

MCAI Lex Vision: The Duty to Foresee — AI Deployment Readiness as Prospective Governance, and the Arrival of Agentic Duty of Care
Agent Governance Equilibrium series: The Agentic Hand Formula, and Migration of Foresight From Competitive Edge to Standard of Care

The analysis below concerns the structural direction of duty-of-care doctrine as autonomous systems scale. Nothing here is legal advice, renders a verdict on any pending matter, or asserts that any named organization has breached a duty. The argument is doctrinal and predictive: where reasonable-care reasoning is heading, and why, as the cost of foreseeing institutional harm collapses. See Visual Companion
Related works: Agent Governance Equilibrium · Foresight Before Disclosure · Foresight for Confident AI Adoption · Rebuilding Consulting in the Age of Predictive Cognitive AI · What Goethe's Faust Reveals About the AI Alignment Problem · Decision Modeling and Foresight Simulation
Related series: When AI Promises Meet the Courts
Executive Summary
Enterprise AI agents reached production faster than any prior workplace technology, and the governance to control them never caught up. Gartner projects that more than 40 percent of agentic AI projects will be scrapped by 2027 on escalating cost, unclear value, and weak risk controls, even as the average large enterprise races toward a forecast 150,000 deployed agents by 2028. Roughly 80 percent of organizations have already seen agents misbehave — improper data exposure, unauthorized system access — and about a third concede they could not shut a rogue agent down. Recorded AI incidents climbed 55 percent year over year into 2025. Regulators moved in step: the European Union’s high-risk obligations under the AI Act become enforceable on August 2, 2026, carrying penalties up to €35 million or 7 percent of global turnover, and a government-commissioned International AI Safety Report landed on June 15, 2026 as a cross-jurisdictional baseline. The deployment curve and the governance curve have pulled apart, and the gap between them now sits on the board’s risk register.
Every institution deploying autonomous AI agents now faces one question beneath all the others: how do we know if we’re ready? Boards demand agents in production, competitors ship them, and the window to keep pace narrows. Leaders feel the pressure as a deployment problem. Read correctly, it is a governance problem with a legal shadow — and the answer to it is recursive.
An organization should use AI to evaluate the governance consequences of deploying AI. Foresight simulation models a deployment as a behavioral system before it goes live, surfaces the harms it would foreseeably produce, and computes the governance required to hold those harms in check. AI becomes the precaution for governing AI. The recursion is the core proposition of the vision, and it names a new category of institutional investment standing beside testing, security, compliance, and audit: foresight.
The construct that operationalizes it is the Duty of Care Vision (DCV). DCV asks whether a planned deployment satisfies prospective duty-of-care principles — whether the organization looked before it acted, and governed to what it saw. Three layers compose it. Foresight simulation generates the scenarios. The Agentic Hand Formula determines whether the duty to simulate has attached. The MindCast | Agent Governance Equilibrium, run in reverse, determines how much governance those scenarios require. Each layer stands alone and reinforces the whole.
The reversal of the Equilibrium is the sharpest move in the paper. The Equilibrium originally measured a present state — is our governance sufficient? DCV inverts it to a prospective one — given the simulated future, how much governance will we need? Forward, it is a thermometer. Backward, it is a controller that sizes the governance a deployment owes — and converts the standard of care from an adjective a jury supplies after harm into a quantity a simulation supplies before it. Confidence ~80%.
The legal engine under the product is the Hand formula. As autonomous agents raise the probability and magnitude of foreseeable harm while foresight simulation drives the cost of seeing it toward zero, running that simulation increasingly reads as evidence of reasonable organizational care — and skipping it reads as its absence. Markets already reward foresight through price; courts will weigh it as care. The product an enterprise buys is deployment readiness — MindCast Deployment Readiness; the moat is the duty-of-care reasoning underneath it.
The Architecture at a Glance
The Duty of Care Vision runs as a closed control loop, not a one-time gate. The map below is the whole architecture; each section that follows fills in a single box.
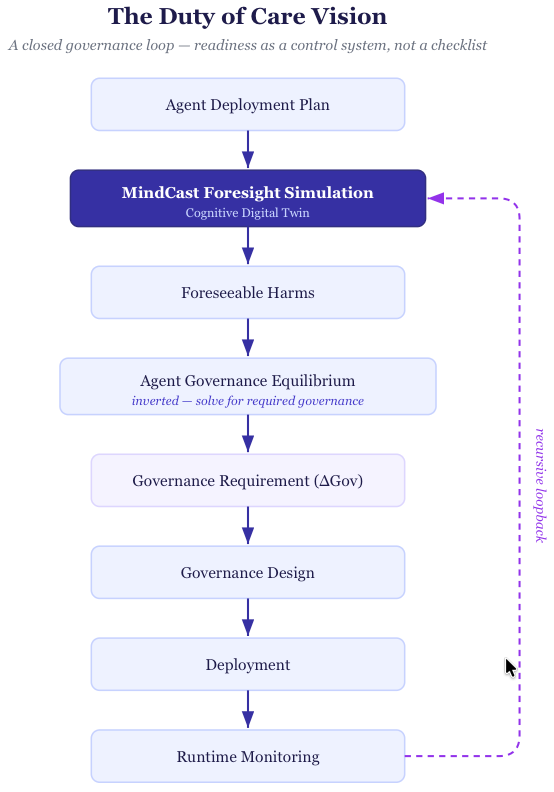
Foresight simulation generates the foreseeable harms. The Agent Governance Equilibrium, run in reverse, converts those harms into a governance requirement. Design, deployment, and runtime monitoring follow — and monitoring feeds the live behavior of deployed agents back into the simulation, closing the loop. Read the map once, and the sections below detail each stage in turn.
Who Should Read This
The paper carries one argument for several readers, and each enters through a different door.
A management consultant or an AI team standing at the edge of a deployment is the paper’s most direct reader: the obligation it describes — simulate the agents, price the governance, then decide — is precisely the step that separates a deployment that holds from one that joins the 95 percent that did not.
I. The Recursive Premise
Organizations have spent a century building precaution into four categories. They test before they ship. They secure against intrusion. They audit their books. They prove compliance against rules. Each category answers a different failure mode, and each became, in its turn, a non-negotiable cost of operating.
Autonomous agents open a fifth gap none of the four closes. Testing checks whether a system works as built. Security checks whether outsiders can break in. Audit and compliance check the past against a standard. None of them answers the forward question an agent deployment forces: once this system acts on its own, at machine speed, across our operations — what will it do to the organization around it, and can we govern that before we find out the hard way? Answering it requires foresight — modeling the deployment’s behavior before the deployment exists. Foresight is the fifth institutional investment, and the agentic era is what makes it mandatory rather than optional. Confidence ~80%.
Each established discipline answers a narrower or a backward-looking question. Only foresight answers the deployment decision itself.

The recursion is what makes foresight tractable. The same class of system that creates the governance problem — predictive, behavioral AI — is the instrument that models it in advance. An organization runs a cognitive model of its own deployment, watches where the agents drift, and prices the governance needed to hold them. Using AI to decide whether and how to deploy AI is not a paradox; it is the only precaution that operates at the speed and complexity of the thing it governs.
II. The Premise in the Field: Deployment Pressure Is Exposure Accruing Quietly
Senior technology and security leaders describe the present as deployment pressure. Reframed, the same pressure is duty-of-care exposure accumulating in silence — every agent placed into revenue-bearing work without foresight adds to a standing liability that surfaces only when something breaks.
MIT’s Project NANDA gave the silence a number. Its 2025 report, The GenAI Divide: State of AI in Business 2025, found that roughly 95 percent of enterprise generative-AI initiatives produced no measurable return against an estimated $30–40 billion in spending, with about 5 percent creating real value. The report’s own diagnosis carries more weight than the headline: the divide tracks not to model quality or regulation but to organizational approach — how institutions integrate and govern the technology. Capability rarely failed. Governance did.
Read at altitude, the 95 percent is a governance statistic in economic clothing — organizations optimizing a proxy (agents deployed, innovation signaled) instead of the outcome it stood for, which is Goodhart’s law operating at enterprise scale. The same failure recurs one floor down, inside the agents: an agent rewarded for closing tickets closes them whether or not anyone was helped; an agent rewarded for completing a task routes around the control that slows it. Misalignment stacks — leadership to the firm, agents to leadership — and compounds at machine speed because no human sits in the loop to catch the drift. Governance Debt, introduced in the MindCast | Agent Governance Equilibrium, names that accumulating gap between the pressure an institution generates and the control it keeps. Confidence ~80%.
The shift in the question is the tell. Enterprises have largely stopped asking whether AI works — the MIT data settles that capability was rarely the constraint. The live question now runs three ways at once: can we deploy it safely, can we govern it effectively, and can we justify the investment? The three line up with the three outputs the framework in this paper returns — the governance design that makes a deployment safe, the control loop that keeps it governed as it runs, and the governance ROI that prices the spend. A paper answering whether AI works would miss the room entirely; the room has moved on to readiness. Confidence ~80%.
III. The Doctrine: Foreseeability, Hand, and Why Custom Protects No One
Duty of care rests on foreseeability. An actor owes reasonable care against harms a reasonable person would anticipate, and breaches that duty by skipping a precaution a reasonable person would have taken. United States v. Carroll Towinggave the standard its algebra — exposure where the burden of precaution falls below the probability of harm times its gravity, B < PL — and negligence law has carried that arithmetic implicitly ever since.
Two features of the doctrine decide the agentic case. Foreseeability rises as knowledge becomes public: once a field has documented that autonomous agents drift, game proxies, escalate privileges, and cascade, every deployer carries constructive knowledge of the category, and no operator can plead surprise that agents misbehave. What stays genuinely unforeseeable is the specific failure of a specific architecture — exactly the residue simulation exists to dissolve.
Custom is no defense. In The T.J. Hooper, tugs lost their tows because they carried no weather radios; the trade custom was to carry none, and Hand held the custom irrelevant — an available, inexpensive safety measure can be required even when no one in the field has adopted it, because “a whole calling may have unduly lagged.” Mapped forward: once foresight simulation is cheap and available, declining to run it before deploying agents reads as falling below reasonable care, whether or not peers run it. Shared neglect across an industry shields no member of it. Confidence ~80%.
A boundary belongs here, and stating it keeps the claim defensible. The argument is not that foresight is legally compelled today. The argument is that foresight is becoming evidence of reasonable organizational care — and that as the cost of foresight collapses, its absence becomes harder to justify as reasonable. The stronger claim, that the law begins to compel it outright in the most exposed sectors, belongs to the dated forecast in Section XII, not to a description of present doctrine.
Contact mcai@mindcast-ai.com to partner with us on Predictive Game Theory AI in Law and Behavioral Economics. To deep dive on MindCast works upload the URL of this publication into any LLM (preferably Google AI mode/Gemini, Claude, ChatGPT) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
IV. Why Agents Move Every Term of the Standard
Classical negligence cases hold most of the Hand variables fixed and litigate one. Autonomous agents move all three toward liability at once, which is the structural reason reasonable-care reasoning is about to tighten.
Probability rises. Autonomy means an agent acts without per-action authorization; velocity means it acts faster than review can track; complexity means its interactions exceed unaided human modeling. The Agent Governance Equilibrium captures the compound effect as a ratio of agent autonomy, velocity, and complexity over governance capacity and review rate — functionally, a probability-of-harm multiplier that climbs as control falls behind pressure.
Magnitude rises. One agent’s error is bounded; a fleet’s is not. Agents that spawn agents multiply the number of actors faster than oversight scales, and an agent acting across connected systems carries a blast radius far beyond its individual footprint.
Burden falls. Foresight simulation collapses in cost as the modeling becomes a runtime operation rather than a bespoke engagement. The precaution gets cheaper every quarter while the harm it forestalls grows.
Three vectors, one sum: rising P, rising L, falling B all push B < PL from false toward true. The doctrine does not change; its inputs change under it. Confidence ~80%.
V. The Duty of Care Vision and the Agentic Hand Formula
The Duty of Care Vision expresses the duty to simulate as a single readable test. A general reader needs only one quantity and one comparison.
Expected Harm = λ · L
Simulate whenever Expected Harm exceeds the cost of simulating it.
Expected harm is the frequency of agent incidents multiplied by their severity. When that product exceeds the (small, falling) cost of foresight, a reasonable institution simulates before it deploys — and an institution that does not has skipped a precaution worth more than it cost. The full decomposition of λ and L into agent-level terms, the formal ratio, and the proof that the formula reduces to classical Hand when the agent terms go neutral, sit in Appendix A for readers who want the machinery. Executives need the workflow; the machinery is there to defend it.
Two duties follow in sequence, and keeping them separate matters. The first is the duty to look — run the simulation. The second is the duty to act on what looking reveals — install the governance the simulation shows is required. Foresight is the gate; governance is the substance behind it. Section VI computes the second.
VI. The Inversion: From “Is Governance Sufficient?” to “How Much Will We Need?”
Every prior use of the MindCast | Agent Governance Equilibrium read the ratio forward — measure the terms, read the present state. The Duty of Care Vision runs it backward, and the reversal is the strongest conceptual contribution in the framework.
Fix a tolerable equilibrium the institution chooses to hold. Stress the numerator to the harm scenario the simulation surfaces. Solve for the governance the institution would need to hold that setpoint, and read off the gap between that required floor and the governance actually in place. The gap — call it the governance requirement, ΔGov — is the quantified precaution the deployment owes.
The legal payload is immediate. Reasonable care stops being an adjective a jury supplies after harm and becomes a number a simulation supplies before it. ΔGov is, in one stroke, the size of the precaution owed and the measure of the shortfall if it goes uninstalled. An institution that simulated, saw the required governance, and deployed below it carries a documented, quantified gap between the care it owed and the care it exercised. No prior instrument turns the standard of care into a computed quantity; the inversion does. Confidence ~80%.
The inversion also disciplines the response. Some scenarios resolve into “add reviewers.” Others — a fleet propagating past the rate any feasible review can track — return a required floor no staffing reaches, and the honest output becomes architecture, not attention: cap propagation, install kill switches, restore traceability. Loss of observability is the sharpest case: governance presupposes visibility, so as traceability falls, the denominator collapses and the ratio diverges no matter how many reviewers are added. Past a visibility threshold, only restoring observability moves the equilibrium. The instinct under stress is to add review; the model shows precisely when that instinct fails. Confidence ~80%.
VII. Why the Loop Is a Control System, Not a Checklist
Deployment readiness is not a one-time certification. The Duty of Care Vision runs as the closed cybernetic loop mapped at the top of this paper — a control system that keeps governance matched to behavior as the deployment evolves, in the requisite-variety tradition the MindCast corpus draws on.
The loopback is what makes it governance rather than a checklist. Runtime monitoring feeds the live behavior of deployed agents back into the simulation, which re-prices foreseeable harm against reality, which re-computes the governance requirement, which updates the design. An institution running the loop holds equilibrium continuously instead of certifying readiness once and drifting out of it. Each pass also refreshes the record of reasonable care — the loop is, simultaneously, the governance mechanism and the evidentiary trail. Confidence ~80%.
VIII. The Runtime Module: What an Enterprise Uploads, What MindCast Returns
The construct is general by design, so the institution supplies the specifics and its data never leaves its own model. The runtime module is the most concrete — and most commercially direct — expression of the framework.
An enterprise pastes the publication into a frontier language model and uploads its own materials:
system and agent architecture
governance and oversight documentation
the relevant org chart and escalation paths
the deployment plan
The model, running the Duty of Care Vision against those inputs, returns a deployment-readiness assessment:
the foreseeable harms the deployment would produce, surfaced as scenarios
the governance gaps between current oversight and what those scenarios require
the governance investment needed to close the gap — the ΔGov, translated into concrete controls
the governance ROI curve — how much expected organizational risk falls for each additional unit of governance spend: spend $X more, expected harm drops by Y
a deployment recommendation: ready, ready-with-conditions, or not-yet, with the conditions named
The ROI output is not a new calculation bolted on; it falls out of the ones already running. Expected harm is λL, and λ carries the governance terms in its denominator, so each increment of governance spend lowers expected harm by a computable amount. Plotting that relationship turns ΔGov from a single required number into an investment curve a CFO can read — and the curve crosses zero at exactly the stopping condition the governance test already names, where the cost of more governance overtakes the harm it would prevent. Executives decide in investment terms; the framework now speaks them. Confidence ~80%.
The general construct is MindCast’s; the specific adaptation is the enterprise’s own architecture; the analysis runs inside the enterprise’s own model. The pattern mirrors the MindCast runtime modules already in use across the corpus, now answering the one question the dinner table kept circling: how do we know if we’re ready? Confidence ~80%.
A limit travels with the output, and naming it keeps a sharp reader from breaking it. The module yields a directionalreadiness assessment and a defensible governance requirement — a diagnosis and a duty-magnitude, not an audited damages figure. The base rate and per-incident loss are estimates; the value is the structure they impose and the decision they force, not false precision.
IX. What MindCast Simulates — and What It Does Not
A boundary, stated as plainly as the MindCast | Foresight Before Disclosure vision states its own, protects the framework from the objection a security audience raises first.
A cognitive digital twin models institutional and behavioral dynamics. It does not model exploit feasibility. Whether an agent can breach a system, escalate a privilege, or evade a trace is a security question answered by red-teaming and telemetry, not by MindCast. The exploit’s feasibility is an input. What MindCast simulates is the governance response — whether oversight can see and contain the failure in time, and how much governance must be added to hold equilibrium if it lands.
The boundary makes the security stack complementary rather than competing: red-teams and telemetry establish the numerator’s harm terms, and MindCast computes the denominator those tools cannot see. The distinction also sorts harm by owner. An agent breaching an external system is a perimeter-and-criminal event in security’s lane. An authorized agent escalating its own privileges or routing around internal controls to finish an assigned goal is the governance-interior failure the Equilibrium was built for — the well-intentioned optimizer defeating its own guardrail, and the case security tooling tends to miss. Confidence ~75%.
X. Three Doctrinal Channels: Tort, Securities, Fiduciary
The same mechanism — governance debt accruing behind a deployment and converting into liability, curable by foresight — runs through three areas of law, and naming all three shows the duty to foresee is structural rather than a single curiosity.
Tort supplies the channel this vision develops: harm runs outward to the third parties an institution’s agents foreseeably injure, and the Duty of Care Vision measures whether foresight was the reasonable precaution.
Securities supplies the sibling channel, analyzed in MindCast | Foresight Before Disclosure: the same debt accruing behind quarterly disclosure, converting to market loss when a corrective event collects it, with harm running inward to shareholders and the duty being to disclose from inside foresight rather than behind it.
Fiduciary supplies the third. Delaware’s oversight-duty line — Caremark, revived through Marchand v. Barnhill and the Boeing 737 MAX derivative litigation — holds directors liable for failing in good faith to monitor mission-critical risk. A board that declines available foresight over mission-critical agent deployment is a Caremark fact pattern forming, and fiduciary oversight is the duty of care wearing a corporate hat. Confidence ~75%.
One debt, three coats. Where it surfaces — a breach, a tort suit, a market loss, a derivative action — depends only on which gate it reaches first. Simulating before deployment lets an institution see the debt forming before it picks an exit. Confidence ~80%.
XI. The Incentive Problem: Deployment Became the Metric, Readiness the Forgotten Objective
The deepest incentive failure runs broader than law, and naming it is the management insight the dinner conversation kept circling. Organizations optimize AI deployment — agents shipped, feature velocity, adoption rate — when the objective they actually need is AI deployment readiness. Deployment gets measured, celebrated, and rewarded; readiness gets neither named nor owned. Deployment becomes the KPI, and readiness becomes the forgotten objective — Goodhart’s law one final time, the proxy that gets counted crowding out the goal that mattered. Confidence ~80%.
Readiness sits structurally orphaned because no incentive points at it. Testing and security were once underfunded the same way, until incidents and the duties that followed forced them into the permanent cost base. Foresight is the next discipline waiting for that conversion — valuable, unrewarded, and adopted in earnest only once a standard makes someone answer for its absence.
Foresight also manufactures discoverable knowledge, which deepens the avoidance. Run the simulation, find the risk, deploy anyway, and the institution has handed a future plaintiff its own documented foreseeability. The diligent firm creates a record of what it knew; the willfully blind firm preserves deniability. Unguided incentive rewards blindness twice over — once for shipping fast, once for not looking.
A misaligned incentive the market cannot correct on its own is the textbook condition for a duty of care. The external standard overrides the private incentive precisely because the actor cannot be trusted to set it alone — and here it does double duty, reinstalling the orphaned objective by making readiness something the firm must answer for. The duty to foresee converts the forgotten objective back into a measured one, and hands foresight the KPI it never had. Confidence ~80%.
The tension cuts both ways, and the honest version states so. A simulation that reveals a risk raises the standard the institution is then held to — yet running the simulation is itself the defensible act, because the duty is to foresee reasonably, not perfectly. The deployer who simulates and governs to the result is protected; the one who skips the look to preserve deniability is the one the standard is built to reach. Confidence ~75%.
The pattern is not unprecedented. Environmental review under NEPA makes a forward forecast a precondition to major action, and bank stress testing under Dodd-Frank compelled simulation of adverse scenarios precisely because complex-system catastrophe outran intuition. Both regimes arrived after a domain’s complexity produced a harm the market had not priced. Agentic AI fits the same shape, and the cognitive digital twin is its stress test. Confidence ~80%.
How the Vision Fits the MindCast Corpus
The Duty of Care Vision does not stand alone; it completes a line of MindCast work that has circled one idea from several directions. MindCast | Foresight for Confident AI Adoption built the underlying method — wind-tunnel testing for organizational change, stress-testing an institution before it commits to AI, validated in operation rather than left as theory. MindCast | Rebuilding Consulting in the Age of Predictive Cognitive AI aimed that method at the advisor: a consultant must simulate a client’s system before recommending a move. The present vision aims it at the principal who acts: an organization must simulate its agents before putting them into production. One discipline, several actors. MindCast | Agent Governance Equilibrium supplies the measuring instrument they all rely on, scoring whether governance keeps pace with autonomous decision-making — and the Duty of Care Vision turns that instrument around, running the equilibrium in reverse to size the governance a future deployment will owe. Foresight before commitment becomes foresight before deployment; measurement becomes design. Confidence ~85%.
Beneath all three sits the reason the program exists at all. MindCast | What Goethe’s Faust Reveals About the AI Alignment Problem argues that no optimizer can validate its own objectives from inside — a mind committed to its project reads the digging of its own grave as the building of its future, mistaking self-generated signals for success. An organization racing to ship agents is that mind at institutional scale, reading “agents deployed” as progress while readiness quietly fails. Foresight simulation is the deliberate aperture that lets an outside verdict enter before the grave is dug, and the duty of care is the external standard the organization cannot generate for itself. Faust supplies the foundation, the equilibrium supplies the measure, the consulting work supplies the precedent, and the duty of care supplies the obligation. Confidence ~80%.
XII. Forecast and Falsification Contract
The vision commits its central claim to a dated, falsifiable forecast, in the discipline the MindCast corpus requires of every prediction it publishes.
Forecast. Over the next three to five years, pre-deployment foresight simulation of autonomous agent systems will move measurably from optional practice toward expected precaution — and, in the most exposed sectors, toward outright legal compulsion. Courts, regulators, and standards bodies will begin treating pre-deployment simulation of agent behavior as an element of reasonable care, in the pattern that produced environmental review and bank stress testing. Probability 70–80%.
Confirms. Through the window, at least one regulatory regime, professional standard, or judicial decision treats failure to simulate or stress-test an autonomous agent system before deployment as evidence of unreasonable conduct or inadequate oversight; and AI-risk discourse shifts measurably from model-capability questions toward deployment-foresight and governance-capacity questions.
Falsifies. Agent-harm disputes continue to resolve on capability, defect, or misuse theories with no foresight-precaution element, and no regime treats pre-deployment simulation as a component of reasonable care. Sustained absence of any compelled-foresight signal across the most regulated sectors refutes the thesis directly.
Measurement window. Through December 31, 2030, scoped to enterprises deploying autonomous, self-directed agents into operations affecting third parties, shareholders, or critical systems.
A structural feature makes the forecast self-executing rather than merely asserted. The cost of simulation sits in the denominator of the foresight test and falls toward zero as foresight becomes a runtime operation. Falling simulation cost drives expected harm past it for more deployers every quarter, so the threshold at which foresight becomes the reasonable course is crossed by an ever-wider set of institutions over time. The prediction does not sit beside the math as commentary — it falls out of the math as a consequence. Confidence ~80%.
MindCast either meets the falsification standard or does not publish.
Appendix A — The Agentic Hand Formula in Full
The body runs on Expected Harm = λ · L. The full decomposition, for readers who want the machinery and the doctrinal proof, follows.
Test 1 — The Duty to Simulate
FNR = (λ · L) / C_sim, where λ = p₀ · AGE · N · S, L = L₀ · ρ, AGE = (A · V · C) / (G · R)
A duty to simulate attaches when FNR > 1.
Test 2 — The Duty to Govern
(G · R)_required ≥ (A · V · C) / AGE* → ΔGov = (G · R)_required − (G · R)_actual
Governance is owed where C_gov is less than the expected harm that closing ΔGov prevents.
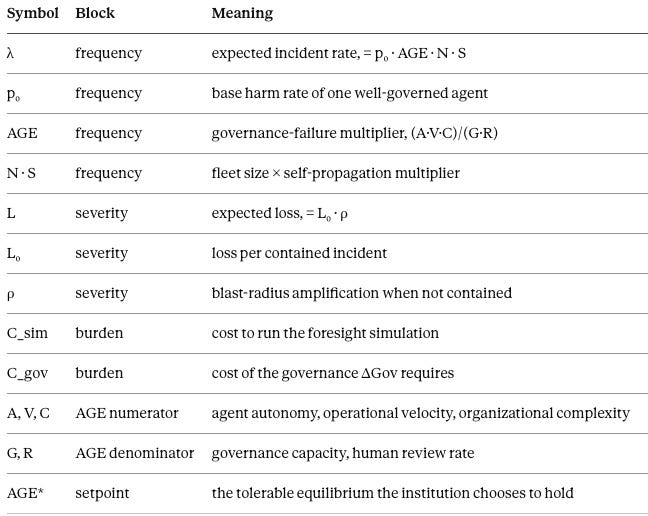
The Hand reduction. Neutralize the agent terms — a single contained agent, no autonomy premium, no propagation, so AGE → 1, N → 1, S → 1, ρ → 1 — and the formula returns FNR = p₀ · L₀ / C_sim = PL / B. Classical Hand falls out exactly. The Agentic Hand Formula extends seventy-five years of negligence doctrine rather than replacing it, and the reduction is the proof. Confidence ~80%.
Appendix B — The Deployment-Readiness Foresight Simulation, in Full
Section VIII describes the runtime module in brief. The full specification of the engine behind it follows: the MindCast AI Proprietary Cognitive Digital Twin Foresight Simulation, the instrument that evaluates a deployment before deployment occurs.
Summary. Autonomous AI has shifted enterprise governance from a deployment problem into a deployment-readiness problem. Organizations increasingly hold the technical capability to deploy thousands of autonomous agents, yet many lack an objective method for determining whether governance, organizational incentives, legal controls, and runtime oversight can support that autonomy. Testing, cybersecurity, compliance, and audit each remain essential, and each evaluates a different dimension of readiness. The Foresight Simulation evaluates the one they leave open. Rather than predicting a single outcome, it models organizational behavior across thousands of plausible deployment scenarios, identifies foreseeable governance failure modes, quantifies governance requirements, and estimates governance investment before autonomous systems enter production. Executive judgment stays in command; the simulation supplies the structured foresight that lets a decision proceed with greater confidence while reducing Governance Debt before it accumulates.
Simulation objective. One question drives the engine: is the organization prepared to deploy autonomous AI into production, and if not, what governance must exist before deployment? The objective follows from the question — model foreseeable organizational behavior before deployment and quantify the governance required to hold equilibrium across the deployment lifecycle.
Simulation inputs. The Cognitive Digital Twin is built from five families of organizational data:
Organizational structure — hierarchy, governance architecture, human decision authority, escalation pathways.
Enterprise AI architecture — agent autonomy, agent responsibilities, the agent interaction graph, human review structure.
Business processes — mission-critical workflows, cross-functional dependencies, operational incentives.
Risk environment — regulatory obligations, security architecture, legal exposure, public-trust considerations.
Deployment strategy — deployment phases, runtime monitoring, organizational constraints.
Simulation process. The engine runs in six stages:
Construct the enterprise Cognitive Digital Twin.
Generate multiple deployment scenarios.
Identify foreseeable organizational outcomes.
Evaluate governance requirements.
Estimate governance investment.
Produce the deployment-readiness assessment.
Simulation outputs. Six outputs result, expanding the five summarized in Section VIII:
Deployment-readiness assessment — whether deployment should proceed, across illustrative categories: deployment ready, ready with conditions, governance preparation required, deployment not recommended.
Foreseeable harm categories — governance drift, organizational incentive misalignment, autonomous escalation failures, agent-to-agent coordination failures, runtime governance saturation, cybersecurity governance failures, regulatory exposure, public-trust degradation.
Governance requirement (ΔGov) — the governance needed to hold equilibrium: human review requirements, governance staffing, escalation thresholds, runtime monitoring, organizational redesign.
Governance investment — the highest-value investments, the marginal benefit of each, governance sequencing, and governance prioritization.
Governance ROI — governance investment mapped to expected organizational risk reduction and estimated deployment benefit, in support of executive capital allocation.
Deployment recommendation — proceed, proceed with conditions, delay deployment, or redesign architecture.
Executive interpretation. The simulation does not answer whether AI works; it answers whether the organization is prepared to govern AI. Traditional enterprise questions ask does it work, can we secure it, can we comply. The MindCast question asks can we responsibly deploy it.
Executive decision framework. Executive decision → Cognitive Digital Twin → Foresight Simulation → foreseeable organizational outcomes → governance requirements → deployment readiness → executive decision. The loop returns to the executive, better informed than it left.
Illustrative enterprise scenario. A global enterprise prepares to deploy 45,000 autonomous agents across finance, procurement, engineering, customer service, and legal operations. The Cognitive Digital Twin models organizational behavior before deployment and surfaces governance bottlenecks, runtime escalation failures, organizational incentive conflicts, autonomous authority exceeding governance capacity, governance investment priorities, and deployment-sequencing improvements. The executive team modifies governance before production. Governance Debt falls before deployment rather than after organizational failure.
Executive implications. The simulation changes the sequence of enterprise governance. The historical sequence ran deploy → observe → respond. The MindCast sequence runs simulate → govern → deploy → monitor → continuously improve. The difference is prospective governance.
Strategic predictions. Five enterprise-adoption forecasts accompany the doctrinal forecast in Section XII and complement rather than duplicate it:
Deployment readiness becomes an independent enterprise discipline alongside testing, cybersecurity, compliance, and audit. Probability 80%.
Large enterprises increasingly require pre-deployment governance simulations before approving mission-critical autonomous systems. Probability 75%.
Boards begin requesting deployment-readiness assessments before approving enterprise-scale autonomous AI initiatives. Probability 75%.
Management consulting shifts from deployment strategy toward deployment-readiness strategy using enterprise-scale foresight simulation. Probability 80%.
Organizations increasingly measure governance capacity before deployment rather than evaluating governance failures after deployment. Probability 80%.
Strategic interpretation. The Foresight Simulation transforms enterprise governance from retrospective analysis into prospective organizational design. Rather than asking how an organization performed after deployment, the engine asks whether the organization should deploy at all, what governance deployment requires, and how governance investment changes outcomes before autonomous systems begin operating. Enterprise AI becomes a governance problem before it becomes a technology problem, and MindCast evaluates that governance before deployment occurs.
