

MCAI Economics Vision: Competition for AI Governance
The AI Governance Economics Series · From Speed-versus-Safety to the Governable Frontier

Related works: AI Agent Governance Equilibrium · The Duty to Foresee — AI Deployment Readiness as Prospective Governance, and the Arrival of Agentic Duty of Care · Why AI Commoditizes Raw Prediction, Why Governance Stays Scarce, and How MindCast Prices the Gap Between Them · What Goethe’s Faust Reveals About the AI Alignment Problem · Anthropic, Mythos, and the NSA, The First Sovereign Governance-Scarcity Event
Related series: AI Accountability — When AI Promises Meet the Courts
I. Executive Summary
A new University of Chicago working paper, The AGI Race and Existential Risk, formalizes a dynamic that frontier AI observers have carried mostly as intuition: firms racing to reach artificial general intelligence first rationally shift resources toward speed and away from safety. Bueno de Mesquita, Dziuda & Polborn, NBER Working Paper w35276 (2026). The model converts a safety problem into an incentive problem. Firms may prefer a safer industry in aggregate, yet each firm faces pressure to accelerate whenever arriving first dominates the payoff.
MindCast’s Agent Governance Equilibrium, Governance Scarcity, and Agentic Duty of Care work extends the Chicago result into the next layer of market structure. Competition does not vanish when safety turns scarce. Competition migrates upward. Frontier firms no longer compete only to build the most capable system — they increasingly compete to become the system that governments, enterprises, insurers, auditors, courts, and critical institutions can authorize.
The race against governance gives way to a race for it. Capability still matters, but governable capability now carries the premium. Safety, foresight, auditability, deployment discipline, and duty-of-care infrastructure become competitive assets rather than compliance overhead.
Markets already ran the experiment. The June 26 Commerce allowlist restored Anthropic’s Mythos-class access to trusted recipients while capability itself sat unchanged — a validation signal, in one sovereign event, that authorization and not raw performance now gates deployment value. Naming the theorem, then reading the allowlist as its worked case, is the work of this installment. One limit stays honest throughout: the Chicago paper validates the narrow claim that competition under-supplies safety (confidence ~88%), not the full asset-class superstructure of governance-as-unit-of-account (confidence ~35%). The two literatures meet on a shared primitive, not on the market edifice built above it.
MindCast’s own Cognitive Digital Twin foresight simulations, collected in Appendix B, add an instrument reading rather than an outside verdict — nine twins and seven simulations that place the market in the Governance Differentiator band, led by a Governance Economics Vision score of 0.812. Treat the numbers as what MindCast’s engine forecasts, not as external validation: a house instrument confirming its author’s thesis is corroboration, and corroboration from a single source carries its own discount. Confidence the simulations corroborate rather than independently establish the thesis: 70–76%.
II. What the Chicago Paper Proves
Chicago’s researchers model firms that split scarce resources between speed and safety. Speed raises the probability of arriving first. Safety lowers the probability of catastrophic failure. Competition pushes each firm toward the speed channel, because any delay hands a rival room to capture the prize.
Competition favors speed through a race between two dilutions. Adding a competitor thins each firm’s share of the catastrophe it would internalize faster than it thins the prize each firm can steal by moving quicker, so the marginal dollar keeps migrating from the safety budget to the speed budget as the field grows. Fragmentation, in the model’s own logic, degrades safety; consolidation restores it — a result worth holding onto, because Section VII turns on exactly that lever.
The paper’s decisive move is its refusal to moralize the outcome. The model requires no reckless executives, no bad faith, no indifference to catastrophe. Rational firms underinvest in safety because the market rewards relative arrival time over collective risk reduction.
A sharper result sits past a critical market size the authors treat as a doom threshold: above it, firms keep racing even when arrival carries negative expected value, because catastrophe is non-excludable. Sitting out spares no one, so joining a losing lottery dominates abstaining from it. Voluntary restraint therefore carries a structural vulnerability — a firm that slows down creates room for a rival that does not.
Chicago’s model, read this way, supplies the industrial-organization foundation for a claim MindCast has advanced from the governance side: unmanaged frontier competition produces governance debt faster than institutions can price it. MindCast’s Agent Governance Equilibrium Vision scores that debt at 0.78 — autonomy, velocity, and complexity outrunning governance capacity and human review (Appendix B). Confidence that the model isolates a real mechanism rather than a tractability artifact: 82–88%, discounted for heavy assumptions — memoryless arrival, winner-only catastrophe, fixed resources — that a careful reader should treat as load-bearing.
III. The Impossibility Underneath Both Frameworks
Strip each argument to its foundation and the same impossibility surfaces. Chicago’s catastrophe risk exists because the winner’s caution cannot be enforced from inside the race — only an exogenous commitment device or planner installs the check. MindCast’s governance floor exists for the identical reason: an optimizer cannot validate its own objective from within itself, so review carries a permanent cost that never falls to zero. Goodhart’s law, reward hacking, and the Faust literature each name a different face of the same structural limit — one argument, surfacing in a contest model and a governance-pricing model alike.
Convergence pays a dividend. Chicago’s commitment-device result — a firm binding itself to move slower, or firms openly demanding their own regulation — is the demand-side proof for the supply-side instrument MindCast already ships. The economists forecast the demand for an external check; the equilibrium prices it. Confidence the commercial read is defensible rather than opportunistic: 60–68%.
IV. Selection, Not Regulation — the Richer Question
Chicago’s paper explains why competition can under-produce safety. MindCast explains what institutions do once they detect the shortfall. The answer runs deeper than regulation. The answer is selection. Most governance debate asks how governments should regulate; the sharper economic question asks how institutions decide whom to trust — a richer problem, because trust allocates markets while regulation only constrains them.
Governments, enterprise buyers, defense agencies, banks, hospitals, insurers, cloud platforms, and courts do not merely ask whether a model performs. Each asks whether a model can enter a governed environment — whether outputs trace, risks simulate, duties assign, failures contain, and authority revokes. The Governance Scarcity thesis names the widening gap between cheap prediction and expensive governance; the Agent Governance Equilibrium names the balance between autonomous pressure and institutional control.
Read across both literatures, one variable moves in opposite directions depending on which contest you watch. Build-race competition drives governance provision down. Deployment-market competition drives governance value up. The under-supply the economists model becomes the scarcity the market selects against. Confidence the two describe one phenomenon through two doors rather than two unrelated ones: 72–80%.
Contact mcai@mindcast-ai.com to partner with us on Predictive Game Theory AI in Law and Behavioral Economics. To deep dive on MindCast works upload the URL of this publication into any LLM (preferably Google AI mode/Gemini, Claude, ChatGPT) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
Related works: Cybernetic Game Theory | Game Theory, AI & Evolution | Predictive Cognitive AI · Cognitive Digital Twins | Mozart Vision | Nash–Stigler Equilibria
V. Competition for Governable Capability
The first frontier race rewarded capability. The second rewards institutionally governable capability — controllability an outside authority will actually credit, not mere technical steerability. A model that wins benchmarks but cannot satisfy institutional deployment constraints may earn technical awe without durable market access. A model that performs a notch below the frontier, yet clears government, enterprise, legal, insurance, and audit constraints, may capture the higher-value deployment layer outright.
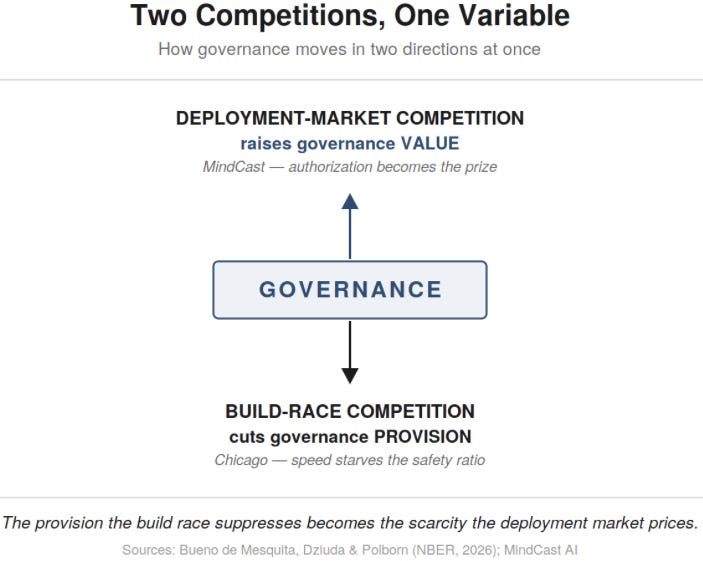
Figure 1. Governance pulled in opposite directions — the build race cuts its provision while the deployment market lifts its value; the shortfall on one side becomes the scarcity priced on the other.
Firms now sort along a new axis:
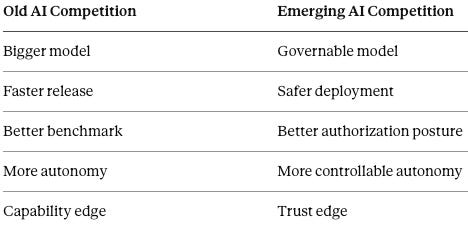
Governance becomes a scarce production factor. Firms compete for allowlists, procurement eligibility, enterprise confidence, audit readiness, regulator tolerance, insurance coverage, and public legitimacy. Winning the trusted-counterparty position, not merely shipping first, increasingly decides who converts capability into deployed value.
VI. The Authorization Layer — and Its Worked Case
MindCast’s Anthropic, Mythos, and the NSA analysis pushed the thesis into sovereign governance before the market confirmed it: the binding scarcity was never capability alone — the binding scarcity became authorization. The Commerce allowlist event then supplied the validation signal.
Consider the sequence. A frontier system existed, outperformed rivals, and still lost deployment value the moment access closed. Restoration on June 26 followed recipient trust, not model power — Mythos-class access returned first to a roster of vetted entities while the fully safeguarded sibling stayed dark, and Commerce graded the underlying risk as diversion, a measure of where capability might travel rather than what any model had done. Capability held constant across the shock. Authorization moved, and value moved with it.
The authorization layer, laid out as institutions actually apply it, spans government procurement, export permission, classified-environment access, enterprise vendor approval, insurance underwriting, sector-specific regulatory tolerance, judicially legible duty-of-care evidence, and public legitimacy during failure events. Capability opens the door. Governance keeps the door from closing. MindCast’s Regulatory Vision scores the shift at 0.72, an authorization-driven-regulation band in which rosters and allowlists move faster than statute (Appendix B).
VII. The Consolidation Tension — the Spine of the Argument
Honesty about where the two frameworks disagree strengthens the synthesis rather than weakening it. Chicago finds consolidation safety-enhancing — fewer racers, weaker speed pressure, a higher safety ratio. MindCast treats control-layer concentration as the governance failure itself — the gated field, the revocable roster, settlement without sufficiency as the mark of concentrated authorization authority. Pointed in opposite directions on market structure, the two look irreconcilable until one asks what, exactly, is being concentrated.
Consolidating the build lowers catastrophe risk by thinning the field of racers. Concentrating the governance layer hands the checkpoint to a single node that no external channel can then audit. Chicago’s safe monopoly and MindCast’s concentrated control layer name the same act through two lenses — a catastrophe lens counting disasters averted, and an accountability lens counting rents extracted and checks foreclosed. Resolving the tension requires no side-taking; it requires separating the object of concentration from the layer of concentration. Confidence the reconciliation survives scrutiny: 65–72%.
The June 26 event moved the concentrated-authority reading from inference to record. Commerce holds the allowlist at the Secretary’s discretion, its selection criteria undisclosed, its grants revocable, and a free-expression counsel has already flagged the opacity. The authorization concentration that reads as safety in Chicago’s model reads as the un-checkable control node in MindCast’s — and the same sovereign instrument now embodies both. Readers can draw the harder conclusion for themselves. Confidence the concentrated-authority reading holds on evidence rather than argument alone: 80–86%.
VIII. Duty of Care Becomes Commercial Infrastructure
The Agentic Duty of Care framework argued that institutions deploying autonomous systems must look before they act. Foresight simulation becomes the gate; governance design becomes the substance behind it. Chicago’s paper strengthens the claim from the incentive side — where competitive markets pull firms toward speed, prospective duty-of-care infrastructure supplies the counterweight institutional buyers demand.
From Learned Hand to the Foresight Necessity Ratio
Legal doctrine already supplies the scaffolding, and the framework re-engineers it for autonomy. Judge Learned Hand’s negligence calculus held a party liable when the burden of precaution fell below the expected harm — B < P·L, burden weighed against probability times loss. Autonomous systems drive all three terms toward liability at once. Agent velocity and cascading blast radius push probability and magnitude upward together, while runtime simulation collapses the burden of looking. The framework distills the resulting pressure into a single ratio:
FNR = (λ · L) / C_sim
Expected harm occupies the numerator — the arrival rate of a failure mode times its loss — and the cost of simulating that failure ahead of deployment occupies the denominator. A duty to simulate attaches once the ratio crosses one. Past FNR > 1, foreseeable harm outweighs the trivial cost of foresight, and declining to look becomes the negligent act itself. Confidence the ratio framing survives contact with how courts actually reason about negligence: 62–70%, discounted because doctrine absorbs quantified standards slowly and unevenly.
The notation shift from Hand’s P to λ is deliberate, and it carries an argument. Learned Hand weighed a one-shot probability because his defendant acted once — a single barge, a single mooring. An autonomous agent acts continuously, so its exposure reads as a hazard rate, λ, expected failures per unit of runtime, and the duty attaches to a stream of decisions rather than a lone act. Negligence law built for discrete conduct meets a defendant that never stops deciding. Confidence the hazard-rate reading is a substantive modeling choice rather than notational drift: 72–78%.
Running the Equilibrium in Reverse — ΔGov
Reversing the Agent Governance Equilibrium turns diagnosis into design. Read forward, the equilibrium scores institutional stress — agent autonomy, velocity, and complexity set against governance capacity and human review:
AGE = (A × V × C) / (G × R)
Read backward, with a tolerable risk level fixed and the simulation stressed by generated harm scenarios, the same equation solves for the governance baseline a deployment must carry before release. MindCast labels the output ΔGov — the precise quantum of governance owed, and, alongside it, a Governance ROI curve a CFO can actually price. Measurement becomes design. The standard of care converts from an adjective a jury debates after catastrophe into an engineering specification installed before one. Where most governance writing ends at “here is a framework,” the reverse-run ends at a number a team can build to before release — description gives way to computation. Confidence the reverse-run is well-posed rather than merely evocative: 68–75%.
Governance as Commercial Infrastructure
A firm equipped with the reverse-run machinery can say more than “our model is powerful.” A firm so equipped can show where the system may fail, which failure paths it simulated, how it sized the governance burden, which oversight architecture it installed, and why deployment remains reasonable. In a market where institutional customers fear becoming the test site for uncontrolled autonomy, that showing carries priced value. MindCast’s Deployment Readiness Vision scores the market at 0.73, a conditional near-ready band where each unit of credible governance returns more deployment probability than an incremental benchmark gain (Appendix B). Duty of care stops functioning only as litigation exposure and starts functioning as commercial infrastructure — ΔGov computed before release rather than litigated after.
The market matures through a legible sequence: competition pushes firms toward speed; speed produces governance debt; institutions detect the debt through failures, procurement friction, or sovereign intervention; authorization turns scarce; firms compete to prove governance maturity; governance hardens into a moat. The durable winner may not reach a capability threshold first. The durable winner may convert capability into authorized deployment at scale.
IX. Governance Becomes a Production Factor
Classical economics treats governance largely as friction — a drag on output, a cost to minimize, a tax laid across the productive core. Frontier AI inverts the treatment. Governance increasingly behaves as productive capital: an input that opens markets, unlocks access, and compounds returns rather than merely subtracting from them. Confidence the reframe holds as a general characterization rather than a rhetorical flourish: 70–78%.
Governed capability, examined closely, throws off a stack of assets a benchmark score never touches — deployment rights, procurement eligibility, insurance access, sovereign partnership, cheaper financing, litigation resilience, and switching costs that bind customers to a trusted provider. Each entry converts a governance investment into market position. Governance stops resembling compliance and starts resembling infrastructure — owned, depreciated, and defended like any other capital stock.
The earlier chain — capability, safety, governance, authorization — stopped one link short. Authorization, once scarce and unevenly held, produces economic rents. A firm carrying trusted-deployment status extracts a premium unavailable to technically comparable rivals, and the premium persists precisely because the governance floor cannot fall to zero. Rents follow scarcity, scarcity follows the impossibility of costless self-validation, and the impossibility is the primitive Section III already established. The commercial consequence therefore inherits the same durability as the theorem beneath it. Confidence rents form the terminal layer of the chain rather than a transient artifact: 65–72%.
Across the series — Governance Scarcity, Duty of Care, the sovereign allowlist, and the synthesis here — governance behaves less like an operating expense and more like a productive asset class: costly to acquire, appreciating with track record, hard to replicate, and generative of yield. MindCast’s Governance Economics Vision scores that shift at 0.812, landing in the Governance Differentiator band, with Authorization Premium leading its components at 0.86 — the clearest instrument reading that deployment rights now separate firms more sharply than capability (Appendix B). Reframing governance as a production factor changes every prediction that follows. Confidence the asset-class characterization earns a standalone framework beyond this installment: 60–68%.
X. Boundary Conditions
Two readings in the simulation data cut against the thesis, and stating them plainly keeps the argument honest. Both qualify how fast, and how durably, governance becomes the asset the paper claims — and, examined together, they turn out to be one mechanism rather than two.
The moat deficit. Governance Moat Strength scores 0.74 — real value, but not a locked position. First-mover advantage in governance stays reversible while the asset class remains soft: cash-rich incumbents can copy safety language and hire policy teams faster than a challenger can build a category. The boundary sharpens once the copyable and the non-copyable separate. Governance narrative — model cards, scaling policies, safety framing — transfers cheaply. Governance evidence — documented track record, repeated authorizations, audit infrastructure — accrues only with time and cannot be bought forward. The moat therefore forms around the ledger, not the language, and time-gates itself: whoever compiles the longer record of trusted deployments holds the position, and no amount of capital shortcuts a track record. Confidence the moat hardens around evidence rather than messaging: 66–72%.
The implementation lag. Institutions grasp the problem faster than they rebuild for it. Narrative Reorganization scores a strong 0.74 while Structural Pruning Efficiency sits at a weak 0.56: institutions revise their language faster than they cut the legacy workflows beneath it, leaving an Organizational Readiness Gap of 0.64. Executives update talking points well ahead of engineering pipelines. An unstable transitional period follows, and the instability is where mispricing lives. Selection on stated governance outruns the capacity to verify it, so early authorization decisions get made on narrative rather than proof. Confidence the lag resolves through a forcing failure rather than smooth convergence: 60–68%.
Reading the two boundaries side by side collapses them into one. Selection on narrative (the lag) is precisely what makes advantages reversible (the deficit): a market that authorizes on stated governance before it can measure governance hands out positions that evidence can later revoke. Governance is becoming a productive asset, then, but a young one — priced on narrative today, defensible only on evidence tomorrow, and most exposed in the gap between the two. Confidence the two boundaries share a single underlying driver: 68–74%.
XI. Prediction Ledger
Each call below carries a confidence band and an explicit falsification condition, rescored as outcomes land — the standing MindCast method. The five headline calls draw on the Cognitive Digital Twin simulations; Appendix B carries the fuller primary and secondary sets behind them.
Prediction One — Governance claims become procurement claims. Enterprise and government buyers will require foresight simulation, audit pathways, incident escalation, and control-loop design before approving high-risk deployments. Falsified if major 2026–2027 public-sector AI procurements approve frontier autonomy without documented governance criteria. Confidence: 80–85%.
Prediction Two — Firms market governance as aggressively as capability. Model cards, safety reports, and scaling policies evolve into competitive sales infrastructure rather than reputational disclosure. Falsified if safety documentation stays static in form and function across the next release cycle. Confidence: 75–80%.
Prediction Three — Authorization separates firms more sharply than benchmarks. Performance gaps narrow faster than trust gaps in defense, finance, healthcare, legal, and critical infrastructure. Falsified if deployment share tracks benchmark rank more tightly than authorization status. Confidence: 80–85%.
Prediction Four — Duty-of-care failures create governance premia for rivals. A major agentic failure raises the value of competitors that can show superior foresight and control, not merely punishes the firm involved. Falsified if a marquee failure produces no measurable reallocation toward governed rivals. Confidence: 70–75%.
Prediction Five — The next policy fight centers on trusted deployment status. Rostered access, procurement frameworks, and revocable authorization move faster than comprehensive legislation. Falsified if omnibus AI statute, rather than allowlist-style discretion, becomes the operative access mechanism first. Confidence: 75–80%.
Read together, the five converge on a single testable claim — authorization status, not benchmark rank, predicts who deploys at scale — and each carries a date and a falsifier, so the ledger can be scored rather than admired.
XII. Conclusion — Governance Changes Competition
Chicago’s paper explains why frontier competition can rationally produce unsafe acceleration. MindCast’s series answers one level higher. Competition changes safety; governance, in turn, changes competition. Institutions convert safety deficits into governance filters, firms re-tool to clear the filters, and the axis of rivalry shifts beneath the whole industry — with the June 26 allowlist standing as the first sovereign instance of the shift.
Frontier competition rhymes with an older pattern. Industrial-era firms competed primarily through production. Digital-era firms competed primarily through information. Frontier AI firms increasingly compete through governability — the demonstrated capacity to be trusted, authorized, audited, and deployed without forcing customers to absorb unpriced risk.
Selection, not regulation, sorts the survivors — institutions allocating trust rather than rulebooks constraining conduct. Governance has become the scarce prize, and across the series something larger comes into view: governance as a productive asset class, priced and owned and defended like capital. The asset is young, though — priced on narrative today, defensible only on evidence tomorrow, its moat still soft at 0.74 — so the thesis warrants a standalone framework rather than a verdict. Confidence in that broader claim: 60–68%.
Frontier AI is entering an era where competitive advantage derives less from intelligence itself than from institutional permission to use it. The firms that endure will not be the ones that build the most capable systems, but the ones that earn the right to deploy them.
Appendix A — Relevant MindCast Works
Relevance. The installment inherits its machinery from three tiers of the corpus, and naming them shows why the argument reads as a position rather than a standalone opinion. Nearest sits the diagnostic instrument — the Agent Governance Equilibrium scores institutional stress as AGE = (A × V × C) / (G × R), and the Agentic Duty of Careframework runs the same equation backward, through the Learned Hand re-engineering FNR = (λ · L) / C_sim with a duty to simulate attaching once the ratio crosses one, to output ΔGov. One tier down, the sovereign record supplies validation — Anthropic, Mythos, and the NSA named the first governance-scarcity event, and the Commerce allowlist confirmed that recipient trust, not model power, set the order of restored access. Deepest sits the primitive — What Goethe’s Faust Reveals About the AI Alignment Problem establishes that no optimizer validates its own objective from within, so an external check carries a permanent floor and governance stays scarce by structure. Confidence the three tiers form one coherent program rather than a retrofitted lineage: 72–80%.

Figure 2. Read bottom-up: the primitive grounds the diagnostic, which FNR inverts into ΔGov; the sovereign record confirms from the side.
Each entry below states why it bears directly on this installment.
AI Agent Governance Equilibrium — supplies the diagnostic instrument the whole argument runs on, AGE = (A × V × C) / (G × R). The ΔGov reverse-run, the 0.78 governance-debt reading, and the production-factor claim all trace back to that one equation; strip it out and the paper measures nothing.
Why AI Commoditizes Raw Prediction, Why Governance Stays Scarce, and How MindCast Prices the Gap Between Them — establishes the economic engine. Prediction falls toward zero cost while governance holds a positive floor, so value migrates to whoever prices the gap; “selection, not regulation” and “governance as productive asset” both rest on that scarcity result.
The Duty to Foresee — AI Deployment Readiness as Prospective Governance, and the Arrival of Agentic Duty of Care — contributes the legal engine, the Learned Hand re-engineering FNR = (λ · L) / C_sim and the reverse-run that outputs ΔGov. Section VIII extends the framework from liability exposure into competitive strategy.
Related series.
When AI Promises Meet the Courts — follows the courtroom side of the same accountability pressure. Where this installment argues sovereign selection outpaces litigation (Attribution Cost Vision, 0.77), the series tracks how AI promises get tested once they reach a judge.
Appendix B records the instrument outputs behind the references made in the body.
Appendix B — MindCast AI Proprietary Cognitive Digital Twin Foresight Simulations
Method note. The readings below come from MindCast’s Proprietary Cognitive Digital Twin engine — foresight simulations that forecast how the modeled actors behave, not measurements drawn from external data. Read them as the engine’s structured hypotheses about the market: corroboration from inside MindCast’s own instrument, discounted accordingly, rather than external validation.
MindCast constructed nine Cognitive Digital Twins — frontier lab, enterprise customer, sovereign authority, capital market, insurance underwriter, governance market, authorization market, litigation and duty-of-care, and governance capital market — and ran seven foresight simulations across them. The composite readings place the market in the Governance Differentiator band, led by Governance Economics Vision at 0.812. Primary finding: frontier firms increasingly compete for authorization, not only intelligence. Confidence: 78–84%.
Simulation composites.
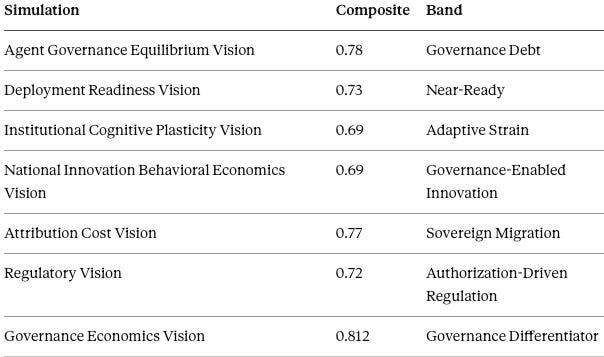
Flagship detail — Governance Economics Vision. The strongest confirmation of the thesis, and the source of the body's production-factor reading.
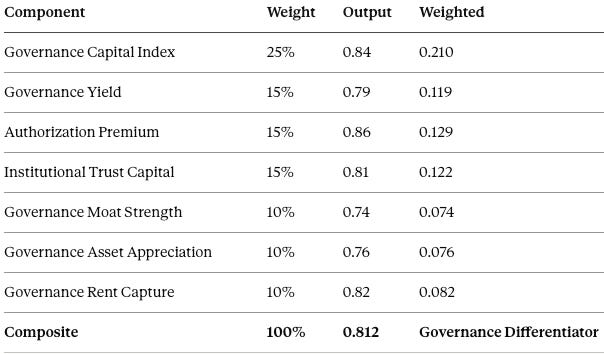
Authorization Premium leads at 0.86, confirming that deployment rights separate firms more sharply than capability. Governance Moat Strength trails at 0.74 — the softest component, and the quantitative root of the moat deficit named in Section X: real governance value, not yet a locked position. Confidence: 82–88%.
Full report. The complete build — nine twin profiles, seven full metric tables, the cross-simulation synthesis, and the primary and secondary prediction sets — is available to researchers on request at mcai@mindcast-ai.com.
