MCAI Innovation Vision: The Inference Economy— How the TPU Bifurcation Repriced the AI Compute Stack
The market is still pricing AI as a training problem. Google just priced it as an inference business.

Executive Summary
AI compute has split into two economic layers, and Google just made that split explicit. On April 22, 2026, Google announced that the eighth generation of its tensor processing unit will ship as two distinct chips — the TPU 8t for training and the TPU 8i for inference — ending a decade of unified TPU architecture (CNBC, Google launches training and inference TPUs in latest shot at Nvidia). Industry coverage framed the announcement as a product launch and a competitive shot at Nvidia. That framing misses the structural event.
The bifurcation is a control-surface move. Google is closing the last open loop in its AI stack — the Nvidia dependency for inference workloads — at the moment AI’s economic center of gravity is shifting from training capex to inference opex. Training is prestige. Inference is profit. And agent architectures convert inference from a query cost into a loop cost, multiplying demand non-linearly.
Three structural consequences follow. First, Nvidia’s moat — long understood as CUDA-plus-GPU — is geometrically weaker at the inference layer than at training, because inference workloads are more portable and less CUDA-dependent. The TPU 8i is not a symmetric competitor to Nvidia’s Blackwell; it is a targeted strike at the layer where Nvidia’s lock-in is structurally thinnest. Second, the supply-chain architecture — Broadcom designing the training chip, MediaTek the inference chip, TSMC fabricating, Intel and Marvell rounding out the stack (Implicator.ai, Google splits TPU 8 to chase Nvidia on inference cost) — reveals distributed design with centralized integration: execution risk spread across multiple ASIC partners while Google retains workload ownership. Third, Meta’s multibillion-dollar TPU commitment, made despite Meta’s own MTIA silicon program (Yahoo Finance / Bloomberg, Google developing inference AI chips to rival Nvidia), is the load-bearing adoption signal: sophisticated counterparties with alternatives are choosing TPU economics anyway.
The forward prediction is directional and time-bounded. Inference cost per token declines faster than consensus expects through 2027. Nvidia’s pricing power compresses at the inference layer before it compresses at training. Hyperscaler cloud competition resolves on first-party model-silicon co-design rather than raw chip availability. Nvidia is not displaced; the market bifurcates, and reprices both sides asymmetrically. Section VIII disaggregates what that means for investors, adopters, and strategic buyers.
The thesis fails if CUDA-at-inference lock-in proves stickier than the workload-portability argument predicts, if TPU 8i performance claims do not translate to real-world deployment economics, if Nvidia closes the architectural gap before multi-silicon ecosystems mature, or if Meta’s TPU commitment proves narrower than reported and does not generalize.
Core Thesis
AI infrastructure has entered a bifurcated regime where inference, not training, determines long-term value capture. Training remains episodic and prestige-weighted. Inference is recurring, agent-scaled, and economically compounding. Google’s TPU split formalizes the shift. Nvidia’s response — an inference roadmap aligning with the SRAM-heavy, low-latency architecture pioneered by independent inference specialists like Groq and Cerebras (CNBC, Google launches training and inference TPUs in latest shot at Nvidia) — validates it. The competitive question is no longer architectural. It is execution under constraints: cost, energy, software integration, and customer lock-in. Capital, procurement, and stack-design decisions made in 2026 will be evaluated in 2028 against inference-economics benchmarks that did not exist in 2024.
I. The Regime Shift: From Unified Compute to Bifurcated Architecture
AI compute has split into two distinct economic layers, and the TPU 8t/8i announcement is the first explicit institutional acknowledgment that unified accelerators no longer match workload reality. For a decade, the TPU program produced general-purpose AI silicon on the assumption that training and inference shared enough architectural requirements to justify shared hardware. That assumption held while training dominated AI spending and while inference workloads were bounded by episodic user queries. Neither condition holds in 2026.
Per Google’s own account, the architectural split was in development for two years — a decision made before the agent-deployment boom, not reactive to it (Implicator.ai, Google splits TPU 8 to chase Nvidia on inference cost). That timing matters. This is not Google responding to market pressure; it is Google pricing in a structural shift that the rest of the market is still catching up to. The event to analyze is not the chip. The event is the acknowledgment that the AI compute market has bifurcated.
II. Training Is Prestige, Inference Is Profit
The economic asymmetry between training and inference is the load-bearing claim of this piece, and it is underappreciated because the public narrative around AI is still dominated by training milestones — model size, benchmark scores, frontier capability. Those milestones are real, but they are capex events, not revenue events. Training is a one-time cost per model generation. Inference scales linearly with usage and compounds with agent deployment. The unit economics of every AI product — consumer or enterprise, agentic or static — are dominated by inference cost at steady state.
A five-column comparison makes the asymmetry concrete:
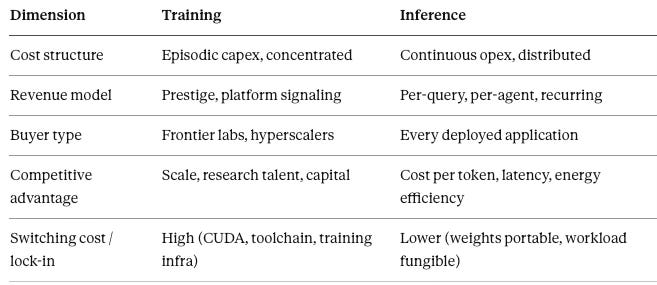
The fifth column is the one most analysts omit and the one that carries the most predictive weight. CUDA lock-in was built for a training-dominant world. Developers spend their model-building time in CUDA environments, which is why the ecosystem stickiness is real at training. Inference, by contrast, is predominantly matrix operations against fixed weights — a workload profile that is far more portable across silicon architectures. The moat does not transfer cleanly from one layer to the other. The market will price the right column, not the left.
Agent architectures sharpen the urgency. A traditional inference workload is a query cost — one user request, one model response, settled. An agent workload is a loop cost — a single user goal triggers dozens or hundreds of inference calls as the agent reasons, plans, retrieves, and acts. The economic asymmetry between training and inference compounds non-linearly as agent deployment scales, which is why the inference-economics question is not a 2028 concern. It is a 2026 procurement decision with 2028 consequences.
III. The Nvidia Moat and Its New Boundary
Nvidia dominates the current AI cycle. That fact is not in dispute and will not be in dispute in the near-term window of this analysis. IoT Analytics estimates Nvidia controls roughly 92% of the data center GPU market (The Motley Fool, Google Unveils 2 New AI Chips to Take on Nvidia), and no combination of TPU, Trainium, Maia, or MTIA adoption changes that in the 6–12 month window. The question this section addresses is narrower and more forward-looking: where is Nvidia’s moat structurally bounded, and what does the architectural convergence between Nvidia’s inference roadmap and Google’s TPU 8i tell us about where the bounding occurs.
Nvidia’s recent disclosures around inference-optimized hardware reveal that Nvidia has resolved the same architectural question in the same direction as Google. Google’s TPU 8i carries 384 megabytes of SRAM per chip, triple the amount in the prior-generation Ironwood TPU (CNBC, Google launches training and inference TPUs in latest shot at Nvidia); Nvidia’s inference roadmap is converging on the same SRAM-heavy, low-latency design primitives that independent inference specialists Groq and Cerebras have pursued for years. When the dominant incumbent and the principal challenger agree on the design primitives, the competitive surface shifts from “what to build” to “who executes it better and at what cost.” That is a different kind of competition than the one Nvidia has been winning. It privileges manufacturing scale, supply-chain depth, and customer lock-in at the stack level — not GPU-specific software advantages.
The moat is not gone. It is bounded. And the boundary sits precisely where the economic value is migrating.
Contact mcai@mindcast-ai.com to partner with us on Predictive Law and Behavioral Economics + Game Theory Foresight Simulations. To deep dive on MindCast upload the URL of this publication into any LLM (preferably ChatGPT or Gemini for magazine style works) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
About MindCast AI
MindCast is a predictive behavioral economics and game theory artificial intelligence firm specializing in complex litigation, geopolitical risk intelligence, and innovation ecosystems. MindCast publishes falsifiable institutional foresight analysis at mindcast-ai.com.
See relevant works: MindCast Files Provisional Patent Application on Multi-Agent Institutional Simulation Architecture | How MindCast Evolves the Structural Gaps in Classical Nash Game Theory
IV. Collapse the Stack: Google’s Cybernetic Closure
Google’s pre-announcement AI stack contained one open loop. Gemini was the model layer, Google Cloud was the infrastructure layer, TPU was the training silicon layer — and Nvidia GPUs served the inference layer for Google’s cloud customers and, to a meaningful extent, Google’s own workloads. The TPU 8i closes that loop. Every layer of the stack, from model to silicon, is now either designed by Google or designed under Google’s specification. That is not vertical integration in the Apple sense; it is cybernetic closure in the control-theory sense — every feedback loop that affects cost, latency, and capability now runs through systems Google controls. The architectural logic tracks the feedback-system framework developed in MindCast’s foundational cybernetics work (The Cybernetic Foundations of Predictive Institutional Intelligence).
The consequence is not that Google becomes cheaper than Nvidia on a per-chip basis. The consequence is that Google’s cost curve, latency envelope, and capability roadmap become independently tunable. Google can subsidize inference to win cloud market share, optimize Gemini-on-TPU co-design in ways no external model can match, and route around supply constraints that would bind a GPU-dependent competitor. Per Sundar Pichai, the TPU 8i architecture is designed to deliver the massive throughput and low latency needed to concurrently run millions of agents cost-effectively (CNBC, Google launches training and inference TPUs in latest shot at Nvidia). The comparable closures at AWS (Trainium plus Inferentia plus Anthropic) and the incomplete closure at Microsoft (Maia plus OpenAI-still-on-Nvidia) define the three-way competitive structure. Microsoft is the structurally exposed incumbent, because its distribution strength depends on a model partner whose silicon dependency points the wrong way.
V. Supply Chain as Strategy, Not Logistics
The supply-chain architecture disclosed alongside the TPU 8t/8i launch is strategically informative in a way that the performance specs are not. Broadcom is the reported design partner for the training chip. MediaTek is the reported design partner for the inference chip. TSMC fabricates both. Intel and Marvell occupy adjacent positions in the stack (Implicator.ai, Google splits TPU 8 to chase Nvidia on inference cost). This is not vertical integration. It is distributed design with centralized integration — a meaningfully different architecture from both Nvidia’s more centralized ecosystem and Apple’s fully internalized silicon program.
Distributed design spreads execution risk across multiple ASIC partners while keeping Google at the top of the value chain as the workload owner and systems integrator. If Broadcom’s training-chip execution slips, MediaTek’s inference-chip timeline is not affected. If TSMC capacity tightens, Google’s negotiating position is stronger as a multi-chip buyer than it would be as a single-chip customer. A TPU 8t superpod scales to 9,600 liquid-cooled chips delivering 121 exaflops, knit together by 2 petabytes of shared high-bandwidth memory — double the interchip bandwidth of the prior Ironwood generation (Implicator.ai, Google splits TPU 8 to chase Nvidia on inference cost). The structure also signals volume expectations: companies do not distribute design across this many partners for limited-run products. The supply chain is telling us Google expects TPU 8t/8i to ship in quantities that justify multi-partner ASIC investment, which means Google’s internal demand forecast for the next 24–36 months is substantially larger than the external market has priced in. The framework for reading control positions as competitive and potentially antitrust-relevant signals is developed in Infrastructure Routing Control: The Operative Antitrust Trigger in AI Energy Markets (CPI Antitrust Chronicle, April 2026).
VI. Demand Validation: From Internal Tool to External Platform
Customer lists are information only if they are parsed by informational weight. The TPU 8t/8i announcement arrived with a customer list that includes Citadel Securities, the U.S. Energy Department’s 17 national laboratories, and Meta (CNBC, Google launches training and inference TPUs in latest shot at Nvidia). These are not equivalent signals.
Citadel and the national labs are validation but not decision-grade. They tell us TPUs are production-viable for sophisticated quantitative and scientific workloads, which was largely already known. The load-bearing signal is Meta. Meta has its own MTIA silicon program, publicly committed to, multi-year invested in, and strategically important to Meta’s AI independence thesis. Meta’s decision to commit multibillion dollars to Google TPUs despite having an internal alternative (Yahoo Finance / Bloomberg, Google developing inference AI chips to rival Nvidia) is the informational event. The principle: when a buyer with a real internal alternative commits externally, the external offer has crossed a threshold that internal projects have not. That threshold is what justifies dedicated silicon investment, because it demonstrates that the economics are sufficient to override the strongest counterweight — not-invented-here preference combined with strategic-independence motivation.
The demand profile shift — from Google’s own workloads, to research and quant users, to hyperscaler peers — is the progression that justifies the supply-chain architecture described in Section V. Each customer tier locks in future utilization at a different scale. Meta locks in scale that changes the economics of TPU production overall.
VII. The New Competitive Variable: Inference Economics
Once the bifurcation is acknowledged, the metrics that define competitive advantage change. Training FLOPS, model parameter counts, and benchmark leadership were the metrics of 2022–2024. They will continue to matter for the training segment of the market, but they are not the metrics that determine inference-layer market share. The metrics that matter in the new regime are narrower and more operational: performance per dollar per query, latency per agent loop, and energy per inference at steady-state utilization. Google’s reported benchmarks — TPU 8t delivering 2.8x better price/performance than Ironwood on training, TPU 8i delivering 80% better performance per dollar on LLM inference (The Register, Google dual tracks TPU 8 to conquer training and inference) — are the disclosures that matter for this regime.
These metrics privilege integrated stacks over best-of-breed component assembly. They reward workload-silicon co-design over general-purpose performance. They disadvantage buyers who cannot amortize inference infrastructure across sufficient query volume, which means small-scale AI deployments will increasingly route through hyperscaler APIs rather than self-hosted inference. The winners at the inference layer will be the companies that can report declining cost-per-token curves quarter over quarter, not the companies that can report the highest benchmark scores on frontier models. These are different skills, different org structures, and different capital allocation disciplines.
VIII. Stakeholder Implications: Investors, Adopters, and Strategic Buyers
The bifurcation reprices different stakeholders asymmetrically. A single recommendation does not fit all readers of this analysis. This section disaggregates.
For investors. Nvidia remains the dominant position through the near-term window, but the forward pricing question is whether current multiples reflect sustained pricing power across both training and inference or only across training. If the bifurcation thesis is correct, Nvidia’s inference-layer margins compress first, while training-layer margins hold. Investors should watch inference-specific disclosures in Nvidia quarterly reporting — product mix shifts, average selling prices by product line, and customer concentration in hyperscaler inference workloads. Alphabet’s repricing is the inverse: current multiples may underweight TPU as a revenue line because it has historically been treated as infrastructure capex rather than a competitive product. At current multiples — roughly 31 times earnings for Alphabet versus 41 times for Nvidia (The Motley Fool, Google Unveils 2 New AI Chips to Take on Nvidia) — the repricing surface is asymmetric. If TPU 8t/8i adoption follows the Meta signal pattern, Google Cloud’s margin structure improves materially and the Alphabet valuation gap relative to Nvidia narrows. Broadcom and MediaTek benefit from volume; TSMC benefits regardless. The structurally exposed name is Microsoft — the Maia program is behind, and the OpenAI partnership is a distribution asset that becomes a silicon liability if OpenAI’s Nvidia dependency persists into an inference-cost-compressed environment.
For potential adopters — the “Google or Nvidia” question. Most enterprise adopters framing the decision as a binary between Google TPU and Nvidia GPU are asking the wrong question. The correct question is workload-specific. For training workloads — model fine-tuning, custom model development, research — Nvidia remains the default, and the CUDA ecosystem advantage is real for the next 24–36 months minimum. For inference workloads at scale — production agent deployments, high-volume API serving, latency-sensitive consumer applications — the calculus now genuinely favors TPU 8i or equivalent specialized silicon on cost-per-query and energy-per-inference grounds. For enterprises running mixed workloads, the operational answer is multi-silicon: training on Nvidia where toolchain matters, inference on TPU or Trainium where unit economics dominate. This is not a hedge; it is the correct architecture for the bifurcated regime. The implementation friction is real — compiler and framework support across silicon is still maturing, and the PyTorch-on-TPU developer experience lags PyTorch-on-CUDA — but the friction is declining and the economics differential is widening.
For strategic buyers seeking the next advantage. The readers who will extract the most value from this analysis are the ones looking past the Google-versus-Nvidia frame entirely. Three second-order moves deserve attention. First, verifiable inference — cryptographic attestation of model outputs, proof-of-inference protocols, and the infrastructure to audit agent behavior at scale — becomes a real market when inference economics determine AI value capture. The buyers who position in that layer now are buying optionality on a category that does not yet fully exist. Second, inference-optimized networking and memory fabric — the interconnect layer between inference silicon and model weights — is where the next round of architectural innovation will occur, and the current incumbents in that layer are not the companies that dominate GPU interconnect. Third, first-party model-silicon co-design partnerships — the equivalent of the Anthropic-Trainium relationship at AWS — are the structural advantage that is hardest to replicate. Enterprises that can negotiate preferred co-design access with a hyperscaler silicon program capture a cost advantage competitors cannot match at any price.
For Microsoft specifically. The company’s position in this analysis deserves direct treatment because the standard three-way cloud framing obscures a structural asymmetry. Microsoft has the strongest distribution position of the three hyperscalers through Office, Azure enterprise relationships, and the OpenAI partnership. But Microsoft’s silicon program (Maia) is the least mature, and Microsoft’s flagship model partner (OpenAI) is the most Nvidia-dependent of the frontier labs. If inference economics compress as predicted, Microsoft faces a choice: accept margin pressure on Azure AI services, force OpenAI onto Maia co-design (which OpenAI has resisted), accelerate internal model efforts (MAI) to frontier capability (which has not happened), or restructure the OpenAI relationship. None of these paths are easy. All of them are slower than Google’s and AWS’s parallel stack-closure moves. This is the most important non-consensus call in the piece.
IX. Forward Lock: Predictions, Timeline, Falsification
Predictions. Inference optimization becomes the dominant driver of AI infrastructure value. Integrated stacks gain share through cost and latency advantages. Market competition shifts from chip capability to system-level efficiency. Hyperscaler valuation gaps narrow as TPU and Trainium contributions become legible to public-market analysts.
Timeline. In the 6–12 month window, price competition in AI APIs intensifies, inference-layer ASP compression becomes visible in Nvidia disclosures, and Meta-pattern adoption announcements from other hyperscaler-adjacent buyers appear. In the 12–24 month window, inference-specific silicon adoption accelerates beyond first-party workloads into broader enterprise deployment, CUDA-at-inference becomes a legacy concern for new deployments rather than a current constraint, and compiler and framework support across TPU/Trainium reaches parity with CUDA for inference-class workloads. In the 24–36 month window, market leaders are defined by inference economics rather than training scale, first-party model-silicon co-design becomes the default architecture for serious AI deployments, and the cloud competitive structure stabilizes around Google and AWS as integrated-stack leaders with Microsoft’s position contingent on resolution of the OpenAI silicon-dependency question.
Falsification conditions. The thesis fails if any of the following hold. First, if CUDA-at-inference lock-in proves stickier than the workload-portability argument predicts, specifically if developer inertia and existing inference infrastructure keep Nvidia’s inference market share above 80% through 2027. Second, if TPU 8i’s performance and cost claims do not translate to real-world deployment economics — if the 80% performance-per-dollar improvement proves to be a benchmark artifact rather than a production reality. Third, if Nvidia’s inference-optimized roadmap closes the architectural gap before multi-silicon ecosystems mature, restoring Nvidia’s inference moat through execution rather than architecture. Fourth, if Meta’s TPU commitment proves narrower than reported — if the multibillion-dollar figure reflects specific workload contracts rather than a general infrastructure shift, and if no other sophisticated buyer with an internal silicon alternative follows the Meta pattern within 12 months.
Good foresight names its own failure conditions. These are the four I would track. If inference cost curves fall faster than expected, AI adoption accelerates not linearly, but multiplicatively — and the convergence with agent deployment, post-quantum migration, and verifiable-inference market formation pulls forward on the same curve.
Convergence Note
This analysis connects to the three-clock thesis developed in prior MindCast publications on AI × Quantum × Blockchain convergence. The acceleration of inference economics pulls forward the agent-deployment timeline, which expands the cryptographic attack surface faster than the post-quantum migration timeline anticipated. Second-order: verifiable inference becomes a real market, which is where the blockchain clock re-enters. The full framework — including the three-clock capture model, the CDT-plus-quantum-resistant-verification product surface, and the multiplicative-versus-additive convergence test — is developed in the MindCast Convergence Vision corpus.
Related MindCast Research
The Cybernetic Foundations of Predictive Institutional Intelligence — intellectual lineage from Wiener through Hayek to MindCast; the feedback-system framework underpinning the cybernetic-closure argument in Section IV.
Predictive Institutional Cybernetics — Constraint Geometry, Runtime Geometry, and Causal Signal Integrity; the methodological base for reading the TPU bifurcation as a control-surface event rather than a product launch.
From Cybernetic Proof to Simulation Infrastructure — adoption-threshold argument applied to institutional foresight; the model for why Meta’s TPU commitment is a threshold-crossing signal rather than a product endorsement.
MindCast Predictive Cybernetics Suite — umbrella reference integrating the three foundational installments into a unified runtime architecture.
MindCast AI Constraint Geometry and Institutional Field Dynamics — constraint geometry as a framework for identifying where bottleneck control converts into durable competitive advantage; applied in Sections V and VIII to supply-chain and stakeholder analysis.
Runtime Geometry: A Framework for Predictive Institutional Economics — the runtime-versus-event distinction that underwrites the Section II argument that training is an event and inference is a runtime.
AI Infrastructure Energy Series — Opportunity Landscape and Antitrust Landscape — compute-energy stack analysis that contextualizes TPU 8t/8i within broader AI infrastructure constraints; the antitrust-risk framework directly relevant to how hyperscaler silicon consolidation will be read by enforcement authorities.
Infrastructure Routing Control: The Operative Antitrust Trigger in AI Energy Markets — CPI Antitrust Chronicle, April 2026 — routing-control framework applied to infrastructure dependency chains; the analytical precedent for reading Google’s stack closure as a competitive and potentially antitrust-relevant structural position.