer’s cost structure — the mechanism holds across reasonable variations in either input). Viewed from the model provider’s side of the trade, the spread is a tax. Viewed from the routing layer’s side, the spread is inference arbitrage — the routing layer captures the difference between what the buyer would pay at frontier pricing and what the workload actually requires at small-model pricing, on every query the small model handles correctly. The arbitrage compounds as detection accuracy improves, because better classification routes more traffic to the cheap tier without degrading buyer-perceived quality. The routing layer captures the spread, the model provider loses the revenue line, and the R&D amortization schedule justifying frontier-model investment breaks. Frontier models retain pricing power on the 20 percent of high-cognitive workloads that escalate. The volume that funded frontier R&D migrates to small-model providers and to the routing layer that captured the swap.
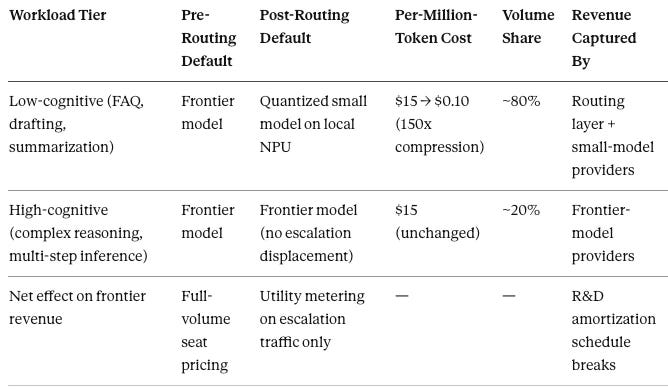
Margin Cannibalization: From Seat Pricing to Utility Pricing. The Routing Tax restructures the business model, not just the unit economics. Frontier-model revenue runs predominantly on per-seat licensing — $20 to $60 per user per month for productivity surfaces, $200-plus per user per month for enterprise tiers. Seat pricing assumes the seat is the unit of value capture: every user pays for frontier capability whether or not their queries require it. Mercenary routing breaks the assumption. Once an enterprise router determines that 80 percent of seat-driven queries route to quantized open-weight models on local NPUs at near-zero marginal cost, seat pricing collapses into pay-for-what-you-reason utility metering. The 20 percent of high-cognitive escalation traffic still prices at frontier rates. The 80 percent that does not stops generating frontier revenue. Seat pricing survives only where buyers cannot or do not deploy routing — a shrinking surface as Mercenary middleware matures and Loyal native routing ships inside hyperscaler stacks.
Mechanism propagation. As enterprise routing matures, every frontier-model output becomes one option among several in cascading architectures. The Routing Tax is paid by whichever frontier-model provider was carrying the workload before the router intervened, and the most exposed provider is whichever has the most routing-mediated distribution it does not control. On the consumer side, device-level routing defaults — Apple Intelligence, Android system-model routing, Microsoft Copilot — impose the same tax on every frontier provider whose outputs flow through surfaces those providers do not own. OpenAI carries the heaviest exposure because of partnership concentration; the mechanism applies symmetrically to Anthropic and Google on whatever surfaces they do not control directly.
Fidelity preservation as a structural requirement. The 20 percent of high-cognitive workloads that escalate require verification mechanisms preserving fidelity at routing-layer cost. MindCast’s Deep-Thinking Ratio review names the architectural distinction load-bearing here: depth-aware compute gating (the routing layer itself) is necessary but insufficient, and structural constraint verification operates as a separable layer that evaluates invariant satisfaction independently of how much computation a trajectory consumed. Selection optimizes outputs after partial generation; governance shapes what counts as admissible output in the first place. The architectural class for fidelity preservation is the governance layer — recursive verification, cryptographic attestation, ensemble checking, probe-based audit are specification-level instances of the class, and they publish separately as follow-up technical notes. The vision-layer claim is that fidelity preservation emerges as a separable market category alongside routing itself, and the buyers willing to pay for it are concentrated in law, finance, healthcare, and other domains where routing-layer errors carry asymmetric downside — precisely the domains where stabilized confusion (deep, confident, and structurally invalid output) is the failure mode buyers cannot tolerate.
The structural parallel to Microsoft is clean. Microsoft has distribution and depends on a model partner with the wrong silicon posture. OpenAI has model capability and depends on distribution surfaces with the wrong routing posture. Both pay the same kind of structural tax under inference-cost compression. The Microsoft tax is silicon-layer; the OpenAI tax is routing-layer; the mechanism is identical — pricing power compresses where control over the adjacent layer is missing.
VIII. The Recursive Close: The Entangled Corpus as Routed Workload
How Structured Reasoning Becomes LLM-Executable Infrastructure established that institutional reasoning gets executed at the inference layer through substrate composition. The piece argued that LLMs do not merely retrieve from a sufficiently structured corpus — they compose with it, executing the corpus’s frameworks against new inputs the author never addressed. The argument left one mechanism implicit, and the routing thesis surfaces it: every Entangled Corpus query is a routing decision. Substrate choice, model selection within the substrate, context window allocation, retrieval weighting — all routing.
Coherence under composition is therefore partly a routing outcome. The same corpus routed through different substrates produces different composition fidelity. A corpus optimized only for one substrate’s routing profile fragments when other substrates compose against it. A corpus optimized for routing invariance survives across substrates because the structural properties — diagnostic labels, mutual reference, falsifiability — remain legible regardless of which router weights which signal.
Structural invariance under routing variance. The deeper claim is that a properly designed Entangled Corpus is substrate-agnostic by construction. Whether a Loyal router optimizing for native-silicon margin or a Mercenary router optimizing for buyer-side cost-per-correct-output composes the corpus, the institutional reasoning the corpus encodes resolves coherently — because the structural properties survive the routing decision. The corpus is not optimized for any single substrate. The corpus is optimized for the property that no substrate can degrade it without abandoning retrieval coherence entirely. Router-resilience is the design objective; structural invariance under routing variance is the architectural condition that produces it. The MindCast Deep-Thinking Ratio review names the same condition at the model layer: invariant satisfaction is what distinguishes structural reasoning from stabilized confusion, and the same property at the corpus layer is what distinguishes substrate-agnostic composition from substrate-captured fragmentation. The corpus encodes invariants the routing layer cannot violate without surfacing the violation in retrieval failure.
The recursion closes here. MindCast reasons about the infrastructure that makes MindCast reasoning available, and the infrastructure is itself a routing problem the corpus is structurally optimized for. The corpus that argued for the inference economy is priced by the routing layer the corpus now describes. Description and instantiation collapse a second time.
IX. Forward Lock: Predictions, Timeline, Falsification
Predictions.
P70: By 2027, a majority of enterprise AI workloads route dynamically across multiple models rather than relying on a single provider.
P60: The highest-margin firms in AI operate inference orchestration platforms rather than solely building models.
P55: Device-level routing defaults become primary control points for consumer inference flows.
P50: The Loyal-Mercenary split resolves toward Loyal in the consumer surface (device-level defaults) and toward Mercenary in the enterprise surface (multi-model procurement), producing a bifurcated routing market structure rather than a single dominant architecture.
Timeline with observable triggers.
In the 6–12 month window, watch for: AWS or Azure announcing a cross-model routing API as a first-class service; the first major frontier-model API ASP disclosure showing compression on a defined low-cognitive workload tier; Apple or Google exposing routing-layer telemetry through Apple Intelligence or Android system-model APIs. Any one of the three confirms that hyperscaler native routing is shipping. All three confirm the timeline.
In the 12–24 month window, watch for: the first publicly disclosed enterprise frontier-model contract restructuring from per-seat to usage-based or tiered-by-task pricing; Mercenary middleware (Martian, OpenRouter, or successor) reaching either acquisition-grade scale or measurable enterprise displacement; a major agent framework (LangChain successor, native Anthropic, OpenAI, or Google agent SDK, or a Microsoft Copilot SDK) shipping routing as a first-class primitive rather than as configuration; consumer device-level routing defaults reaching majority share of inference volume on iOS or Android.
In the 24–36 month window, watch for: cross-model performance datasets emerging as named competitive assets in hyperscaler quarterly disclosures or M&A activity; model provider valuations repricing on routing exposure (the leading indicator is sell-side analyst coverage shifting from training-cost-per-FLOP to routing-share-of-inference-volume as the primary metric); inference orchestration market structure stabilizing into the Loyal-consumer / Mercenary-enterprise bifurcation predicted at P50.
Non-consensus falsification conditions.
The thesis fails if hyperscalers ship native routing as part of stack closure before middleware reaches scale, and the standalone routing layer never emerges as a defensible category — Loyal architectures absorb the market before Mercenary middleware reaches escape velocity. The thesis fails if agent frameworks (LangChain successors, native agent SDKs) become the de facto routing layer, collapsing routing into orchestration with no separate market. The thesis fails under Intelligence Thresholding: a single frontier model reaches a level of reasoning where the cost of routing — classification compute plus latency overhead plus capability-detection error — exceeds the savings of cascading to smaller models. Routing layer collapses into single-model selection. The Routing Tax disappears because there is no spread to capture.
Consensus falsifiers — single-model dominance, single-vendor standardization, near-zero cost and latency deltas across models — are acknowledged but de-weighted as already priced into market expectations.
The closing claim. Routing decides which intelligence runs, on which substrate, at which cost, and against which buyer’s outcome. Whichever layer makes that decision captures the margin every other layer generates and constrains every other layer’s pricing power. Inference-layer cybernetic closure has begun in silicon; closure at the routing layer is the next move, and the providers, hyperscalers, and institutional adopters who fail to position before the closure completes will price their exposure for the rest of the decade.
Convergence Note
Routing connects to the three-clock thesis developed across the MindCast convergence corpus: routing is the layer where AI × agent × verifiable-inference convergence is priced. Verifiable inference, surfaced as a strategic-buyer market in The Inference Economy, requires routing transparency. Cryptographic attestation of model outputs is impossible without routing-layer cooperation. The Loyal-Mercenary distinction reappears here: Loyal routers carry structural incentive to obscure which model handled which query; Mercenary routers carry structural incentive to disclose. The post-quantum migration timeline tightens because routing concentration creates the cryptographic attack surface verifiable inference must defend.
Related MindCast Research
The Inference Economy — How the TPU Bifurcation Repriced the AI Compute Stack — silicon-layer foundation; the TPU 8t/8i forcing event and the Microsoft structural-exposure call extended here to the routing layer.
How Structured Reasoning Becomes LLM-Executable Infrastructure — Entangled Corpus mechanism; the substrate-composition thesis closed in recursion here.
Google’s Deep-Thinking Ratio Measures Effort, Not Structure — the three-layer architecture (compute gating, constraint verification, equilibrium termination) underwriting Section VII’s fidelity preservation claim and Section VIII’s structural-invariance argument; demonstrates that depth-aware compute gating is necessary but insufficient and names governance as the missing layer.
MindCast Files Provisional Patent Application on Multi-Agent Institutional Simulation Architecture — the nine-component pipeline, CSI gate, and cybernetic feedback control module that the routing-layer architecture instantiates at runtime.
How MindCast Evolves the Structural Gaps in Classical Nash Game Theory — trajectory-replaces-equilibrium frame; the methodological basis for reading the Loyal-Mercenary market structure as a trajectory question shaped by constraint geometry rather than an equilibrium outcome of agent interaction.
MindCast Predictive Cybernetics Suite — control-theory frame underwriting Section V; the cybernetic-closure argument applied at the cognition layer is the direct extension of the suite’s feedback-system architecture.
MindCast AI Constraint Geometry and Institutional Field Dynamics — constraint geometry as the framework for identifying where bottleneck control converts into durable competitive advantage; applied throughout Section VI to read the routing layer as a constraint-geometry control point.
Forthcoming in the MindCast AI Inference Series
The structural argument advanced here opens several directions the corpus will develop in subsequent publications.
Sector applications of the Routing Tax extend the mechanism into specific enterprise domains where the unit-economic divergence between high-capability and low-capability models reorganizes existing pricing structures. Insurance Claims, Legal Discovery, and Financial Compliance each present distinct constraint geometries — each warrants a dedicated Vision piece tracing how the Routing Tax propagates through the sector’s cost structure, how Loyal versus Mercenary routing architectures reshape vendor economics, and where fidelity preservation requirements concentrate buyer willingness to pay.
Technical specifications for fidelity preservation will publish as a follow-up technical note building on the governance-layer argument in Section VII. Recursive verification protocols, the 1-token audit pattern, cryptographic attestation primitives, ensemble checking, and probe-based audit operate as specification-level instances of the architectural class named here. The note will also treat Routing Latency Budget specifications and Cognitive Registry implementation as adjacent specification-layer material.
Two commissioned engagement categories surface directly from the analysis. Router Neutrality Assessment audits Loyal routing infrastructure for margin extraction, giving enterprises an independent view of routing decisions they cannot internally verify. Corpus Routing-Resilience Audit evaluates whether an institution’s published reasoning maintains coherence across substrate variance, surfacing fragmentation risk before it propagates into compromised retrieval. Both categories accept separate intake.
A companion technical note will engage four research threads operating at specification level adjacent to the routing-layer thesis: vLLM and PagedAttention (Kwon et al., UC Berkeley) on inference serving infrastructure that routing layers run on top of; MegaBlocks (Gale et al., MIT and Stanford) on intra-model expert routing as the parallel mechanism to inter-model query routing; the DeepSeek-V3 technical report on production-scale Mixture-of-Experts routing efficiency; and Nvidia’s TensorRT-LLM stack as the hardware-aware optimization layer beneath inter-model routing decisions. Each warrants treatment the structural-level argument here does not absorb.
Competitive benchmarking against existing routing middleware — Martian, OpenRouter, and successors — will publish separately if at all. Vision-level analysis stays at structural altitude; benchmark comparison operates at a different register and serves a different reader.