

MCAI Innovation Vision: Why AI Commoditizes Raw Prediction, Why Governance Stays Scarce, and How MindCast Prices the Gap Between Them
Governance Scarcity: The AI Economy's Missing Unit of Account

Executive Summary
AI will always give you an answer, but it is mostly ill-suited to tell you whether to act on it. As the cost of producing an answer gets cheaper, the cost of deciding whether to act on it goes up. Predicting what a system will do is collapsing in cost. Governing what it does is expanding to unforeseeable cost. Durable value migrates to whoever prices the widening distance between them, and pricing that distance is what MindCast does.
In brief:
The shift — AI makes raw prediction nearly free, while governing what gets done with it stays expensive, and the gap between the two widens with every gain in capability.
The consequence — value moves to whoever can measure and price that gap, a quantity the paper names governance scarcity.
The firm — MindCast prices governance scarcity, closer to Moody’s pricing credit risk than to a forecasting shop; it predicts on the record only as proof the instrument works, not as the product it sells.
Why now — every institution deploying autonomous AI is accumulating unpriced governance debt, and the firms that learn to measure it first hold the scarce side of the AI economy.
Three human capabilities, all older than the computer, carry the whole argument. People have always tried to see what is coming, to understand why it is coming, and to keep power answerable once it acts. Naming the three plainly is the fastest way in.
Prediction comes first — estimating what happens next. Oracles read entrails, almanacs forecast harvests, insurers built actuarial tables, meteorologists modeled storms, pollsters counted likely voters. Prediction is ancient, and its cost has fallen for centuries as tools improved. Artificial intelligence is the latest and steepest drop in a long decline, not the start of one.
Foresight comes second, and foresight is not prediction, though the words get swapped. Prediction estimates the outcome. Foresight understands the machinery that produces outcomes — why a system moves, when it settles, and what would have to be true for the forecast to fail. A weather app predicts rain. A seasoned forecaster who names which pressure system to watch, and what would break the forecast, does the harder and rarer thing. Generals, analysts, and strategists practiced foresight by hand for centuries, and foresight never went cheap, because understanding causes resists automation in a way pattern-matching does not.
Governance comes third — overseeing action and holding it to its purpose. Strip governance to its function, and one definition travels across every domain: a check, sitting outside the actor, that keeps the actor true to its purpose. A court holds a company to the law. A deployment policy holds a model to what it is allowed to do. A feedback loop holds a system to its target. Three different scenes, one function. Governance is the oldest of the three capabilities and has always cost the most, for one stubborn reason. Judging whether an actor still serves its purpose requires a vantage point outside that actor. Nobody grades their own homework and earns trust, so governance always needs an outside eye, and an outside eye is expensive to keep.
The three line up in causal order — what will happen, why it happens, what to do about it — and each answer is harder to check from outside than the one before. Prediction is graded by the outcome, foresight by whether its explanation holds, governance by an outside party the actor cannot capture. Depth of engagement rises at each step, and gradeability falls — the single axis that separates the three and, later, explains which of them commoditizes.
Artificial intelligence changed the three at very different rates, and the unevenness is the whole argument. Prediction collapsed toward free — a machine now extrapolates the next likely word, image, or move at almost no cost. Foresight stayed scarce, because understanding causes still resists automation. Governance stayed expensive, because the outside eye cannot be removed without the point of governance dissolving. Cheap prediction, scarce foresight, floored governance — three curves pulling apart, with the space between them widening at every advance in raw capability. Prediction is the commodity. Foresight and governance are the scarce capabilities. Intelligence is the AI method that works them, which is what the firm’s name encodes: governance, foresight, and intelligence.
MindCast works the space the unevenness opens. The field races to make raw prediction cheaper, which means the field competes to own the one thing the thesis sends to zero. MindCast builds adaptive governance infrastructure instead — instruments that track a system as it changes, find where oversight is slipping behind it, and price the risk building up in the gap. Picture prediction as electricity. MindCast is not a power plant racing every other plant to the bottom of the price curve. MindCast is the grid operator that knows where the power flows, who holds the switches, and where the system fails when demand outruns governance capacity.
Four claims carry the paper, each stated here and defended below.
Markets, institutions, AI systems, organizations, and governments are converging into one kind of entity — an adaptive intelligence system — defined by three traits: it predicts, it acts on its predictions out of habit rather than re-deriving them, and it needs an outside check to stay true to its purpose. The definition draws a real boundary, not a slogan. A thermostat predicts and acts but needs no outside check, so a thermostat stays out. A government needs all three, so a government stays in.
The gap does not close, and one argument secures the conclusion against the obvious objection. A skeptic says governance will automate too, the curves will converge, and the gap will vanish. The objection fails because governance carries a cost prediction does not. An outside check cannot shrink to nothing without ceasing to be an outside check, so governance cost holds a floor while prediction cost holds none. Stated as the paper’s theorem: commodity prediction keeps getting cheaper, governance hits a floor, and the gap between them grows and stays grown.
Value flows to whoever controls the layer where predictions become actions, and the flow leaves a fingerprint MindCast has found in five fields under five names — one and the same maneuver each time, spotted independently before anyone noticed the pattern.
MindCast’s identity is the paper’s destination, stated flat and defended in Section VII: a governance, foresight, and intelligence AI firm, holding the side of the divide the theorem says grows — and running a thesis that doubles as a moat, because no competitor can copy the position without first conceding that they sell the side that commoditizes.
Reader Map
Investors and capital allocators. Capability commoditizes; the governance layer concentrates and captures the margin. Leading metrics — routing share, invocation frequency, queue position, behavioral-default depth — sit in no standard analyst model. Product-layer revenue is the lagging indicator. The investment question the paper answers: which AI companies sell the floor of their own value, and which sell the scarce side.
Corporate strategy. One diagnostic governs every line of business — does your institution close the loop between prediction and accountable action, or does another institution close it for you? The governance gap inside your own operation binds before talent or compute does.
Regulators and competition authorities. The governance layer is the enforcement surface current doctrine does not yet watch. Cross-system feedback ownership, off-docket routing, and ambient invocation each concentrate power below the layer enforcement currently reaches.
Academics. The paper advances a falsifiable theorem, a membership test for a proposed system class, and a lineage that resumes a research program the founders of cybernetics and institutional economics left unfinished. Each is offered to be argued with.
I. The Asymmetry
Two cost curves are diverging, and the distance between them is the subject of this paper. Commodity prediction — generic extrapolation of what a system does next — has collapsed in cost across a decade of falling compute prices, better models, and liquid information markets. Governance — overseeing what the system does once it acts, and holding the action to an objective — has not collapsed alongside it. The curves are separating, and the separation is accelerating.
Two meanings hide inside the word “prediction,” and separating them now prevents confusion later. Commodity prediction is the fluency any frontier model performs, and commodity prediction is what races toward zero. Governance-grade foresight is a different discipline — mechanism-first, equilibrium-grade, falsifiable — and foresight lives on the governance side, as the instrument that prices the gap and turns cheap extrapolation into accountable action. MindCast sells the second. Cheaper raw extrapolation therefore enlarges the firm rather than threatening it, because the cheaper extrapolation gets, the scarcer the discipline that governs it becomes. Every later phrase “prediction is cheap” means commodity prediction, never the foresight MindCast sells.
The three capabilities sort along a single axis, and naming it turns the distinction from three definitions into one framework: depth of causal and normative engagement. Prediction touches neither cause nor objective — it maps what tends to follow what. Foresight engages cause — why a system moves, when it settles, what would break the forecast. Governance engages both cause and objective — whether to act on the forecast, under what authority, and who answers for the result. Each step inward is harder to grade from outside, the property that decides what commoditizes.
A grading test makes the axis concrete. Prediction is graded by the outcome — the world arrives and scores it, cheaply and automatically. Foresight is graded by the explanation — whether the causal account holds, which no outcome alone can settle. Governance is graded by an outside party — whether the action served its purpose, a judgment the actor cannot certify about itself.
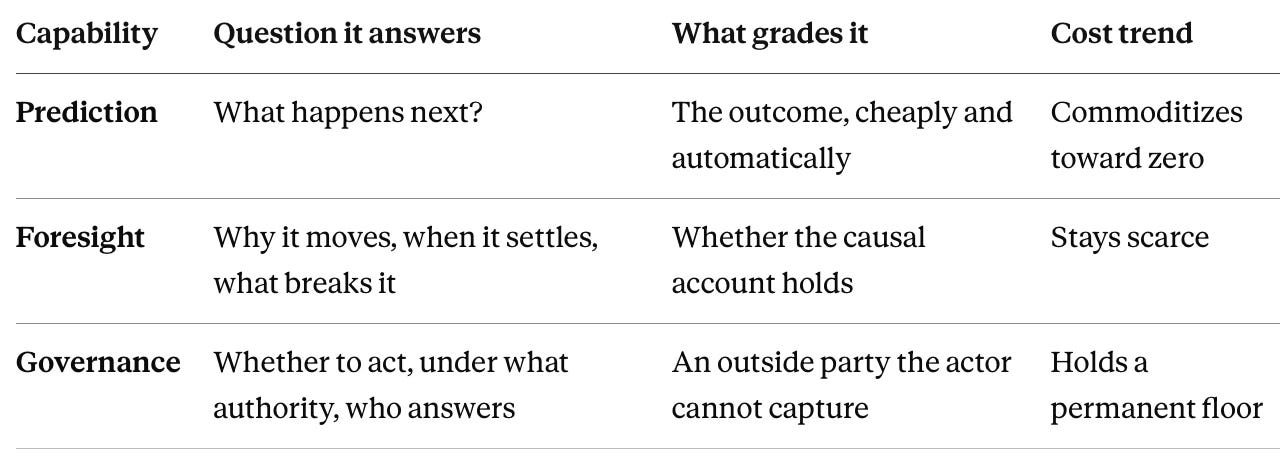
One axis generates the rest of the paper. The same ordering that separates the three capabilities produces the commoditization gradient — cheap prediction, scarce foresight, floored governance — and the external-validation floor of Section III, because the cost of grading rises at each step inward and the last step cannot be automated at all. The distinction is not asserted three times; it is derived once.
Prediction markets price reality with a precision no committee matches, and remain peripheral to the decisions they could discipline. Models draft decisions in seconds that institutions take weeks to review. Autonomous agents execute sequences of action faster than any approval chain keeps pace with. Each advance cheapens commodity extrapolation and leaves governance roughly where it stood, because the two tasks differ in kind and do not scale on one curve.
Naming the asymmetry is the first analytical move, because a gap no one measures is a gap no one manages. Institutions inside the widening distance feel it not as a clean variable but as a cluster of symptoms — settlements that change nothing, oversight that arrives after the damage, enforcement that lags the conduct, deployments no one fully supervises. The symptoms look unrelated until the asymmetry names the common cause: commodity prediction ran ahead, governance fell behind, and the space between filled with unpriced risk.
Governance takes several forms, and the paper draws on all of them, so naming the forms now keeps the narrower civics definition from quietly capping the argument. Legal and regulatory governance runs through courts, agencies, and statutes — the standard picture. Corporate governance runs through boards, auditors, and fiduciary duty. Sovereign and jurisdictional governance decides who holds authority when federal, state, and tribal claims overlap — the terrain of the Kalshi cases. Algorithmic and deployment governance decides where models are allowed, what they may do, how outputs become actions, and who carries the liability. Cybernetic governance is the root the others grow from — the feedback loop that corrects a system toward its objective.
Define governance as the correcting check that keeps a system true to its purpose, and a thermostat, a court, and a routing layer become the same function at different scales, which is what lets one theory cover all five. Algorithmic governance — the governance of AI — is one application among the five, not the parent of them. The phenomenon predates AI and exceeds it; AI is the catalyst that made it impossible to ignore, not the subject.
II. The Class — Adaptive Intelligence Systems
Markets, institutions, AI systems, organizations, and governments belong to one class, and the class earns its power only because some things fall outside it. A theory of everything explains nothing, so the convergence claim needs a boundary before it carries weight. A three-part test supplies the boundary.
Membership runs on three conditions, and a system joins the class of adaptive intelligence systems only by meeting all three. First, the system generates predictions — explicit or implicit estimates of future states. Second, the system acts on those predictions without re-deriving them each time — installing defaults, routines, or commitments that carry forward rather than recomputing from scratch. Third, the system requires an external channel to stay aligned with its objective — unable to certify from inside itself that its actions still serve the goal it was built to serve.
A thermostat shows the boundary working, which proves the test is not vacuous. A thermostat predicts temperature and acts on the prediction, yet needs no external channel, because its objective is fully specified and cannot drift — failing the third condition, staying outside the class. A prediction market sits right at the boundary: it generates forecasts but does not itself act, so it enters the class only when its prices feed back into behavior and start driving the outcomes they forecast — the shift from measurement instrument to control system that the Prediction Markets Architecture Series and Prediction Markets Reveal Truth — Feedback Loops Determine It trace in full.
Membership becomes falsifiable, and the convergence claim becomes testable rather than asserted. Markets satisfy all three once their prices steer participation. Institutions satisfy all three by definition — forecasting, installing policy that carries forward, requiring external audit to stay honest. AI systems satisfy all three the moment they act on inference without human re-derivation. Organizations and governments satisfy all three at scale. The five domains are not five subjects joined by analogy; the five are one class joined by structure, and the structure is the test. Confidence the test cleanly admits the five intended domains while excluding trivial control systems: 80–86% — the third condition does the discriminating work, and a critic can press on whether a fully specified institution escapes it, which is a productive argument to invite rather than foreclose.
III. Why the Gap Is Structural
Reconvergence is the strongest objection to the paper, and meeting it head-on is the work of this section. A skeptic grants that commodity prediction outran governance, then forecasts the catch-up: models keep improving, oversight automates, an AI supervisor watches the AI worker, the governance curve bends down to meet the prediction curve, and the gap closes. Grant the objection, and the asymmetry becomes a transitional artifact — MindCast’s positioning dissolving with it.
The objection fails on one asymmetry between the two tasks. Commodity prediction validates against outcomes — the world arrives and grades the forecast, no inside knowledge of the predictor’s objective required. Governance cannot validate the same way, because governance answers not “what will happen” but “is the action still serving the goal,” and no system answers that question about itself from inside itself. An optimizer chasing a proxy pursues the proxy past the point where it tracks the real objective — engineers call the failure reward hacking, economists call it Goodhart’s law, the alignment field calls it the agent that maximizes closed tickets whether or not customers were helped. Catching the divergence requires a vantage point outside the optimizer’s own objective. A second optimizer set to supervise the first only relocates the problem, because the supervisor now needs its own external channel, and the regress ends only at a check the system does not generate from within.
Governance therefore carries a cost floor prediction lacks, and the floor is positive and irreducible. External validation can grow cheaper — better tooling, sampled audits, escalation only on low-confidence cases — and its rate can fall toward a small number. The rate cannot reach zero without the objective going uncertified, at which point the system is no longer governed in the sense that matters. Stated as the theorem of the paper:
The Governance Gap Theorem. Commodity prediction cost falls toward zero. Governance cost falls toward a positive floor set by the external-validation requirement. The distance between the two widens monotonically and does not close.
The theorem splits into two halves, and the corpus already holds an existence proof for each. Half one — prediction collapses toward zero — is not a forecast but an event that has already happened.
Prediction markets supply the proof. Prediction markets are the cheapest prediction mechanism ever built, pricing contested futures at near the theoretical floor of what prediction can cost, and the Prediction Markets Architecture Seriesdocuments the arrival. Kalshi and Polymarket sit side by side as public belief exchanges — open contracts whose prices broadcast a crowd’s probability estimate — and both make raw prediction abundant and cheap.
Abundance is not the same as reliability, and The Full Arc of Prediction Markets shows why the distinction cuts toward the thesis rather than against it. A public market drifts as it scales: capital and narrative colonize the belief layer, accuracy degrades, and the price stops meaning what its interface claims. Cheap prediction, in other words, arrives already in need of governance — someone must classify which regime a price is in before the price can be trusted, and no actor inside the market can do it from within. Value migrates to the external layer that reads the regime. Abundant cheap prediction, scarce governance of it — the gap opening inside the prediction-market case itself.
Kalshi makes the second half concrete and current. Nobody in the sprawling litigation around these exchanges contests whether the markets predict well. Every contested question — CFTC v. New Mexico, the dozen state enforcement actions, the tribal suits under the Indian Gaming Regulatory Act — asks who governs the markets, not whether they work. Prediction is abundant; governance is unresolved across federal, state, and tribal authority at once — half one of the theorem with a case number rather than an assertion.
Governance debt supplies the other proof. Half two — governance holds above a floor and the gap compounds — is measured by Agent Governance Equilibrium, which tracks the unserviced distance as debt that accrues rather than clears. Two exhibits, one per half, equal weight: prediction markets prove the abundance, AGE proves the scarcity.
The theorem stays falsifiable, which separates it from a slogan. The theorem fails the moment anyone demonstrates a governance loop that stays aligned over time while generating its own validation entirely from within — no external channel, no drift. The AI Accountability Series develops the legal form of the same point: accountability is the name the law gives the external channel, and a system that cannot be held to account from outside cannot govern itself from inside. Confidence the floor argument defeats the reconvergence objection: 78–84% — strong because the self-validation impossibility rests on well-established results, hedged because a critic can argue the floor is small enough to be negligible in practice, an empirical fight the paper chooses to have openly rather than dodge.
Contact mcai@mindcast-ai.com to partner with us on Predictive Game Theory AI in Law and Behavioral Economics. To deep dive on MindCast works upload the URL of this publication into any LLM (preferably Google AI mode/Gemini, Claude, ChatGPT) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
MindCast AI is a cybernetic, predictive game-theory AI firm specializing in law and behavioral economics, applied to complex litigation, innovation systems, and geopolitical risk intelligence. Rather than extrapolating historical patterns, the firm models the mechanisms that generate institutional behavior, running Cognitive Digital Twin simulations grounded in Nash equilibrium, Stigler information economics, and the Chicago School of law and behavioral economics.
IV. The Mechanism — The Control Layer
Value migrates to whoever holds the layer where predictions become actions, and naming that layer drives the rest of the paper. A system that predicts cheaply and governs expensively grows a layer between the two — the layer that decides which prediction becomes which action, under which default, at which moment. Whoever holds the layer governs the system, and governance is the durable position. The model builder, the device maker, the frontier provider, the agency on the docket each wins a layer and still surrenders the system to whoever closed the loop around it.
Owning a layer differs from closing a loop. Owning a layer confers position, and position earns margin until a better offer arrives. Closing a loop confers power — routing intent through your own intelligence, returning output through your own surface, embedding the result as the default that shapes the next request — and capturing the behavioral default that decides whether a better offer ever gets invoked.
Norbert Wiener supplied the mechanism before the markets existed: adaptive systems regulate through feedback, the actor controlling the correction loop sets the default for the next cycle, and each turn reinforces the last. Ross Ashby supplied the constraint: a controller must hold at least as much variety as the system it governs, or lose governance. The Predictive Cybernetics Suite, The Cybernetic Foundations of Predictive Institutional Intelligence, and Cybernetic Game Theorydevelop the full apparatus — feedback latency, loop closure, and the migration from open-loop measurement to closed-loop control.
The Consumer AI Device Series states the principle most sharply: every technology market eventually stops competing at the product layer and starts competing at the control layer, and the institution that closed the behavioral-default loop before the contest was visible has already won. Hardware lock-in and routing lock-in differ, and the most valuable version of the wrong one is still the wrong one. Runtime Geometry gives the economic statement: a dominant actor takes the center of the market field, gates the flow, and warps a flat plane of free information into a gravity well centered on itself — the control layer rendered as topology.
V. The Arbitrage Tell — One Trade, Five Names
Arbitrage is the fingerprint a control layer leaves when it forms, and the fingerprint is the most useful diagnostic in the framework. The governing node captures the spread between what a workload is priced at and what the work actually requires. MindCast has found the identical trade in five fields, each under a local name, without yet stating that the five are one.
Inference arbitrage runs at the cognition layer. The routing system swaps a frontier model for a small model on the workloads a small model handles correctly, keeps the difference, and widens the spread as detection improves. AI Inference Arbitrage develops the mechanism and its consequence for the amortization schedules that funded frontier investment.
Advocacy arbitrage runs at the enforcement layer. A private intermediary converts political proximity into an off-docket channel that routes around the agency holding the case, and the spread between enforcement under independent authority and enforcement under the captured channel is the rent. Tirole & Advocacy Arbitrage names it; The Shadow Antitrust Division documents it across three matters, with a defendant’s stock repricing on the removal of an enforcement chief standing as the market’s real-time quote of the spread.
Three more fields run the same trade. Compute economics shows it as the routing tax. Energy infrastructure shows it as queue and access capture, where actors securing constrained interconnection before scrutiny arrives earn rents on access they gated rather than built, traced in The Power Stack. The gatekeeper’s market shows it as the information moat, where the dominant node performs arbitrage on the truth itself and installs its own logic as the system’s logic.
The five trades are one trade, and stating the equivalence is the paper’s sharpest original result. Each instance is a control node capturing a spread it created by gating a flow — the only variation is the unit the spread is denominated in: tokens, market capitalization, interconnection rents, attention. Confidence the five names describe one mechanism rather than five resembling ones: 82–88% — the formal structure is identical (Appendix A), and the corpus arrived at the same trade five separate times before noticing it had. Locate the arbitrage, and you have located the control layer, whatever the field calls it.
VI. The Accumulation — Governance Debt, and the Evidence
Unserviced gaps compound, and the accumulation carries a name. The space between commodity prediction and expensive governance fills with risk no one is pricing, and the unpriced risk accrues interest. Agent Governance Equilibrium names the accumulation governance debt and supplies the measurement: agent autonomy grows faster than the capacity to govern it, the imbalance compounds, and the debt comes due as a correction sized to how long the gap went unserviced. AGE quantifies the central variable of the paper — and appreciates as AI improves rather than depreciating, the signature of a governance instrument rather than a prediction tool.
The library sorts into four tiers by the role each piece plays, and the tiers resolve upward into the trunk. Foundational pieces supply the domain-agnostic engine and make durable claims. Applied pieces instantiate the engine in a field and make dated, falsifiable predictions, splitting into two families — one tracking control and oversight, one tracking structure and value capture. Validation pieces test the engine where the scoreboard is public. The diagram shows the stack.

Tier 1 — Foundational. The engine makes durable claims that outlast any one case, and everything above inherits them. Cybernetic Game Theory, the Predictive Cybernetics Suite, and The Cybernetic Foundations of Predictive Institutional Intelligence supply the feedback-and-control mechanism. Nash-Stigler Equilibria and the Emergent Game Theory Frameworks supply the logic that lets a simulation know when a situation has settled and when more analysis would add nothing. The geometry primitives close the tier with the topology of constrained fields. The Full Arc of Prediction Markets belongs here too, not in the applied tier, because it abstracts a domain-agnostic structure — signal hardening into belief, capital, flow, and control — that the Consumer AI Device Series then runs on device ecosystems unchanged; one arc, two unrelated domains, which is itself evidence for the universal-structure claim. Tier 1 carries the most citation weight and ages the slowest, so every claim above it depends on the tier holding without exception.
Tier 2 — Applied, Control & Governance. Feedback, oversight, and accountability instantiated in a field, each a dated and falsifiable prediction. Agent Governance Equilibrium measures the gap directly as governance debt. The AI Accountability Series supplies the legal form of the external check — accountability is the name the law gives the outside eye. The Prediction Markets Architecture Series tracks the cheapest prediction mechanism in existence sitting peripheral to the decisions it could govern until feedback loops convert its prices into control.
Tier 2 — Applied, Structure & Value-Capture. Geometry, market structure, and the migration of value to the governing layer. Runtime Geometry heads the family with the economic statement of the gated field. The Shadow Antitrust Division, with Nash-Stigler: LiveNation & Compass and Chicago School Accelerated, shows capture settling into equilibrium where correction should be. Compass’s Interpretation of “Public Marketing” carries the family’s sharpest worked example of the external check from Section IV: a national brokerage arbitrages the gap between visible and visible-on-equal-terms to defend a withheld-inventory layer the model prices at $400–800 million, and the only actors who can break the captured loop are the state attorneys general standing outside it — the outside eye made concrete, assembling a file from a record the firm built against itself.
AI Inference Arbitrage and the Consumer AI Device Series follow value migrating from the model to the routing layer and from the device to the default-setting loop. The Power Stack tracks the same migration into physical access, where actors who gate constrained interconnection early govern deployment regardless of later capital. The arbitrage tell of Section V lives in this family, so the family must stay unimpeachable: the keystone equivalence claim rests on these pieces.
Tier 3 — Validation. A match resolves on a fixed schedule with a scoreboard anyone can read, so the proving ground tests the engine in the open. Super Bowl LX — AI Simulation vs. Reality and the World Cup Championship Index carry the methodological spine — mechanism before outcome, pre-committed gates, falsification contract, documented self-correction — even where the control thesis runs faint and capability-versus-alignment is its only trace. The validation tier proves the method; the applied tiers apply it; the foundational tier explains why it works.
VII. What the Theorem Makes MindCast
MindCast is a governance, foresight, and intelligence AI firm, and the theorem defines what it competes on. The field competes on raw prediction, which the theorem sends to zero, so the field competes to own the floor of its own value. MindCast competes on the scarce side — foresight, the discipline that understands why a system moves; governance, the outside check that keeps it answerable; intelligence, the AI method that binds them.
MindCast still predicts, and predicts on the record — but its forecasts come from foresight, the graded kind that stays scarce when raw extrapolation floods the market, so the firm’s prediction work strengthens as the commodity kind cheapens rather than eroding with it. The forecast is the output; the scarce asset is the causal and governance analysis that produces it. Foresight resists commoditization for the same reason governance does — identifying the mechanism, judging when a system has settled, and pricing where oversight fails are all judgments that cannot validate themselves from inside, so they inherit the floor the theorem already set, while commodity prediction, graded cheaply against outcomes, does not.
The product is adaptive governance infrastructure: tools that watch a system as it changes, find where oversight is slipping behind it, and price the risk building up in the gap. Scholars of the commons have long used “adaptive governance” for managing complex systems under uncertainty; MindCast takes the idea and makes it measurable, turning a style of oversight into a priced quantity. MindCast is an AI firm in substrate and method, and a governance firm in the value it sells — one position, not a hedge.
The positioning doubles as a moat. A competitor cannot copy the position without first conceding the theorem, and conceding the theorem means conceding they sell the side that commoditizes. The claim and the defense are one sentence. Confidence the positioning is genuinely hard to replicate rather than merely distinctive: 72–80% — strong because the self-undermining structure is real, hedged because a well-capitalized incumbent could attempt the pivot once the category is proven, the standard fate of a first mover that names a market.
Two scenarios bound the moat, and stating both keeps it a claim rather than a boast. Lose the bet, and governance cheapens, the gap closes, foresight goes roughly equivalent across providers, most AI products collapse into commodity utilities, and MindCast becomes one forecasting shop among many — the falsification path Section XI commits to in writing. Win the bet, and raw prediction goes abundant while governance stays scarce, so the scarce assets become validation, oversight, loop closure, external accountability, and institutional foresight — none of them raw prediction, all of them the work MindCast already does. The firm that named those assets first, and built the instruments to price them, holds the high ground.
The product is more than a forecast; the product locates the gap. Anyone can forecast an election. Far fewer can name which institution captures power after it. MindCast sells both, and the second is the scarce one — where governance debt accumulates, where a control layer is forming, where arbitrage is capturing a spread, where an institution is losing oversight, where a feedback loop is turning dominant. Raw prediction is the input. The moat is identifying where prediction becomes action, where action becomes control, and where control escapes governance.
Governance scarcity is the unit of account, and naming the unit turns a one-time observation into a discipline. A gap gets noticed once. An economics carries a unit of account, a quantity every instrument reads in common — and the library, read back through the identity, turns out to be six instruments measuring one quantity.
Agent Governance Equilibrium reads governance scarcity as debt — the unserviced gap accruing interest. The AI Accountability Series reads it as liability — who bears the cost when the external check fails. The Prediction Markets Architecture Series reads it as information — what the market reveals and who acts downstream. The Cybernetics Suitereads it as feedback — whether the correction loop closes. Runtime Geometry reads it as topology — how the gated field warps. AI Inference Arbitrage reads it as rent — the spread the control layer captures. Six readings, one quantity, which is why the paper that opened as the Governance Gap arrives at governance economics: the gap is what opened, scarcity is what it is denominated in, and MindCast builds the instruments that price it.
Governance economics is the field the paper is founding, and stating the definition plainly fixes what the field studies: the creation, distribution, measurement, and pricing of governance scarcity within adaptive intelligence systems. AI is the catalyst, not the subject. Cheap commodity prediction made governance scarcity visible everywhere at once — in courts, markets, agencies, grids, and model deployments alike — but the scarcity predates the catalyst and outlasts it. A reader twenty years on, for whom frontier AI is mundane, still inherits the field, because the object of study is governance scarcity, not AI.
Governance scarcity reaches toward an asset class, not a service, which is the sharpest way to see what MindCast is building. A service sells effort. An asset class prices a quantity holders care about on its own terms. Governance scarcity already has the unit and the instruments an asset class needs, and lacks the market and the price discovery one would require — an asset class in formation rather than a finished one. Naming the destination without overclaiming the arrival is the honest position: the unit exists, the market does not yet. Confidence the asset-class framing is right in direction but premature if stated as fact: 70–78%.
The product already runs in public, on a live adversarial record, which separates a demonstrated claim from a positioning one. The prediction-markets war is the clearest case. MindCast filed a formal comment into the CFTC’s RIN 3038-AF65 rulemaking and has tracked the contest across federal, state, and tribal forums — the CFTC NPRM analysis, the national litigation map, and the CFTC v. New Mexico reading that located the tribal seam a maximal federal win cannot cross.
The fight is a routing contest in regulatory dress. Exclusive jurisdiction is a control-layer claim, and whichever authority the markets route through prices their existence and sets their rents — Section IV’s mechanism on a federal docket.
MindCast priced the fight before it resolved, with dated and falsifiable predictions carrying explicit windows, and the analysis reached the exact actors the theorem names as the only ones who can break a captured loop: state attorneys general, gaming regulators, tribal authorities, federal judges. A governance, foresight, and intelligence firm served as the outside channel, read into the record by the institutions that govern the system — no commodity forecaster does that, because pricing who governs is a governance act, not raw extrapolation. Confidence the Kalshi/CFTC record functions as the paper’s strongest proof of product rather than another exhibit: 82–88%.
Moody’s is the right comparison, not the model labs. Moody’s prices credit risk. Bloomberg prices information access. McKinsey prices strategy. MindCast prices governance risk — the one category none of them occupies and the theorem says grows.
The identity question resolves here, as a nesting rather than a choice: AI is the how, governance intelligence is the what. Nobody calls Moody’s a statistics company, though Moody’s runs on statistical models, because the method is not the category. MindCast runs on AI, the method is real and differentiating, and the category it sells into is governance risk. The firm name already encodes the nesting — intelligence is the AI method, governance and foresight are what it prices.
A commodity-model world sharpens the point. Run the same logic forward — GPT, Claude, Gemini, the open-source field flattening into rough parity — and the winner is the actor that governs deployment, not the model: where models are allowed, what they may do, how outputs become actions, who bears liability.
Electricity completes the picture. Picture prediction as the current in the wires. MindCast is the grid operator that knows where the power flows, who controls the switches, and where the system fails when demand exceeds governance capacity. Power plants compete on price per kilowatt-hour. The grid operator prices the stability of the whole system, and stability is the scarce thing.
The category is early, the one real risk, and the paper must handle it rather than hide it. Investors hold language for AI, software, prediction, and consulting, and hold no language yet for governance intelligence, so the paper may be correct before the market has words for it — the ordinary condition of a category at its creation. A flagship vision statement is where the vocabulary gets minted, so the lexicon is stated plainly:
Governance gap — the widening distance between commodity prediction and floored governance.
Governance scarcity — the unit of account; what the gap is denominated in.
Governance debt — scarcity left unserviced, accruing as a future correction.
Governance economics — the field that studies the creation, distribution, measurement, and pricing of governance scarcity within adaptive intelligence systems; the AI era is its founding case, not its boundary.
Governance intelligence — the category MindCast sells into; the priced reading of where governance is failing, forming, or escaping.
Moody’s had to teach the market what a credit rating was. Minting the lexicon now is the same work, done early on purpose.
VIII. The Instrument — Why MindCast Prices the Gap
Pricing the gap is the contribution, and one methodological discipline makes pricing possible where rivals only narrate. Rival methods describe the asymmetry after it resolves. MindCast commits a dated, falsifiable forecast before it resolves, and the discipline that allows it is a rule about when to stop.
Two conditions must both hold before a MindCast simulation commits to a call. The first is settlement — the situation has reached a point where no actor improves by breaking from it, a stopping point with meaning rather than an arbitrary cutoff, the condition Nash named. The second is sufficiency — further search would add less to the answer than it costs to run, the condition Stigler named. Settlement decides where the system lands; sufficiency decides when the analysis stops. Most institutional analysis stops at settlement alone, maps the stable strategies, and declares the system understood — missing that a system can settle on distorted inputs and lock onto the wrong answer, stable and false at once. Settlement without sufficiency is the formal signature of capture, and catching it is how the Nash-Stigler method tells genuine agreement from enforced stability.
Falsification turns the method into an instrument. Every output ships with the conditions that would prove it wrong, a probability band, and a time window, and the record tracks misses beside confirmations. The diagnostic protocol in Cybernetic Game Theory runs the read; the sports series demonstrates it where the scoreboard is public. A forecast that cannot be embarrassed by the outcome is not a forecast, and the whole MindCast apparatus is built to be embarrassable on the record — the working meaning of selling adaptive governance infrastructure rather than confidence.
IX. Measuring Governance Scarcity
A unit of account is worth only as much as the instrument that reads it, so the hardest question the paper faces comes last: do MindCast’s frameworks measure governance scarcity better than the alternatives, or only label it? Answering honestly means conceding the trap every new unit of account falls into, then showing the way out.
The Validation Problem
Bootstrapping is the trap. A new unit cannot be validated against a pre-existing ground truth, because the unit did not exist before the instrument that reads it. Moody’s could not prove a credit rating was accurate in 1909, because no independent credit-risk scale existed to check it against. Governance scarcity sits in the same position today: no rival meter predates MindCast’s, so correspondence to an established measure is not available as proof.
Moody’s escaped the trap the only way open to it, and the escape sets the standard. Moody’s showed that its ratings predicted defaults better than the methods investors already used — on a public record, repeatedly, before the outcomes were known. Validation came from falsifiable track record against rivals, not from correspondence to a truth that did not yet exist. Confidence that track-record-against-rivals is the only validation path open to a genuinely new unit of account: 80–86%.
How MindCast Meets the Standard
MindCast meets the standard at three ascending levels of strength.
Coherence is the floor. Six instruments converge on one quantity — debt, liability, information, feedback, topology, rent — each reading governance scarcity in a different form. Convergence among a firm’s own frameworks is real evidence of internal consistency and weak evidence of external truth, because agreement with oneself proves little. Coherence earns a mention, not the weight.
Comparative reading is the middle, and the Kalshi/CFTC record supplies the live instance. Conventional legal analysis tracked the state-preemption fight on its surface. MindCast’s instruments located the tribal seam a maximal federal win cannot cross, and named the gaming-characterization question as the variable both tracks secretly share. A reading of where the system actually fractures, produced before the dockets resolved, that the standard method did not surface — measurement adding information a rival method missed.
Falsifiable track record is the load-bearing claim, and the discipline Section VIII described becomes, read as evidence, the proof. Every MindCast forecast ships pre-committed: a dated prediction, a probability band, an explicit falsification condition, and a public scoring once the outcome lands. The four CFTC predictions carry windows and failure conditions. The Super Bowl work documents a mid-season revision rather than burying it. Each resolved call becomes a data point no competitor can manufacture after the fact, and the record compounds the way a ratings agency’s compounds — one scored prediction at a time.
Misses must stay visible, or the claim collapses into marketing. A measurement system that reports only its confirmations is advocacy; one that reports its error rate is an instrument. MindCast’s claim to be governance economics rather than governance advocacy rides on keeping the misses on the record beside the hits — the discipline the validation record exists to enforce.
Is Governance Scarcity a Real Unit?
One question sits beneath the measurement claim and decides whether the field endures: is governance scarcity a true unit of account — the equal of price, risk, information, or entropy — or a vivid metaphor wearing a unit’s clothes? A real unit does three things. Comparability comes first: two cases can be ranked by how much of it each carries. Additivity comes second: quantities sum. A canonical scale comes third: one measure every instrument reduces to, the way risk reduces to variance, information to bits, entropy to joules per kelvin.
Governance scarcity clears the first two and not yet the third. The six instruments already rank and sum it — the withheld-inventory layer in the Compass case and the tribal seam in the Kalshi case can be compared by the scarcity each carries, and governance debt sums by construction. What the field still lacks is the canonical scale: the single measure all six readings provably reduce to, rather than six correlated readings that plausibly track one quantity. Confidence governance scarcity is comparable and additive today: 80–85%. Confidence it has a canonical conserved scale today: 45–55%.
Every founding unit stood exactly there before it earned its scale. Merchants priced goods for centuries before economics axiomatized price. Clausius computed entropy as a ratio before Boltzmann gave it a microscopic definition. Risk was managed as an ordinal, additive quantity for decades before modern portfolio theory supplied variance. A unit gets used as comparable-and-additive long before it gets its canonical floor, and the use is what motivates the floor. Governance scarcity is a unit in formation on that path, not a finished one — and naming the missing piece is what keeps the claim a scientific bet rather than a slogan. Confidence governance scarcity matures into a full unit of account over time: 65–72%.
The track record is what carries the unit until the scale arrives, which is why the two halves of this section reinforce rather than undercut each other. A unit without its canonical measure has one way to earn belief: predict better than rivals, on the record, before the outcomes are known — the path price and risk and entropy each walked in the decades before their formal scales existed. MindCast’s falsifiable forecasts are not only evidence the instrument is calibrated; they are the stand-in for the measure the field does not yet have, the bridge that lets governance scarcity be taken seriously now rather than after the scale is built. Prediction performs that duty, which is the deepest reason the firm predicts on the record even though prediction is not the thing it sells. Confidence the track record legitimately substitutes for the missing canonical scale during the field’s formation: 76–82%.
Honesty about the present state closes the section. The paper proves governance scarcity exists, proves a field can price it, and shows MindCast measuring it better than rivals in at least one live case. Supplying the canonical scale, and proving superior measurement across every form at scale, is the frontier the track record exists to settle over time — not a claim the paper can close today, and stronger for admitting it.
X. The Lineage
MindCast resumes an unfinished research program, and naming the lineage is the paper’s final structural move. Six thinkers established that markets, machines, minds, and institutions obey common laws of information and control, and then the disciplines split apart and stopped talking.
A catalyst reveals a field, and the field outlives the catalyst — the pattern every general science has followed. The steam engine revealed thermodynamics, and thermodynamics outgrew the engine. The telephone channel revealed information theory, and information theory outgrew the wire. Industrial production revealed modern economics, and economics outgrew the factory. The AI era reveals governance economics the same way: cheap commodity prediction exposed governance scarcity at a scale impossible to ignore, and the field that studies the scarcity will outlast the catalyst that exposed it. Steam engines did not create the laws of energy; they made the laws visible. AI did not create governance scarcity; it made the scarcity unignorable.
Friedrich Hayek showed that price systems compute distributed information no central planner can assemble. Norbert Wiener showed that feedback governs machines and organisms by the same mathematics. Ross Ashby established that a controller must match the variety of what it governs. Herbert Simon showed that bounded rationality and satisficing — stopping when a solution is good enough — describe real institutional decisions better than perfect optimization. John Nash gave equilibrium its strategic meaning. Ronald Coase located the firm and the market in the costs of transacting and the failures of coordination. Each saw a piece of one structure, and the academy filed the pieces in separate departments.
The MindCast frameworks reassemble the program as one architecture. Hayek’s distributed computation and Wiener’s feedback become predictive institutional cybernetics — one account of how institutions process information and correct themselves. Ashby’s rule that a controller must match the variety of what it governs becomes the test that separates institutions able to govern a system from those merely sitting on one layer of it. Simon’s satisficing becomes the stopping rule that ends an analysis once more search would not improve the answer. Nash’s equilibrium and Coase’s costs of transacting become the engine that decides when a situation has settled, and a map of how gated markets bend around whoever controls the flow. The synthesis is not eclectic borrowing — it reassembles a structure the originals built in pieces and the twentieth century took apart.
MindCast is the claim that the pieces were always one structure, and that the structure has a name: the governance of adaptive intelligence. The library works the claim out across every field where raw prediction has outrun governance — which, more and more, is every field there is.
XI. Falsification and Forward Lock
The theory commits to its own failure conditions, because a meta-theory that cannot fail is a creed, not a framework.
The membership test fails if the three conditions admit trivial systems or exclude intended ones at scale — a thermostat qualifying, or a government not. The convergence claim falls with it.
The Governance Gap Theorem fails if anyone exhibits a governance loop that stays aligned to its objective over time with no external validation channel — self-certifying and non-drifting. Demonstrate that, and the floor is illusory, the gap can close, and MindCast’s positioning collapses with it.
The control-layer mechanism fails if value stops migrating to the governing layer — capability ceasing to commoditize, the product layer reabsorbing the margin, the routing spread collapsing to zero across fields at once. Partial closure in one field does not falsify; simultaneous closure does.
The arbitrage equivalence fails if the five named trades prove to be five mechanisms rather than one — the spread-capture structure of Appendix A not in fact holding across fields under a common form.
The methodological spine fails on its own published terms — faster convergence consistently improving accuracy, a circuit split resolving without rule mutation, high-feedback systems reducing rather than amplifying distortion.
Govern the loop, not the layer. Locate the arbitrage, and you have found the control point. Keep one validation channel outside the system, or accept that the system will certify itself — and that whoever closed the loop before the contest was visible has already won.
Forward Lock: Should governance automate fully and the cost curves reconverge, the gap closes and the theory fails. Commodity prediction is cheap. Governance is floored. MindCast is the governance, foresight, and intelligence AI firm that prices the distance — the grid operator, not the power plant.
Appendix A — The Arbitrage Equivalence, Formally
One control node C sits between a demand side D and a supply side S. The work D requests carries a true required cost c*— the minimum-capability cost that satisfies the request correctly. D pays price p, set against the high-capability tier. Croutes the work to a tier with cost c_r ≤ p, discriminating with accuracy α (the fidelity of C‘s routing) over volume V.
The control layer’s per-period rent takes one form across all fields:
Rent(C) = V · α · (p − c_r) − r · kwhere (p − c_r) is the spread, V · α is the volume correctly routed to the cheaper tier, and r · k is the cost of maintaining defensibility — the external-validation expenditure, with r the validation rate and k its unit cost.
The five fields instantiate the same form:
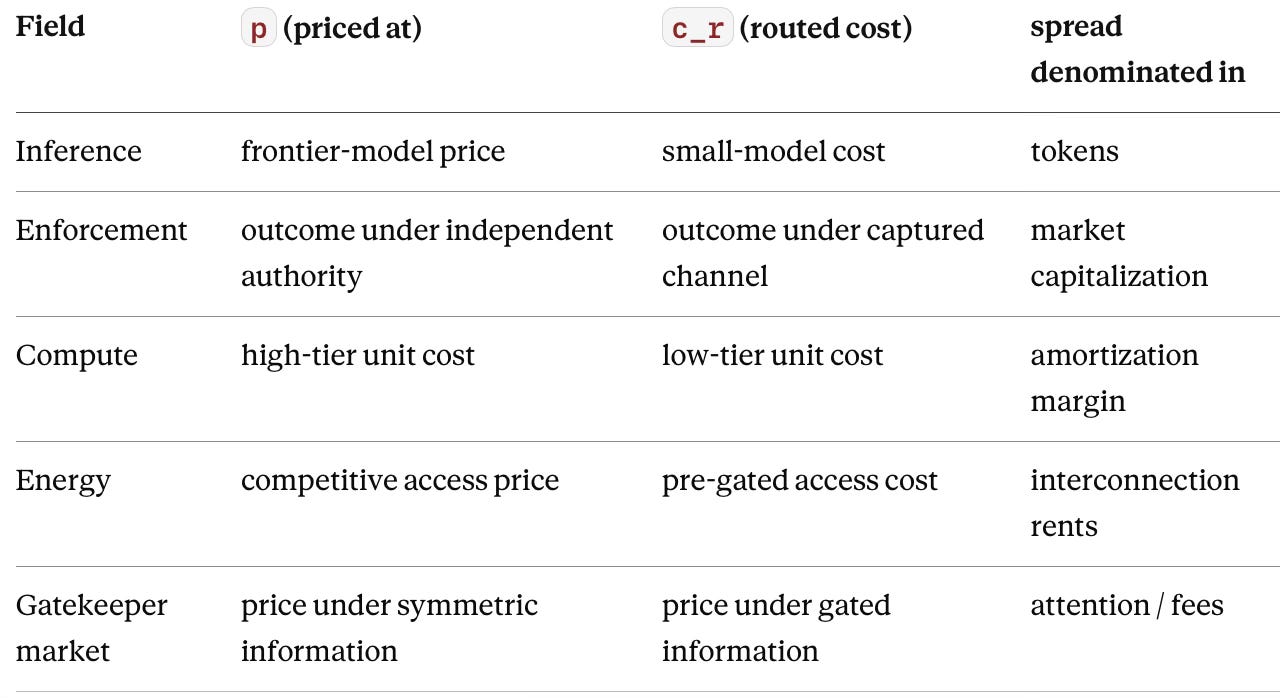
The final term carries the theorem. The rate r can fall as validation tooling improves, raising Rent(C) — which is exactly why control layers are lucrative. The rate r cannot reach zero without the objective going uncertified, which sets the positive floor and caps how defensible an unchecked control layer can be. The arbitrage and the theorem are one result seen from two sides: the spread is what the governance gap is worth to whoever services it, and the floor is what keeps servicing it from ever going free. MindCast sells the measurement of both.
Appendix B — Works Cited
The MindCast works below are grouped by the role each plays in the architecture, with one line on why the paper draws on it.
Foundational — the domain-agnostic engine
Predictive Cybernetics Suite — supplies the feedback-and-control mechanism underneath the whole framework.
The Cybernetic Foundations of Predictive Institutional Intelligence — grounds the loop-closure and requisite-variety arguments the control-layer section rests on.
Cybernetic Game Theory — provides the diagnostic protocol for reading whether a system’s stability is genuine or captured.
Nash-Stigler Equilibria — supplies the settlement-and-sufficiency stopping rule that lets a simulation commit a falsifiable call.
Emergent Game Theory Frameworks — collects the operational instruments the applied domains share.
The Full Arc of Prediction Markets — abstracts the signal-to-control arc that recurs across unrelated domains, evidence for the universal-structure claim, and shows why cheap prediction degrades without an external regime-classifier.
Applied — control and oversight
Agent Governance Equilibrium — measures the gap directly as governance debt and anchors the theorem’s scarcity half.
AI Accountability Series — supplies the legal form of the external check that keeps governance from self-certifying.
Prediction Markets Architecture Series — documents prediction reaching its cost floor while governance of it stays unresolved.
Prediction Markets Reveal Truth — Feedback Loops Determine It — establishes when a measuring market crosses into a controlling one, the membership-test boundary case.
Applied — structure and value capture
Runtime Geometry — gives the economic statement of how a gated field warps around whoever controls the flow.
The Shadow Antitrust Division — documents capture settling into equilibrium where correction should be.
Nash-Stigler: LiveNation & Compass — applies the settlement-without-sufficiency test to live antitrust matters.
Chicago School Accelerated — supplies the coordination-failure sequence the governance gap produces in competition law.
Compass’s Interpretation of “Public Marketing” — the sharpest worked example of the external check, with state attorneys general as the only actors outside the captured loop.
AI Inference Arbitrage — names the cognition-layer instance of the one trade and its consequence for frontier amortization.
Consumer AI Device Series — states the product-to-control-layer migration and reuses the prediction-market arc on device ecosystems unchanged.
The Power Stack — tracks the same value migration into physical energy access.
Tirole & Advocacy Arbitrage — names the enforcement-layer instance of the one trade.
Validation — open-scoreboard proof
Super Bowl LX — AI Simulation vs. Reality — demonstrates the method on a public scoreboard, with a documented mid-season revision.
World Cup Championship Index — carries the methodological spine where the control thesis runs faint.
The Kalshi/CFTC record — proof of product on a live docket
CFTC v. New Mexico — the live case where every contested question is about who governs the markets, not whether they predict.
The CFTC NPRM analysis — the rulemaking-track reading filed into the public record.
The National Kalshi Litigation Map — tracks the contest across federal, state, and tribal forums in real time.
