

MCAI Innovation Vision: Triadic Calibration and the Acceleration of Metacognition
How Predictive Cognitive AI Converts Fragmented Cognitive Skills into a Unified, Measurable Calibration System

Metacognition, empathy, and learning are not separate skills. They are coordinated signal pathways in a single calibration system. Most frameworks stop at describing that system. MindCast crossed the line that cognitive science never did: operationalizing metacognition as a measurable, enforceable layer in institutional decision-making — scored, routed, gated, and held accountable to outcomes. MindCast makes that system explicit, measurable, and executable.
Executive Summary
The most consequential failure mode in institutional AI is not hallucination. It is miscalibration — the condition in which a system consumes high volumes of information, produces confident outputs, and systematically degrades in predictive accuracy under adversarial conditions, narrative pressure, or environmental shift. Frontier AI models optimize for pattern recognition across a single axis. They do not self-audit, model counterpart cognition, or integrate feedback in a controlled loop. When deployed at institutional scale — in investment analysis, regulatory oversight, litigation strategy, or competitive intelligence — that architectural gap becomes a liability.
The deeper problem is that the missing control layer has never been formalized. Academic research maps pieces of it: Flavell on metacognitive monitoring, Baron-Cohen on theory of mind, Bandura on social learning, Friston on predictive error minimization. Each framework describes part of what a calibrated decision system needs to do. None converts those insights into executable control logic with measurable outputs and routing rules. The result is that investors pricing AI-exposed assets, regulators designing oversight architecture, litigators tracking counterpart behavior across forums, risk managers stress-testing decision systems under adversarial pressure, and corporate strategists deploying AI in competitive environments are all operating with fragmented cognition baked into their tooling — and no instrument to detect it.
MindCast AI closes that gap. The Triadic Calibration System formalizes metacognition, empathy, and learning from others not as separate cognitive skills but as three interdependent signal pathways feeding a single calibration engine. Each pathway generates a measurable score. The scores combine into a single trust gate — Causal Signal Integrity (CSI) — that determines whether causal inference can proceed, must be moderated, or should be suppressed pending further signal audit.
Critically, MindCast does not leave this as a theoretical framework. The Triadic Calibration System is deployed as a runtime module inside the MindCast AI Proprietary Cognitive Digital Twin (MAP CDT) Foresight Simulation architecture — detailed in MindCast’s analysis of Google DeepMind and institutional filter architecture. Running before high-confidence causal routing, the module gates downstream prediction output and generates scored calibration states that are falsifiable against observed outcomes. For the first time, calibration becomes a measurable, auditable, executable property of an AI decision system — not a qualitative judgment about analyst quality or model confidence.
The advancement is architectural — and it crosses a line most systems never reach. Cognitive science has described metacognition for fifty years. MindCast is the first system to operationalize it as a measurable, enforceable layer in institutional decision-making: scored, routed, gated, and falsifiable against outcomes. The move is from observation to enforcement — from a trait that analysts are encouraged to develop to a control layer that runs whether or not any individual analyst is paying attention.
MindCast does not treat metacognition as reflection. It treats it as infrastructure.
I. Fragmented by Design: Why Cognitive Science Built the Wrong Architecture
Every major cognitive framework of the last fifty years optimized for depth in one domain at the expense of integration across all three. Metacognition is studied as internal monitoring (Flavell, 1979), empathy as perspective-taking through theory of mind (Baron-Cohen, 1995), and learning as behavioral adaptation through observation (Bandura, 1977). Each framework produces genuine insight — and each one stops precisely where the real calibration problem begins.

Separating those domains creates a structural limitation: each optimizes locally and fails globally. Systems built on fragmented cognition generate inconsistent predictions, slow error correction, and vulnerability to narrative distortion. National Academies reports on decision-making and intelligence analysis reinforce fragmentation by treating these as separate competencies rather than a unified system.
Real institutions fail when these functions fall out of sync. The Triadic Calibration Module solves that problem by treating them as interdependent signal pathways in one calibration architecture — replacing the academic design choice with an operational one.
II. Three Signal Pathways, One Calibration Engine
Unifying metacognition, empathy, and learning is not a theoretical gesture — it is an architectural necessity. Each domain generates a distinct class of signal that the other two cannot produce: internal coherence data, cross-agent behavioral prediction, and feedback-driven model correction. Suppressing any one of them degrades the system’s ability to route causal inference accurately. MindCast integrates all three into a single shared calibration engine where each pathway is scored, weighted, and combined.
Triadic Calibration System = Metacognition + Empathy + Learning
1. Metacognition → Internal Signal Audit
MindCast operationalizes metacognition through Causal Signal Integrity (CSI) and Action–Language Integrity (ALI) — both defined operationally in MindCast’s Investor Guide to AI, where ALI measures the gap between stated strategy and observable communication across documented decision events.
Detects contradictions between belief, language, and action
Filters low-integrity causal claims
Stabilizes internal reasoning
Metacognition becomes a measurable signal validation layer rather than a reflective habit. ALI is scored 0–1 based on the observed frequency of contradictions between stated positions and documented actions across a defined observation window — higher contradiction density produces lower ALI.
2. Empathy → Cross-Agent Model Construction
Empathy is implemented through Installed Cognitive Grammar (ICG) modeling, extending theory-of-mind concepts into operational prediction (Baron-Cohen, 1995). ICG reconstructs how counterpart agents process reality — distinguishing stated intent from actual cognitive structure to enable prediction of behavior under constraint. The output is a Relational Integrity Score (RIS): scored 0–1 based on the prediction accuracy of counterpart behavior across observed decision points, with higher forecast accuracy producing a higher RIS.
Empathy becomes a modeling function, not an emotional trait.
3. Learning from Others → Feedback Integration
Learning is implemented through cybernetic feedback loops aligned with social learning theory (Bandura, 1977). Cognitive–Motor Fidelity (CMF) — formalized in MindCast’s Investor Guide to AI as the measure of execution fidelity against stated intent — is the primary scoring instrument for this pathway.
Captures external signals: behavior, outcomes, decisions
Updates internal models based on performance
Adjusts adaptation speed via feedback latency
Learning becomes a controlled update mechanism governed by signal quality. CMF is scored 0–1 based on outcome alignment — the degree to which executed decisions match the intended strategic model after accounting for environmental variance.
Integrated, the three pathways form an enforceable control architecture. MindCast routes all three through a shared calibration engine that scores their integrity before allowing inference to proceed — no single pathway can compensate for a failure in either of the other two, and the engine surfaces that failure rather than absorbing it silently.
Contact mcai@mindcast-ai.com to partner with us on Predictive Cognitive AI in Law and Behavioral Economics. To deep dive on MindCast work in Cognitive AI upload the URL of this publication into any LLM and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
Recent projects: MindCast AI Emergent Game Theory Frameworks | Google’s Deep-Thinking Ratio Measures Effort, Not Structure | The Cognitive AI Response to Apple’s “The Illusion of Thinking | MindCast AI Constraint Geometry and Institutional Field Dynamics | The Runtime Causation Arbitration Directive | Runtime Geometry, A Framework for Predictive Institutional Economics
III. CSI: The Trust Gate That Routes Institutional Intelligence
Most AI systems produce a confidence score. MindCast produces a calibration score — and the difference determines whether downstream inference is trustworthy or contaminated. The CSI equation aggregates the three signal pathways into a single value that gates causal routing: high CSI allows prediction to proceed at full confidence; degraded CSI triggers moderation or suppression before outputs propagate forward into decision architecture.
CSI = (ALI + CMF + RIS) / DoC²
ALI (Action–Language Integrity) ← metacognition
CMF (Cognitive–Motor Fidelity) ← learning
RIS (Relational Integrity Score) ← empathy
DoC (Degree of Contradiction) ← derived from the run-time field
DoC is not a manual input. MindCast derives it as a composite of contradiction density, signal entropy, and cross-context divergence. Squaring DoC reflects a critical architectural insight: contradictions compound rather than accumulate. When an institution speaks differently across legal, media, political, and internal forums simultaneously, distortion multiplies — it does not merely add.
CSI functions as a trust gate. If calibration fails, the system blocks causal inference from propagating forward. If calibration holds, the system enables high-confidence prediction. The gating mechanism is formalized in MindCast’s Runtime Causation Arbitration Directive, which establishes that higher-order institutional reasoning requires a runtime audit layer to prevent model collapse under contradiction pressure.
For investors, regulators, and firms operating in adversarial environments, CSI answers the question that confidence scores cannot: not how certain is this output, but whether the system generating it is reasoning coherently across all three signal axes simultaneously — a more consequential standard than certainty alone.
IV. MMI: The Benchmarking Index That Makes Calibration Comparable
CSI tells a system whether it can proceed. The MindCast MetaCognition Index (MMI) tells an institution how well it is calibrated — and how that calibration compares against other actors, across time, and across environments. CSI is enforcement; MMI is benchmarking. Both are necessary, and neither substitutes for the other.
Every runtime output from the Triadic Calibration Module produces a headline MMI score alongside its component values — giving institutions a single trackable number that encodes the full calibration picture and supports comparison across actors, time periods, and decision environments.
MMI = (w₁·ALI + w₂·CMF + w₃·RIS) × (1 − DoC_norm)
Where weights sum to 1 and DoC_norm — the normalized contradiction burden, scaled 0–1 from the raw DoC field — acts as an environmental penalty multiplier. Default weighting in balanced environments is ALI = 0.4, CMF = 0.3, RIS = 0.3 — reflecting that internal coherence is the foundational signal from which the other two pathways derive their reliability. Weights shift by environment type: adversarial and litigation contexts elevate RIS; internal strategy environments elevate ALI; fast-moving high-feedback environments elevate CMF.
Output bands
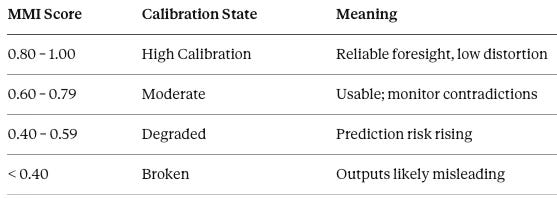
DoC as regime switcher
DoC is not merely a penalty applied to raw scores — it is a regime switcher that determines whether MMI reflects true capability or environmental contamination. Low DoC allows MMI to surface genuine system quality. High DoC collapses MMI regardless of how strong the underlying ALI, CMF, and RIS scores are. A sophisticated system operating inside a high-contradiction environment still fails. MMI makes that dynamic visible and quantifiable rather than attributing poor outputs to model error alone.
Worked example — System A
ALI: 0.8 · CMF: 0.7 · RIS: 0.6 · DoC: 0.2 (DoC_norm = 0.2)
MMI = (0.4 × 0.8 + 0.3 × 0.7 + 0.3 × 0.6) × (1 − 0.2) = (0.32 + 0.21 + 0.18) × 0.8 = 0.71 × 0.8 = 0.57 → Degraded
The system looks internally coherent. ALI and CMF are strong. The contradiction burden — not raw capability — is what drives the score into the Degraded band. Without MMI, that diagnosis is invisible. With it, the institution knows exactly where the failure is originating and what to address.
With MMI, institutions can compare calibration across actors in the same system — Compass versus NWMLS, Kalshi versus its regulators — track drift before and after a forcing event, and hold AI decision systems accountable to a published, falsifiable benchmark rather than opaque confidence scores.
V. Who This Architecture Serves — and How
The Triadic Calibration System and MMI are not general-purpose tools. Each stakeholder class faces a distinct calibration failure mode, and each gets a distinct instrument from the architecture. The following maps those relationships explicitly.
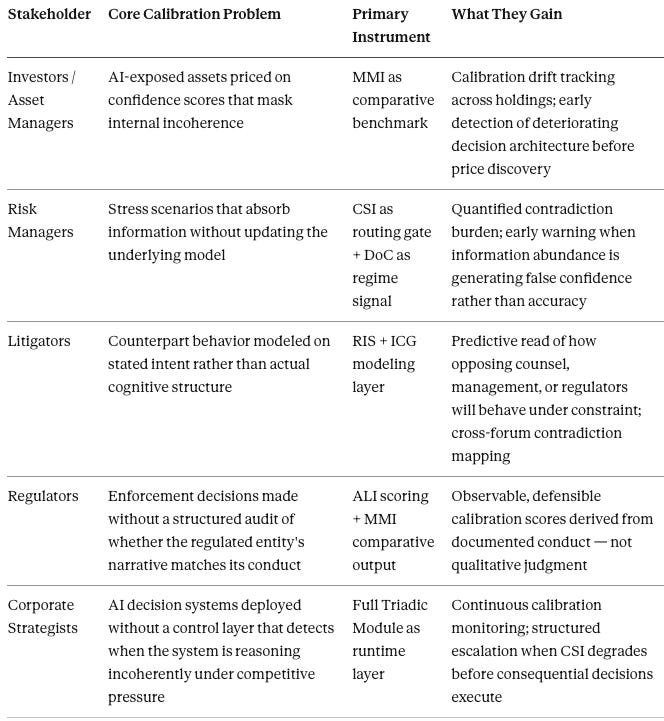
Each stakeholder group represents an institution already operating in the environment the Triadic Calibration System was built to address: high information volume, adversarial counterparts, consequential outputs, and no existing instrument to measure whether the decision architecture is functioning or merely appearing to function. MMI gives each of them a number they can track, report, and defend. CSI gives the system a gate that enforces calibration before inference propagates forward. Together they close the gap between analytical activity and analytical integrity.
VI. From Reflection to Runtime: How MindCast Accelerates Metacognition
Traditional metacognition is slow, introspective, and episodic — it operates after the fact and produces insight that arrives too late to influence the decision that generated the error. MindCast eliminates that latency by embedding metacognition in a closed-loop cybernetic system aligned with Friston’s predictive processing model (2010): the system models, compares against outcome, updates, and re-tests continuously rather than periodically. The result is metacognition that functions as real-time infrastructure rather than post-hoc reflection.
Model → Compare → Update → Re-test
The loop operates continuously across three axes:
Self (metacognition)
Others (empathy)
Network (learning)
Key acceleration mechanisms:
Reduced feedback latency (faster error detection)
Continuous external validation (not self-referential)
Signal filtering via CSI (noise suppression)
What MindCast has built is not a faster version of traditional metacognition — it is a fundamentally different thing. Deploying the Triadic Calibration Module as a runtime layer means that every foresight simulation the MAP CDTproduces passes through a continuous calibration check before its outputs are released. The system does not wait for an analyst to notice a contradiction. It detects, scores, and routes in real time.
The practical consequence is that calibration stops being a function of who is in the room and becomes a property of the architecture itself. Analyst turnover, attention failures, and cognitive load no longer determine whether the system catches its own errors — the runtime module does.
VII. Four Calibration States: What the Module Actually Tells You
A system’s calibration state is more diagnostically useful than its confidence score. Confidence tells you how certain a model is about its output. Calibration state tells you whether the system’s reasoning architecture is functioning — and if not, precisely where it is breaking down. The Triadic Calibration Module classifies every run-time decision environment into one of four states, each with distinct routing consequences.
1. Integrated Calibration High ALI, high CMF, high RIS, low DoC. Causal inference can proceed. Metacognition is functioning as real-time infrastructure.
2. Reflective but Socially Degraded High internal audit, weak cross-agent modeling. Self-awareness exists; opponent or stakeholder behavior is misread. High risk of strategic blind spots.
3. Socially Perceptive but Internally Unstable Strong other-modeling, weak self-audit. The system tracks other minds accurately but becomes vulnerable to narrative capture or manipulation.
4. Information-Rich but Calibration-Broken High intake, low integration, high contradiction burden. The system appears informed; prediction quality degrades. Adaptation slows despite signal abundance.
The four states are not ranked by severity alone — they are ranked by diagnosability. State IV is the most dangerous precisely because it is the hardest to detect from the inside. A system in State IV looks like it is working. The volume of information processed, the apparent confidence of outputs, the sheer activity of the decision apparatus — all of it creates the appearance of function while calibration deteriorates underneath. The module makes that deterioration visible before it compounds into a consequential error.
VIII. Why Four Decades of Cognitive Research Didn’t Get Here First
The academic literature on cognition is not wrong — it is incomplete by design. Flavell mapped metacognitive monitoring. Baron-Cohen mapped theory of mind. Bandura mapped social learning. Friston mapped predictive error minimization. Each framework was built to explain a phenomenon, not to operate a system. None of them crossed the line from description to control logic, from insight to executable architecture with measurable outputs and routing rules.
Flavell on metacognitive monitoring — mapped internal regulation of cognition, stopped at self-report
Baron-Cohen on theory of mind — mapped modeling of others’ mental states, stopped at diagnosis
Bandura on social learning — mapped learning through observation, stopped at behavior description
Friston on predictive processing — mapped error minimization, stopped at neural modeling
National Academies — reinforced fragmentation by treating decision and learning competencies as separate domains across education, intelligence analysis, and organizational learning
Each framework advanced understanding of one signal pathway. None integrated all three into a single executable architecture.
Academia treats cognition as capability. MindCast treats cognition as calibration — subordinating the academic frameworks rather than superseding them. Flavell, Baron-Cohen, Bandura, and Friston each contributed a component. MindCast integrates those components into a control architecture none of them attempted to build: the first operationalization of cognition as a measurable, auditable, enforceable system property.
What that operationalization unlocks is institutional accountability that prior frameworks could not support. A regulator can now audit calibration state from documented conduct. An investor can track MMI drift across time. A litigator can score RIS against observed counterpart behavior. None of those applications were possible when metacognition remained a descriptive concept rather than a scored, routed, executable layer.
IX. Predictable Failures: How Miscalibration Breaks Institutional Systems
The triadic system’s failure modes are not random — they are structurally determined by which signal pathway has gone dark. Each pattern produces a recognizable institutional pathology: the firm that is analytically rigorous but repeatedly blindsided by counterpart behavior; the negotiator who reads the room perfectly but cannot hold a consistent position; the intelligence system that absorbs more data than any prior generation and produces worse forecasts. The module identifies which pathway is failing and routes accordingly.
High metacognition, low empathy → accurate but socially blind predictions
High empathy, low metacognition → susceptibility to manipulation and narrative capture
High learning, low filtering → noise accumulation and model degradation
High information intake with no error reduction → calibration failure
Falsification condition (external): If a system consumes large volumes of information but fails to improve prediction accuracy over time, the triadic calibration system is not integrated.
Falsification condition (internal): If the module reports improved calibration while prediction error remains flat or worsens across repeated decision cycles, the module is either mis-specified or reading the environment incorrectly.
Falsifiability is not a concession — it is the source of the framework’s credibility. Any system that cannot specify the conditions under which it is wrong is not a decision tool; it is a rationalization engine. MindCast publishes its falsification conditions because the architecture is designed to be held accountable to outcomes, not protected from them.
X. The Cost of Fragmentation: What Institutions Lose Without Integrated Calibration
Every institution operating without integrated calibration architecture is paying a tax it cannot see on its balance sheet. Feedback cycles slow because the system cannot distinguish signal from noise without a filtering layer. Strategic adversaries exploit perspective gaps that a cross-agent modeling function would have detected. Information abundance creates false confidence — the system mistakes volume for accuracy and accelerates into error rather than correcting away from it.
Intelligence does not scale with information volume. Intelligence scales with calibration across perspectives.
Appendix A: What MMI Looks Like in Practice
The value of MMI is not the number it produces — it is what the number reveals: why two decision-makers reviewing identical evidence reach different conclusions. The scenario below scores three regulators against the same AI trading platform to show how calibration state — not information access — determines outcome.
Scenario: A new AI-driven trading platform launches claiming low risk, consistent returns, and market-neutral performance. Three state regulators review the same company, the same marketing claims, the same disclosures, and the same early performance data.
Regulator A — High MMI
Regulator A tests whether the company’s public story matches its conduct. The regulator compares marketing language against disclosures, checks internal incentives against stated strategy, examines early trading behavior against the low-risk framing, models management behavior under stress, and reviews prior signals for confirmation or contradiction.
ALI: 0.90 — public claims and actual operating behavior largely align
CMF: 0.85 — the assessment updates as new data arrives, staying tied to observed performance rather than company narrative
RIS: 0.80 — management incentives are read correctly, including where leadership would be tempted to stretch risk language
Contradiction burden stays low because the regulator resolves small inconsistencies early rather than letting them accumulate.
MMI: High · Decision: No immediate enforcement; structured monitoring
Regulator A does not look soft. Regulator A looks calibrated. The finding is not that risk is absent — it is that the regulator identified which signals mattered, tested them against observed conduct, and kept the analysis coherent as conditions evolved.
Regulator B — Moderate MMI
Regulator B detects some of the same warning signs but does not integrate them cleanly. Marketing language reads stronger than the fine print. Early results are less stable than the company suggests. But the regulator does not press hard enough on incentive structure and fails to fully model how management behavior may diverge once performance comes under pressure.
ALI: 0.75 — some mismatch between narrative and conduct is caught, not all
CMF: 0.65 — new information is incorporated, but the update process is uneven and slow
RIS: 0.60 — management’s optimization target is only partially understood, leaving later behavioral divergence underestimated
Contradiction burden rises because inconsistencies are noticed but left unresolved.
MMI: Moderate · Decision: Request additional disclosures; issue cautionary guidance; continue monitoring
Regulator B is not blind — Regulator B is late. The system senses that something is off, but calibration is not strong enough to convert that signal into a coherent, actionable view of the problem.
Regulator C — Low MMI
Regulator C reads the materials, sees polished leadership, and accepts the low-risk framing largely as presented. The regulator does not check whether language matches operating behavior, does not model management incentives with rigor, and does not revise the assessment when new signals begin to conflict with the original story.
ALI: 0.60 — gaps between what the company says and what the company does go unexamined
CMF: 0.50 — information is absorbed but not translated into an updated working model
RIS: 0.40 — management incentives are misread; behavioral deterioration under performance pressure is not anticipated
Contradictions accumulate rather than resolve. The system remains active, informed, and confident — but not calibrated.
MMI: Low · Decision: No action
Regulator C does not fail for lack of data. Regulator C fails because the system cannot integrate the data it already holds into a stable, reality-aligned model. The information was present. The calibration architecture was not.
What the example demonstrates
Three regulators. One company. Three outcomes — each structurally determined by calibration state, not by information access. ALI scores whether the regulator checked narrative against conduct. CMF scores whether the regulator updated the model when reality changed. RIS scores whether the regulator correctly read what the company was actually optimizing for.
MMI does not replace judgment. MMI shows whether judgment is functioning coherently — and produces that diagnosis before the consequences of miscalibration become irreversible.
Reframing AI's core failure mode as miscalibration rather than hallucination is a profound and measurable insight — calibration error is quantifiable via Expected Calibration Error (ECE) and reliability diagrams, making it far more actionable than vague notions of hallucination. The triadic system treating metacognition, empathy, and learning as unified signal pathways is a bold architectural vision. Noel, this series is doing critical work that bridges cognitive science and AI engineering in a way that is both rigorous and practical. Truly impressive scholarship.