

MCAI National Innovation Vision: Anthropic, Alibaba, and the Runtime Theft Problem — How Attribution Cost Moves Frontier-AI Distillation Enforcement From the Courtroom to the Statute
When Model Capability Leaks Through Interaction, the Price of Proving Who Did It Forces Enforcement Out of Private Litigation and Into Export Control, Sanctions, and Runtime Governance

Related works: Anthropic, Mythos, and the NSA, The First Sovereign Governance-Scarcity Event | The Beijing Summit Validation — Geopolitical Ripples for the AI Industry Across the Three-Layer Equilibrium | The AI Duel of America’s Chaotic Advantage vs. China’s Disciplined Coordination | The Global Innovation Trap
Anthropic accused Alibaba of the largest known distillation attack on its Claude models, telling the Senate Banking Committee in a June 10 letter that operators tied to Alibaba and its Qwen lab ran more than 28.8 million exchanges through roughly 25,000 fraudulent accounts between April 22 and June 5. Bloomberg first reported the letter, and Reuters confirmed its contents.
Anthropic did not sue first; it wrote to the Senate. The choice of forum is the load-bearing fact of the June 2026 distillation crisis. Scale is not the story; venue is. Frontier capability no longer leaks only through stolen weights, poached talent, or restricted chips. Capability now leaks through interaction, and a rival that queries a stronger model millions of times can convert the interface itself into a transfer channel.
Attribution decides the rest. Identifying the rival costs more than any private litigant can bear when the only fingerprints are tens of thousands of pseudonymous accounts resolving to operators “affiliated with” a foreign conglomerate. Attribution cost is the price of proving who did it, and it pushes the contest out of intellectual-property law and into the trade-and-sanctions machinery that only a state can run.
Congress has already named the object. Representatives Huizenga and Moolenaar introduced the Deterring American AI Model Theft Act of 2026 on April 15, weeks before the Alibaba allegation surfaced, defining a “model extraction attack” against closed-source U.S. models and routing enforcement through export controls and sanctions rather than civil suits. The statute confirms the migration this analysis traces: runtime is the new perimeter, and the wrong it polices is unauthorized extraction, not interaction itself.
I. Runtime Became the Extraction Surface, but Access Is Not the Offense
Anthropic’s own February disclosure on detecting and preventing distillation attacks had already explained the method. A weaker model trains on a stronger model’s outputs, lawful when a lab distills its own system, illicit when a competitor harvests capability it never paid to develop. Nikkei Asia called the Alibaba campaign the largest known distillation attack on Claude, and Cybersecurity News detailed its mechanics.
A precise reading of the new statute corrects a tempting overstatement. H.R. 8283 treats ordinary interface use as presumptively authorized. The bill carves out access provided through an API or other owner-controlled interface, and defines the offense as extraction conducted outside authorized training practices. Interaction alone is not the violation. Circumvention is: fraudulent identity, evasion of regional controls, and unauthorized downstream training. Anthropic’s grievance lives precisely there, in roughly 25,000 fake accounts used to defeat geographic access rules, which is why the cleaner legal characterization is access fraud rather than output theft. Framing the offense through fraudulent access also matters strategically, because output ownership and copyright theories remain unsettled while contract, unauthorized-access, and sanctions frameworks offer cleaner enforcement pathways.
The mechanism is not what broke in June. Output distillation through an interface dates to the DeepSeek and OpenAI disputes of early 2025, and Anthropic flagged the pattern itself in February. Three other things broke instead: scale, with 28.8 million exchanges roughly doubling the prior largest campaign; attribution, with Anthropic naming a major Chinese conglomerate for the first time; and the statutory response now forming around model extraction. Recasting the rupture around scale, naming, and law closes a gap a sophisticated reader would otherwise spot, since the method itself is not new.
II. Governance Scarcity Explains the Attack Better Than Theft Alone
MindCast named the economic structure before the conflict arrived. MindCast: Why AI Commoditizes Raw Prediction, Why Governance Stays Scarce argues that AI drives the marginal cost of raw prediction toward zero while the cost of governing what actors do with prediction climbs. Alibaba’s alleged operators pursued the falling-cost asset of frontier reasoning, software engineering, and agentic capability, while Anthropic absorbed the rising-cost burden of identity verification, anomaly detection, attribution, congressional escalation, and public explanation.
One correction sharpens the model rather than softening it. Anthropic carries the research-and-development loss, but the heavier governance debt lands on the public, because systems built through adversarial distillation frequently ship without the safety scaffolding engineered into the original. The extractor internalizes the capability gain and externalizes the safety cost. Governance scarcity, stated with that precision, is a transfer of liability, not merely a transfer of capability. The distinction strengthens the claim that markets reward cheap acquisition while penalizing the institutions forced to maintain boundaries.
III. Attribution Cost Is the Load-Bearing Mechanism
Attribution cost is the variable that dictates the outcome, and no prior framework in the corpus models it directly. When identifying a defendant is cheap, the injured party sues and the dispute stays civil. When identifying a defendant requires behavioral fingerprinting across tens of thousands of accounts that resolve only to affiliation rather than agency, litigation becomes economically irrational and the remedy must be socialized through the state.
Hedged language betrays the cost. Anthropic accused operators “affiliated with” Alibaba and its Qwen lab, stopping short of claiming that Alibaba’s leadership directed the campaign, because the evidentiary chain runs through inference. At least one outlet noted that the phrasing does not establish organizational involvement or prove successful replication. A disciplined reader holds two confidence levels: that a large coordinated campaign occurred (~85%), and that Alibaba-as-orchestrator is the correct attribution rather than brokers or third parties exploiting its ecosystem (~50%). The arithmetic gap between those numbers is the attribution cost, and the gap explains why the matter sits in a Senate inbox instead of a docket.
H.R. 8283 reads as an attempt to lower that cost by statute. The bill assigns two federal agencies, Commerce and State, the job of identifying foreign entities that extract technical characteristics for replicating or improving rival models, and it defines a “country of concern” that names the People’s Republic of China explicitly. Alibaba’s fact pattern, PRC-headquartered and accused of model extraction, would fall directly inside the bill’s machinery if enacted. Government proposes to absorb the attribution and enforcement burden that no private plaintiff can carry, which is exactly the socialization the economics predict.
Contact mcai@mindcast-ai.com to partner with us on Cybernetic Predictive Game Theory AI in Law and Behavioral Economics. To deep dive on MindCast works upload the URL of this publication into any LLM (Google AI mode/Gemini, Claude, ChatGPT) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
MindCast: Agent Governance Equilibrium asks whether governance capacity can scale alongside autonomous, high-velocity behavior, expressed as AGE = (A × V × C) / (G × R). A formula earns its keep only when it ranks something the headline does not already supply, so populating it across Anthropic's four disclosed campaigns turns a label into an ordering:
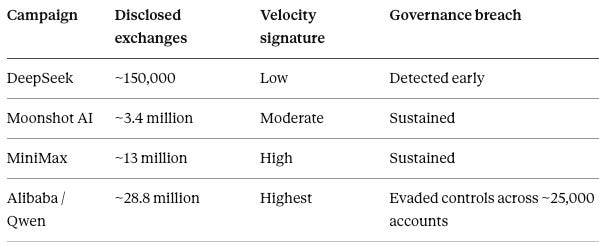
Figures for the first three campaigns come from Anthropic’s February 2026 disclosures; the Alibaba figures come from the June letter as reported by CNBC. Reading down the velocity column shows the formula doing real work. Each successive campaign raised operational velocity faster than detection and review thresholds could scale, and the Alibaba campaign marks the point where automated extraction fully outran the governance denominator. “Largest known” is a self-referential claim bounded by Anthropic’s own detection, roughly double the MiniMax figure, and the equilibrium it traces degrades campaign over campaign. The degradation, not the single record number, is the alarming signal: a stronger model raises the value of every query to an attacker, so model improvement increases extraction pressure and governance burden at the same time.
V. The Mythos Precedent and the Two Missing Units of Account
MindCast: Anthropic, Mythos, and the NSA treated frontier capability outrunning its governing instruments as a sovereign governance-scarcity event, and the Alibaba allegation extends that logic from deployment risk to extraction risk. Mythos asked whether state institutions can grade frontier capability quickly enough; Alibaba asks whether a lab can restrict foreign capability transfer when the transfer occurs through interaction rather than shipment.
Two “missing units of account” now sit in the corpus, and reconciling them prevents an apparent contradiction. Capability grading, the Mythos unit, is the measurement unit, the yardstick institutions lack for scoring how powerful a model is. Runtime control, the unit this crisis surfaces, is the enforcement unit, the metric for who may query a model, how often, under which identity, and for what downstream purpose. The two units nest rather than compete: a regulator cannot enforce limits on capability it cannot measure, and measurement without an enforcement handle changes nothing. Naming the nesting converts two loose claims into one layered framework.
VI. Nash-Stigler Logic Explains the Strategic Incentive
MindCast: The Dual Nash-Stigler Equilibrium Architecture models the incentives, with one half of the framework load-bearing and one half best left aside. The Nash half fits cleanly: a rational competitor under weak expected penalties keeps extracting until marginal cost exceeds marginal gain, while a rational lab hardens the boundary only after extraction signals grow large enough to justify aggressive restriction. The equilibrium therefore rewards early over-extraction and late over-correction, and Alibaba’s alleged campaign matches the pattern. The Stiglerian capture half does not apply, because no regulator is being captured by its industry here. Stigler’s economics of enforcement and information cost do apply, because cross-border attribution lag and evidentiary uncertainty lower the attacker’s expected penalty toward zero.
Voluntary norms will underperform for a reason the lens predicts. The actor with the strongest incentive to extract does not internalize the full cost of capability leakage, and the lab cannot price that externality through ordinary subscription controls. Government enters because the market cannot settle the dispute at the correct scale. The attribution-cost mechanism reaches the same conclusion by a different route, which is why both belong in the same paper.
VII. The Statutory Layer: From Regulated Object to Regulated Pattern
The statutory response has already entered the record, and its architecture shows where policy is heading. The CBO estimate for H.R. 8283 describes a bill that would require agencies to identify foreign entities illicitly accessing technical characteristics of U.S. models to replicate, train, or improve a rival, and would subject those entities to export controls and sanctions. Congress is no longer protecting only chips and weights; Congress is moving to protect characteristics that can be accessed, inferred, or reproduced through interaction.
A second design choice deserves emphasis because it aligns with Section I. By carving out authorized API use and targeting extraction outside authorized training practices, the bill regulates a pattern of behavior rather than a thing. Export controls have always policed objects: a chip, a file, a download. Runtime distillation presents nothing object-like until the pattern reveals strategic intent across millions of ordinary-looking interactions. The likely next layer follows from the same logic: suspicious-volume reporting, identity-gated frontier access, cross-provider threat indicators, and sanctions keyed to model-output extraction. The regulated unit becomes the pattern, and behavioral telemetry becomes a policy asset.
VIII. The Two-Front Bind
Timing does not prove motive, but timing shapes audience. Anthropic asked Washington for protection at the worst possible moment for the ask. The company petitioned for enforcement help on June 10; on June 12, the Commerce Department restricted Anthropic’s own Mythos and Fable models, forcing a global shutdown of access over fears of military-intelligence use abroad. Anthropic now seeks selective enforcement against foreign extraction while resisting selective restriction of its own exports by the same administration. Observers noted that the posture may not find a fully receptive audience.
Timing rewards a second reading (~70%). The accusation surfaced the same week Alibaba sued the Defense Department to escape its Chinese-military-companies designation, and it arrived as Anthropic prepared a confidential IPO at a reported $965 billion valuation following a $65 billion Series H. Naming a Chinese giant serves a dual narrative for a pre-listing company: capabilities valuable enough to be stolen, paired with a disclosed competitive risk from cheap imitators. Detection of the campaign is almost certainly genuine; the packaging and venue are shaped by the listing calendar and the parallel export fight. Both readings can hold at once.
IX. The MindCast AI Proprietary Cognitive Digital Twin Foresight Simulation
The preceding analysis is not freehand commentary. Each finding above is the narrative rendering of a structured run on the MindCast AI Proprietary Cognitive Digital Twin Foresight Simulation, which decomposes the event into seven foresight flows, each scoring a distinct enforcement, governance, or strategic layer of the same crisis. Scores below are calibrated analytical bands rather than empirical measurements, and every flow corresponds to a section of this piece.
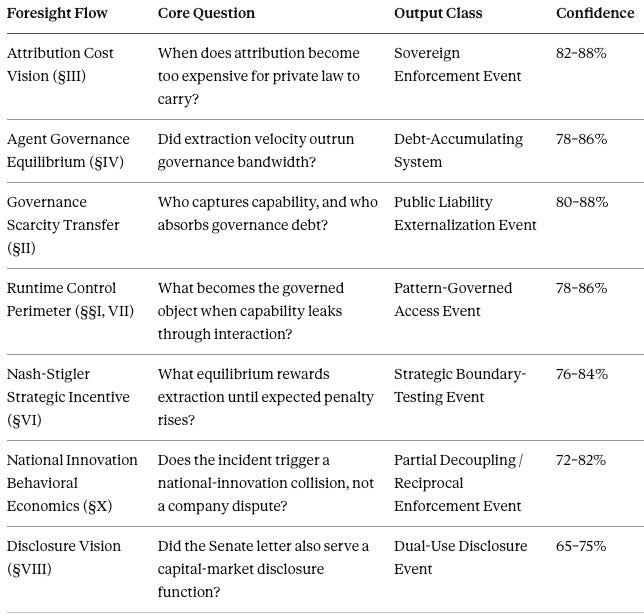
The seven flows converge rather than diverge. Attribution Cost Vision dominates the stack: proof cost, not legal theory, decides where the remedy lives. Agent Governance Equilibrium, Governance Scarcity Transfer, and Runtime Control Perimeter form the primary supporting layer: velocity outrunning bandwidth, liability transferring to the public, and the regulated object shifting from thing to pattern. Nash-Stigler and National Innovation Behavioral Economics supply the strategic overlay, explaining why rational actors test the boundary and how a company grievance escalates into a two-board geopolitical collision. Disclosure Vision stays optional and secondary, because timing shapes audience without proving motive.
The classification is singular. The crisis registers as a Sovereign Runtime Enforcement Event: dominant flow Attribution Cost Vision; primary supporting flows Agent Governance Equilibrium, Governance Scarcity Transfer, and Runtime Control Perimeter; strategic overlay Nash-Stigler and National Innovation Behavioral Economics; optional overlay Disclosure Vision. The most likely path runs from regulatory migration into sovereign enforcement toward partial sectoral decoupling, at a composite confidence of 78–86%. The forecast that follows operationalizes that path across both boards.
X. Forecast Ledger: Two Boards, One Game
The United States and China are not running the same playbook, so each responds on a different axis. Washington treats extraction as theft requiring an enforcement apparatus, which routes its moves through statute, sanctions, and runtime governance. Beijing treats open-model diffusion, low-cost refinement, and ecosystem expansion as core competitive loops, a strategy MindCast’s Beijing Summit analysis traced when Beijing refused superior US chips to force domestic-ecosystem maturation, choosing national optimization over local optimization. Qwen anchors the largest open-weight ecosystem on Hugging Face, with over 100,000 derivatives, so illicit-extraction allegations are easy for China to recast as protectionist overreach when they land against that broader open-source strategy. The forecast therefore splits across three boards: U.S. enforcement, China response, and the collision between them.
United States
US-1: Federal policy enacts a runtime-access governance framework rather than merely proposing one: identity gating, suspicious-querying detection, output-extraction penalties, and cross-provider reporting. H.R. 8283 already supplies the template, so the open question is enactment, not emergence. Probability band: 70–80% within eighteen months.
US-2: Treasury or Commerce designates specific Qwen- or Alibaba-linked entities, but the move lags, because Anthropic has not published its attribution methodology and account-level forensics are the weak link. Probability band: 45–55% within twelve months.
US-3: Frontier labs formalize distillation-indicator sharing, moving from voluntary warning to operational necessity, because an attack on one provider predicts attacks on all. Probability band: 76–84%.
US-4: The two-front bind tightens. Government keeps conditioning its help on assurance that the labs are not themselves the leakage vector, and the Fable and Mythos suspension signaled officials are not yet satisfied on that point, so Anthropic’s ask and its export grievance stay coupled through its IPO window. Probability band: 72–78%.
China
CN-1: Alibaba denies or reframes rather than admits, and likely contests any US designation in court. The company already sued the Defense Department over its military-companies listing, showing willingness to litigate designations and exploit the attribution-evidence gap. Silence converts to legal challenge. Probability band: 75–85%.
CN-2: Beijing folds the accusation into its AI-sovereignty narrative, casting US enforcement as protectionism, consistent with the March 2026 Five-Year Plan that frames AI as national security and an open-source offensive aimed at cost-sensitive Global South markets. Probability band: 78–86%.
CN-3: China answers a US extraction sanction with reciprocal designations rather than rhetoric. The retaliation apparatus is already armed and firing. The April 7, 2026 counter-extraterritoriality and supply-chain regulations took effect immediately, and on June 22 Beijing added ten US firms to its export-control list in direct retaliation for earlier US restrictions. Use is conditional on a US first move, which widens the band. Probability band: 55–65%.
CN-4: Chinese labs harden against attribution by rotating access, routing through intermediaries, and using third-party brokers, raising the very attribution cost that already governs the remedy. Detection grows harder, not easier. Probability band: 70–80%.
The Collision
CO-1: The attribution-evidence gap, not the legal theory, becomes the central battleground. Control of the forensic narrative decides the politics regardless of what occurred, pitting Anthropic’s undisclosed methodology against Beijing’s “independent innovation” framing. Probability band: ~80%.
CO-2: Hard decoupling stays partial because it is expensive. A U.S.-China Economic and Security Review Commission report cites an Andreessen Horowitz partner’s rough estimate that roughly 80% of US startups build derivative applications on Chinese base models, so procurement bifurcates by sector: defense, critical infrastructure, and cyber-adjacent workflows decouple while cost-sensitive general use does not. Probability band: ~65%.
CO-3: Escalation runs pre-loaded. Because China’s reciprocal instruments already exist and have already been used, the first US extraction sanction on a major Chinese lab triggers a faster tit-for-tat than the chip-control cycle did, compressing the response window. Probability band: 55–62%.
XI. Conclusion: Capability Control Has Entered the Runtime Layer
Anthropic’s accusation should not read as a one-off dispute between two companies. The episode signals a control-layer migration: frontier capability travels through interaction, so access governance has become part of the security perimeter, and the cost of proving who extracted what determines whether enforcement stays private or turns sovereign. The old sovereignty debate centered on compute, chips, talent, and weights; the new debate adds runtime access, and a state or firm that cannot govern model interaction cannot fully control model capability. The interface has become infrastructure.
MindCast’s governance-scarcity framework anticipated the shape of the problem, and the attribution-cost mechanism explains its destination. Prediction grows cheap. Capability moves fast. Governance stays costly. Where attribution is dear and defendants are pseudonymous, governance gets nationalized, because the state is the only actor able to absorb a proof cost no private litigant can carry. The practical question for AI law now sharpens to a single line: how many interactions does it take to transfer capability, who governs the window before anyone knows the transfer happened, and how cheaply can the law learn to name the actor on the other side?
Confidence notes on the analytical (non-forecast) inferences: a large coordinated distillation campaign occurred, high (~85%); Alibaba’s leadership directed it, as opposed to affiliated operators or third parties, materially lower (~50%), and the spread between those two figures is the attribution cost the piece theorizes; venue and timing reflect Anthropic’s IPO and export-control posture, moderate-to-high (~70%); the runtime-extraction surface, not the distillation mechanism, is what newly broke, high (~75%). Campaign figures and dates rest on Anthropic’s disclosures and contemporaneous reporting; Alibaba has not responded to the allegations, and statutory references describe an introduced bill, not enacted law.
