

MCAI Economics Vision: Prediction Markets Reveal Truth— Feedback Loops Determine It
How Feedback Latency, Cost, And Clarity Determine Whether Systems Converge To Truth Or Narrative

Executive Summary
Prediction markets appear to produce truth. Feedback loops actually do. Accuracy does not originate from the market format — it emerges from feedback loops that impose cost, compress signal, and force rapid updating. Amateur economists point at a betting pool, a fantasy league, or a bar argument settled with cash and call it a prediction market. The framing collapses important distinctions. Not every wagered expectation produces actionable intelligence.
The governing question this paper answers is not whether prediction markets work. The question is: when will reality force a system to update? Hedge funds use that question to front-run corrections. Regulators use it to understand why problems persist until they explode. Venture investors use it to distinguish companies that look right because feedback hasn’t closed yet from companies that are right. Tech executives use it to identify where AI narrative has outrun reality in their own stack. Prediction market operators use it to understand their ceiling. Each of those readers will find the diagnostic they need in the feedback integrity framework developed here.
Expectation markets already govern capital allocation, hiring, regulation, narrative formation, and strategic behavior. Every actor forms expectations, commits resources, and faces eventual resolution. Most operate without explicit pricing, yet they still function as markets. Fragmentation, delay, and weak accountability degrade their signal quality.
Feedback integrity determines whether a system converges toward truth or drifts into narrative. Systems with fast, costly, and clear feedback loops punish error and reward calibration. Systems with delayed, diffuse, or manipulable feedback loops allow mispricing to persist and compound.
Prediction markets represent engineered environments where feedback loops operate with minimal distortion. Those systems do not create intelligence. They enforce accountability. Their limitations reveal the broader problem: high-impact domains often operate with weaker feedback loops despite commanding greater influence.
Opportunity sits in feedback engineering rather than market creation. Institutions that shorten feedback latency, increase error cost, and clarify signal extraction will outperform systems that rely on narrative persistence. Meta-systems that measure feedback integrity across domains gain leverage by identifying where expectations diverge from eventual outcomes.
One term requires a precise definition before the analysis proceeds. Truth, in this framework, refers to signals that survive feedback. When actions based on a signal produce consistent outcomes under repeated testing, the system has converged to truth. Narrative, by contrast, refers to signals that have not yet survived feedback — beliefs that persist because loops remain open, not because the underlying claim has been validated. Mispricing is the divergence between a system’s current expectation and the feedback-stable state it has not yet reached. Correction is forced alignment with truth when feedback compresses.
I. What a Prediction Market Actually Is — and What It Is Not
Popular discourse treats prediction markets as a synonym for collective belief expression. Platforms like Kalshi, Polymarket, and PredictIt operate under regulatory frameworks, settlement rules, and market microstructure requirements that most amateur economists never consider. The distinction matters because the mechanism produces the signal quality, not the act of wagering. MindCast’s Full Arc of Prediction Markets establishes the foundational two-kind taxonomy — public belief exchanges versus proprietary probability engines (SIG, Jane Street, Citadel) — separated by economic basis, participant composition, and epistemic claim. Prediction Markets and the Regulatory Split supplies the binary contract mechanics and price-as-probability architecture underlying that taxonomy. The present analysis extends both; it does not re-lay their scaffolding.
The Four Structural Requirements
Formal prediction markets require four conditions simultaneously. First, contracts must resolve against an objective, pre-specified outcome. A contract paying $1 if Candidate X wins the election resolves against a verifiable external fact. No counterparty controls the resolution condition.
Second, continuous pricing must aggregate distributed information. Participants with genuine private information — polling data, ground-level canvassing results, donor intelligence — express that information through buy and sell orders. Price movement reveals the aggregate probability estimate implied by all private signals in the market simultaneously.
Third, financial stakes must be non-trivial relative to participant resources. The error cost coefficient governs whether participants invest in accuracy. Trivial stakes decouple belief from behavior. A participant who risks nothing has no incentive to update on disconfirming evidence.
Fourth, resolution must occur at a defined time with defined conditions. Open-ended or contestable resolution transforms the contract into a vehicle for narrative dispute rather than probabilistic forecasting. The settlement mechanism closes the feedback loop — or fails to.
Wagering on an outcome is not prediction market participation. Aggregating distributed private info through continuous pricing against objective resolution conditions is.
Why the Seahawks Bet Is Not a Prediction Market
A private wager between two individuals fails all four conditions. No objective price aggregates distributed private information. No continuous updating occurs as new evidence arrives. The financial stake reflects social convention rather than calibrated risk tolerance. Resolution may be disputed or delayed. Two individuals expressing personal beliefs through a single transaction generate noise, not signal.
A sports betting exchange like DraftKings comes closer structurally — continuous pricing, defined resolution, and meaningful stakes exist — but the information set remains constrained to public data and sentiment. Professional sports markets exhibit significant forecasting value precisely because sharp money (bettors with genuine private information about player conditions, coaching strategy, or line movement) participates continuously and forces rapid price updating. The mechanism works not because people bet, but because the right people with the right information face real consequences for being wrong.
Polymarket during an election cycle demonstrates the full mechanism operating correctly. Participants with genuine private information — internal polling, organizational intelligence, regional turnout data — trade against less-informed participants. Prices move as new information arrives. Sharp participants profit by being right. Dull participants lose money and either update their models or exit the market. Resolution occurs against a publicly verifiable outcome. No counterparty controls the settlement condition.
Prediction markets produce intelligence because their structural design forces information revelation through financial consequence and objective resolution. Amateur wagering produces noise because none of those structural conditions hold.
II. Expectation Markets Are Ubiquitous
Expectation formation governs behavior across domains that rarely describe themselves as markets. Investors allocate capital based on anticipated returns. Employers extend offers based on expected performance. Regulators delay or accelerate enforcement based on projected outcomes. Media organizations allocate attention based on expected engagement. Each action expresses a probabilistic view of the future, attaches resource commitment, and resolves over time. Expectation markets exist wherever decisions expose actors to future verification — regardless of whether prices exist.
Formal prediction markets such as Kalshi or Polymarket do not introduce a new structure. They instrument an existing one. Explicit pricing, continuous updating, and defined settlement rules surface what already exists in implicit form across other systems. The theoretical warrant for that claim is the Hayek Bridge developed in MindCast’s Cybernetic Foundations of Predictive Institutional Intelligence: Hayek’s argument that markets function as distributed information-processing feedback systems extends naturally to courts, regulatory agencies, and legislative bodies — each processes signals, adjusts behavior, and generates new inputs into the broader system. Expectation markets are ubiquitous because feedback systems are ubiquitous, not because every domain resembles a financial exchange.
Expectation markets exist wherever belief meets consequence. Formal platforms expose the structure that already governs behavior — they do not create it.
Contact mcai@mindcast-ai.com to partner with us on Predictive Law and Behavioral Economics + Game Theory Foresight Simulations. To deep dive on MindCast work upload the URL of this publication into any LLM and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure. Thereafter, upload news developments to which you want to apply MindCast frameworks.
Recent projects: The Power Stack Series— How Energy Infrastructure Became the New AI Battleground | MindCast AI Emergent Game Theory Frameworks | MindCast AI Field-Geometry Reasoning | MindCast AI Installed Cognitive Grammar | Runtime Geometry, A Framework for Predictive Institutional Economics | Super Bowl LX — AI Simulation vs. Reality | The Runtime Causation Arbitration Directive | Google’s Deep-Thinking Ratio Measures Effort, Not Structure | The Cognitive AI Response to Apple’s “The Illusion of Thinking | MindCast AI Constraint Geometry and Institutional Field Dynamics | Double-Sided Rational Ignorance, How Platform Intermediaries Monetize the Measurement Gap | Executive Summary of MindCast AI Investment Series
III. Feedback Loops Determine Truth Quality
Truth, operationally defined, refers to signals that survive feedback. When actions based on a signal produce consistent outcomes under repeated testing, the system has converged to truth. Feedback loops are the mechanism that separates truth from narrative — not epistemology, not consensus, not authority. A signal that generates consistent consequences when acted upon is true. A signal that persists only because no feedback has yet closed against it is narrative. Feedback loops transform expectation markets from static belief systems into adaptive learning systems precisely because they force that test.
A functioning loop requires three elements: measurable outcomes, consequences for error, and the capacity to update behavior based on results.
Latency governs how quickly outcomes return to decision-makers. Rapid resolution compresses learning cycles and reduces the persistence of error. Slow resolution allows incorrect expectations to survive long enough to attract additional commitment — often from participants who observe apparent consensus rather than underlying evidence. MindCast formalizes feedback latency as the Feedback Latency Index (FLI) in Cybernetic Foundations of Predictive Institutional Intelligence, alongside the Feedback Stabilization Index(FSI) and Feedback Amplification Score (FAS) — metrics that distinguish whether a given institutional system is converging toward equilibrium or accelerating away from it. The clarity dimension formalizes as Causal Signal Integrity(CSI = (ALI + CMF + RIS) / DoC²) — where ALI is Analytical Logic Integrity, CMF is Causal Mechanism Fidelity, and RIS is Recursive Inference Stability — separating genuine structural shifts from advocacy noise and narrative momentum. The three-variable framework in the present analysis — latency, cost, clarity — maps directly onto those published instruments.
Cost governs whether participants internalize error. Financial loss, reputational damage, or institutional penalty forces recalibration. Systems that allow participants to remain insulated from error enable persistent mispricing. Venture capital exemplifies the insulation problem: general partners collect management fees regardless of portfolio performance, and fund cycles extend long enough that individual mispricing rarely traces back to the responsible decision-maker.
Clarity governs whether outcomes produce interpretable signals. Clean settlement conditions eliminate ambiguity and support convergence. Noisy or contested outcomes fragment interpretation and sustain disagreement. Media environments exemplify the clarity failure: engagement metrics measure attention capture, not accuracy, leaving no clean signal of whether reported information matched reality.
Feedback integrity — defined by latency, cost, and clarity — determines whether an expectation market converges toward truth (signals that survive feedback) or stabilizes around narrative (signals that persist only because feedback remains open).
III-A. Cybernetic Control Structure of Expectation Markets
Expectation markets operate as cybernetic systems when feedback loops close with sufficient integrity. Control emerges from continuous interaction between signal, action, and consequence. The tables below formalize the structure and expose where systems succeed or fail. The architecture draws from two installments of the MindCast Predictive Cybernetics Series: Cybernetic Foundations of Predictive Institutional Intelligence establishes the intellectual lineage running from Wiener’s 1948 feedback theory through Ashby’s Law of Requisite Variety, Beer’s Viable System Model, Bateson’s recursive learning levels, and Hayek’s information theory, and formalizes the five-layer causation stack (Event → Incentive → Feedback Loop → Structural Geometry → Identity Grammar) as the Runtime Causation Arbitration Directive; Predictive Institutional Cybernetics operationalizes the Cognitive Digital Twin (CDT) methodology — computational simulations of institutional decision systems that encode incentives, constraint geometry, and behavioral tendencies — and Vision Function routing. The umbrella suite consolidates all three installments as a portable runtime module.
Cybernetic control emerges only when all loop components align. Most systems fail at one or more points. The tables identify where.
Table 1: Cybernetic Loop Components Across Systems
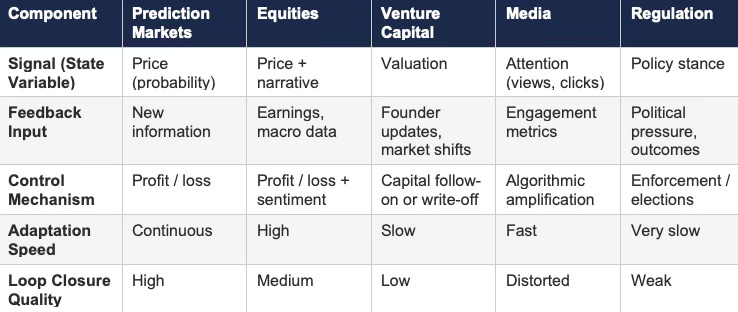
Prediction markets isolate signal and enforce immediate consequence. Other systems introduce delay, distortion, or competing objectives that degrade control quality.
Table 2: Feedback Integrity Metrics
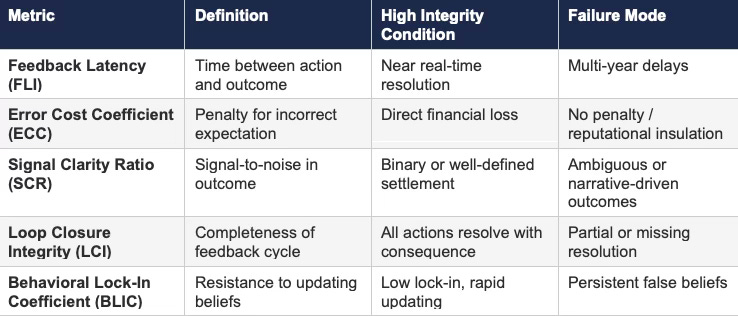
High-performing systems minimize latency, maximize cost for error, and maintain clear resolution signals. Degradation along any dimension reduces convergence to truth.
Table 3: Feedback Gradient and Power Inversion
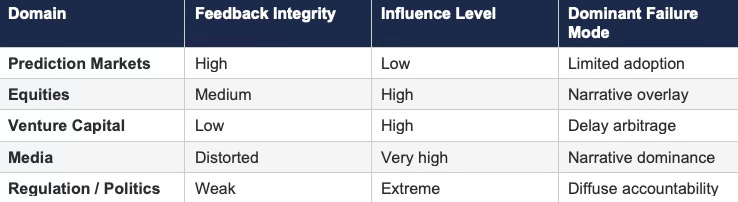
Systems with weaker feedback loops often exert greater influence over expectation formation. Strong-feedback systems produce truth but lack control over upstream inputs.
Table 4: Control Variable Alignment
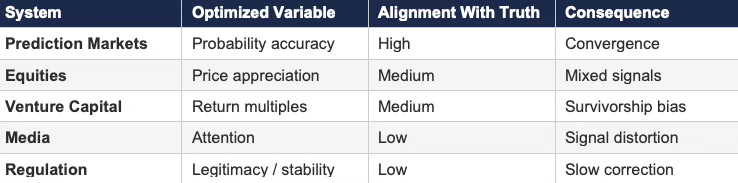
Misalignment between optimized variable and truth degrades cybernetic performance even when feedback exists.
Expectation markets function as cybernetic systems to the extent that feedback loops close with speed, cost, and clarity. Prediction markets represent high-integrity control systems because they force the test that defines truth: repeated action against verifiable outcomes with financial consequence for divergence. Most high-impact domains operate as degraded cybernetic systems — accumulating mispricing, the divergence between current expectation and the feedback-stable state not yet reached, until external compression forces alignment.
III-B. CDT Foresight Simulations: Feedback Integrity Across Expectation Systems
MindCast CDT Foresight Simulations run the feedback integrity framework through four analytical layers — cybernetic control, causal validation, structural constraint geometry, and installed cognitive grammar — to test whether feedback integrity governs convergence to truth across domains. The simulations confirm the paper’s central claim. Systems with fast, costly, and clear feedback loops converge toward reality. Systems with delayed, diffuse, or distorted feedback accumulate mispricing until forced correction. The simulations also identify where failure is not due to irrational actors but to structural constraints and institutional grammar that prevent updating even when accurate signals exist. Corrections do not arrive gradually. Corrections arrive when feedback loops compress.
Table 5: CDT Foresight Simulation — Forward Predictions Summary
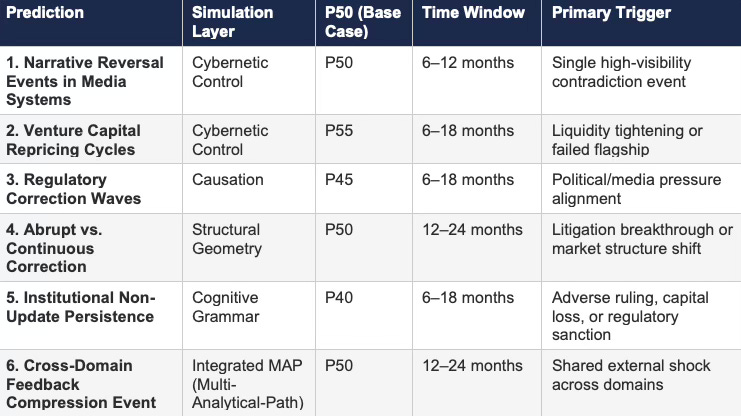
P-values represent base-case probability estimates. P10/P90 bands for each prediction appear in the simulation detail below.
Foresight Simulation I: Cybernetic Control
Cybernetic control analysis evaluates feedback capture, adaptation speed, and loop closure across systems. Prediction markets exhibit continuous signal capture, immediate financial consequence, and rapid behavioral updating — losses enforce correction without institutional intermediation. Equity markets update price signals quickly but allow narrative overlays to distort interpretation, producing partial loop degradation. Venture capital exhibits slow adaptation due to multi-year feedback cycles, allowing mispricing to persist and compound across funding rounds. Media systems capture feedback rapidly but optimize for attention rather than truth, producing a mis-specified control variable where engagement substitutes for accuracy. Regulatory systems display the weakest control structure: long latency, diffuse accountability, and no direct financial cost for miscalibration.
Control quality depends on loop integrity, not participant intelligence. Systems that close loops enforce convergence. Systems that delay or distort loops accumulate feedback debt.
Prediction 1A: Narrative Reversal Events in Media Systems
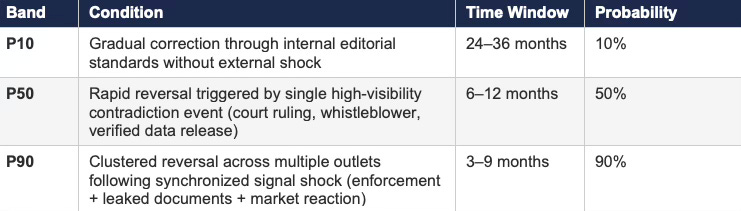
Prediction 1B: Venture Capital Repricing Cycles
Foresight Simulation II: Causation
Causal analysis tests whether feedback integrity functions as the primary driver of system outcomes rather than a contributing factor. The simulation evaluates whether latency, cost, and clarity consistently explain divergence between expectation and outcome across domains. Results show strong causal dominance: systems with low latency and high error cost correct rapidly; systems with high latency and low cost exhibit persistent divergence. Signal clarity determines whether outcomes produce shared understanding or fragmented interpretation. Competing explanations — irrational behavior, information asymmetry — fail to account for persistent mispricing when feedback loops remain open. Structural feedback conditions consistently explain system behavior more effectively than individual decision quality.
Prediction 2: Regulatory Correction Waves
Foresight Simulation III: Structural Constraint Geometry
Structural analysis evaluates whether system architecture constrains the ability of participants to update beliefs. Prediction markets provide clear pathways from error to correction: defined contracts, bounded resolution, and continuous pricing create low-friction update paths. Media systems lack clear settlement conditions, preventing direct mapping from error to consequence. Venture capital structures delay resolution, creating multi-year gaps between action and feedback. Regulatory systems distribute accountability across institutions and time, preventing clean attribution of error. Systems fail when structure prevents correction — not when actors lack intelligence or information.
Prediction 3: Abrupt vs. Continuous Correction
Foresight Simulation IV: Installed Cognitive Grammar
Cognitive grammar analysis evaluates whether institutional behavior resists updating despite available feedback. Campaign organizations, regulatory bodies, and media institutions exhibit grammar patterns that prioritize narrative coherence, legitimacy preservation, or engagement optimization over accuracy. Prediction markets suppress grammar resistance through financial consequence: participants who fail to update exit the system. Institutions resist correction not because they lack information — but because they are structurally organized to reinterpret or reject disconfirming signals. Systems with strong narrative or legitimacy constraints will resist updating until external pressure forces alignment. Internal correction without external shock remains unlikely in such domains.
Prediction 4: Institutional Non-Update Persistence
Foresight Simulation V: Integrated MAP CDT (Multi-Analytical-Path Cognitive Digital Twin)
The integrated simulation routes all signals through causal validation, cybernetic control, structural geometry, and cognitive grammar to determine dominant drivers of system behavior. Feedback integrity emerges as the primary governing variable across all domains. Cybernetic control explains immediate performance differences between systems. Structural geometry explains why certain systems cannot correct quickly even when signals are clear. Cognitive grammar explains why actors fail to update even when correction is structurally possible. All three layers must resolve for convergence to occur. Systems diverge from truth because loops are weak, structure prevents correction, and actors resist updating. Any one of those conditions, left unremedied, sustains the divergence.
Prediction 5: Cross-Domain Feedback Compression Event
CDT foresight simulations confirm that feedback integrity governs expectation market performance across domains. Structural and cognitive constraints determine how systems respond to feedback, but the presence or absence of high-integrity loops ultimately determines whether systems converge to truth or persist in narrative until forced correction. Systems do not fail because participants lack intelligence. Systems fail because feedback loops remain open long enough for error to compound — and corrections arrive only when those loops are forcibly closed.
IV. The Feedback Gradient Across Systems
The most important question for any capital allocator, regulator, or strategic decision-maker is not which system has the best information. The question is which systems are running on weak feedback loops right now — and what will force those loops to close. The feedback gradient maps that terrain. Domains with strong feedback loops produce accurate signals and correct errors quickly. Domains with weak feedback loops accumulate mispricing, sustain narrative divergence from reality, and eventually face abrupt correction when external forces compress the latency they have been exploiting.
Prediction markets operate with rapid settlement, direct financial consequences, and unambiguous outcomes — high integrity throughout. Equities incorporate both price discovery and narrative interpretation, producing mixed signals. Venture capital introduces multi-year delays between investment and outcome, creating the structural conditions for delay arbitrage: valuations persist on narrative long after the underlying feedback would have forced repricing if it arrived faster. Media systems capture feedback rapidly in the form of engagement metrics but impose no cost for inaccuracy, producing a mis-specified control variable that rewards attention capture over truth.
Influence often increases as feedback integrity declines. Media and political systems shape expectations at scale while operating under weak or distorted feedback conditions. Prediction markets produce cleaner signals yet remain peripheral to major decision systems. An internal polling operation at a political consultancy, an editorial board deciding which stories receive front-page treatment, a venture partner shepherding a board through a down round — each exerts enormous influence over downstream expectations while facing minimal systematic accountability for accuracy. High influence with weak feedback is the exact condition that produces the largest correction events when loops eventually close.
A gradient emerges in which signal quality declines as feedback weakens, while influence frequently increases in the opposite direction.
V. Why Prediction Markets Undershoot Their Promise
Prediction markets deliver accuracy within their domain because they engineer strong feedback loops. Continuous pricing updates expectations in real time. Financial stakes impose immediate cost for error. Clear settlement conditions resolve disputes without ambiguity.
Limitations arise from their position within the broader expectation ecosystem. Prediction markets rarely control upstream belief formation. Capital allocation decisions, narrative framing, and regulatory positioning occur outside their boundaries. Market prices reflect aggregated expectations but do not dictate the underlying drivers of those expectations.
Institutional adoption remains constrained by regulatory classification, liquidity constraints, and limited integration into decision workflows. Clean signals remain underutilized when they do not interface with systems that control resource allocation. A political campaign that ignores a prediction market pricing its candidate at 28% while internal polls show 45% is not making an information error — it is exhibiting behavioral lock-in. Updating on external signals requires both the structural capacity and the institutional willingness to receive disconfirming information. Kalshi’s March 2026 voluntary contract screening announcement — accepting behavioral constraints without a court order — is precisely that dynamic operating in reverse: MindCast’s Legislative Regime Conversion and the Collapse of Preemption analyzes it as Prospective Repeated Game Architecture (PRGA)-predicted signal that the platform’s internal probability of the upside case had contracted below the strategic threshold. PRGA models how actors in repeated strategic interactions sustain commitment devices under pressure and when they abandon them. Platforms with genuine private signal about their own legal position do not concede voluntarily until the error cost forces the update.
Prediction markets measure reality with precision but lack the structural reach to shape upstream inputs that determine what outcomes become available to price.
VI. Feedback Failure Modes
Each failure mode below functions as a diagnostic. Hedge funds and event-driven traders use these patterns to identify where mispricing is actively accumulating and estimate what trigger will force closure. Regulators and legislative staff use them to understand why their systems produce crises rather than corrections. Venture investors use them to distinguish structural value from narrative persistence inside their own portfolios. The failure modes are not abstract pathologies — each one names a live condition in a current domain.
Narrative dominance emerges when outcomes fail to discipline beliefs. Participants prioritize coherence of story over alignment with results — persisting on signals that have not survived feedback rather than updating toward signals that have. Media environments exemplify this condition, where engagement substitutes for accuracy. A story that generates outrage produces revenue regardless of whether it accurately represents the underlying event. No financial penalty attaches to subsequent correction. The feedback loop between publication and reality never closes, and narrative accumulates feedback debt that correction will eventually discharge.
Delay arbitrage occurs when actors exploit slow feedback cycles. Strategic behavior targets short-term gain with the expectation of exiting before consequences materialize. Venture environments and regulatory processes provide fertile ground for the dynamic. A startup that raises multiple funding rounds on inflated growth metrics before a down market forces repricing exemplifies delay arbitrage — management extracted capital while the feedback loop remained open. Prediction market platforms navigating the Commodity Futures Trading Commission (CFTC)–state enforcement conflict ran a parallel strategy: sustaining geographic and contract-universe expansion under the commitment device of the federal preemption argument, expecting the feedback cycle to remain open long enough to establish institutional facts on the ground. The Statutory Category Exclusion Mechanism (SCEM) introduced by the Prediction Markets Are Gambling Act collapsed that window by moving to the legislative channel rather than the appellate one — a structural maneuver analyzed in full in Legislative Regime Conversion and the Collapse of Preemption.
Moral hazard arises when error carries little or no penalty. Participants continue to express inaccurate expectations without meaningful consequence, decoupling credibility from performance. Rating agency behavior during the 2008 financial crisis provides the canonical example: AAA ratings attached to structured products that clearly carried higher risk, with no cost imposed for systematic miscalibration until the loop closed catastrophically.
Signal fragmentation develops when no unified mechanism aggregates outcomes. Competing interpretations persist without convergence, preventing the formation of a shared probability distribution. Regulatory proceedings demonstrate the pattern: agencies receive comment letters, conduct economic analysis, hold hearings, and issue rules — yet the actual causal relationship between regulatory intervention and market outcome frequently remains contested years after enactment.
Weak feedback loops generate persistent mispricing that scales across systems until forced resolution occurs. The correction, when it arrives, tends to be abrupt rather than gradual.
VII. The Real Opportunity: Feedback Engineering
The institutions that will dominate the next decade are not the ones with the best analysts or the most data. They are the ones that engineer faster, costlier, and clearer feedback loops into their decision systems before their competitors do. Optimizing decisions inside a weak feedback environment produces local accuracy inside a globally miscalibrated system. Rebuilding the loop changes what accuracy means — and changes who holds the structural advantage when corrections arrive. The prescription that follows is therefore not operational hygiene. It is competitive architecture.
Improvement in expectation markets requires redesigning feedback loops rather than creating new trading venues. Institutions that shorten feedback latency do so by accelerating data release, compressing decision cycles, and integrating real-time measurement into existing workflows. A government agency that publishes enforcement outcome data quarterly rather than annually narrows the gap between action and accountability. A corporate board that reviews CEO forecast accuracy against prior-period commitments at each meeting imposes error cost that the annual performance review cycle would otherwise diffuse.
Increasing error cost requires transparency mechanisms that make individual forecasts attributable and traceable. Anonymous consensus estimates allow miscalibrated forecasters to hide inside aggregate positions. Named forecasting records, performance-linked compensation tied to predictive accuracy, and public scoring against prior commitments all raise the cost of persistent error. Superforecasting tournaments pioneered by the Good Judgment Project demonstrate that reputational accountability — without large financial stakes — produces calibration improvements that persist over time.
Signal clarity improves when outcomes are defined precisely before commitment occurs. Pre-registration of predictions with specified resolution criteria eliminates the post-hoc reinterpretation that characterizes weak feedback environments. Academic clinical trials adopted pre-registration requirements after decades of selective reporting and outcome switching distorted the research record. The same discipline applies to institutional forecasting: define the resolution condition before deploying capital.
Technological systems can aggregate implicit signals across domains, transforming fragmented expectation markets into coherent probability structures. Cross-domain integration reveals discrepancies between belief, commitment, and likely outcome. A CDT Foresight Simulation that maps the gap between regulatory agency stated enforcement posture and actual enforcement action rate generates a prediction about correction timing — and surfaces that prediction before the loop closes.
Systems that engineer feedback loops outperform systems that optimize decisions. Optimizing individual decisions inside a weak feedback environment produces local accuracy inside a globally miscalibrated system. Rebuilding the loop changes what accuracy means.
Engineering feedback integrity produces higher returns than expanding market surface area. Platforms are instruments. The loop is the mechanism.
VIII. Meta-Positioning: Measuring Feedback Across Systems
A higher-order system can observe multiple expectation markets simultaneously and evaluate their feedback integrity. Such a system identifies where expectations diverge from likely outcomes due to latency, cost asymmetry, or signal distortion — and routes those signals through the appropriate simulation modules to determine which layer of the five-layer causation stack (Event, Incentive, Feedback Loop, Structural Geometry, Identity Grammar) is driving the trajectory. MindCast formalizes that diagnostic as the Runtime Causation Arbitration Directive (RCAD), developed in Cybernetic Foundations of Predictive Institutional Intelligence and operationalized in Predictive Institutional Cybernetics. Measurement focuses on detecting feedback delay, identifying actors insulated from error, and mapping how narratives propagate relative to underlying outcomes.
Cross-system analysis reveals where mispricing accumulates and estimates the timing of correction when feedback loops close. A regulatory domain operating with five-year enforcement latency and diffuse accountability currently prices a set of incumbent behaviors as sustainable. When external shocks compress the feedback cycle — a congressional hearing, a court decision, a whistleblower disclosure — the correction reprices those behaviors rapidly. The prediction markets regulatory arc provides the sharpest published demonstration: Prediction Markets and the Regulatory Split deployed a CDT Foresight Simulation assigning P45/P35/P20 probabilities across three regulatory scenarios four days before three of six identified triggers activated simultaneously; Legislative Regime Conversion and the Collapse of Preemption then documented the state transition, confirming that loop closure arrived through the legislative channel rather than the appellate path the original model flagged as primary. Mapping that deviation — and the structural reason the SCEM moved faster than appellate review — is exactly the meta-level analysis the present framework advocates.
Strategic advantage accrues to systems that predict not only outcomes but the path by which feedback will force convergence. Actors insulated from error do not update voluntarily. Loop closure arrives externally — through litigation, market correction, electoral consequence, or institutional failure. Identifying which actors carry the largest unresolved feedback debt, and which external catalysts are positioned to compress their latency, generates the most actionable predictive insight available from meta-level analysis.
Predictive Cognitive AI extends beyond prediction markets by modeling expectation systems as interacting feedback loops. Cognitive Digital Twin foresight simulations identify where feedback integrity is degraded, estimate the persistence of mispricing, and forecast the events that will force loop closure. The objective is not to predict isolated outcomes — it is to anticipate when systems will be compelled to update, and how those updates propagate across domains. Prediction markets are single-loop systems: one contract, one resolution condition, one feedback cycle. MindCast operates as a multi-loop simulator, modeling the media loop, the market loop, the regulatory loop, and the institutional loop simultaneously — and predicting which loop dominates, which collapses, and how they synchronize when compression arrives. Most forecasting systems ask what will happen. Prediction markets ask what is the probability. Predictive Cognitive AI asks when competing expectation systems will be forced to update — and what reality will look like after they do.
Meta-level analysis of feedback integrity provides leverage beyond participation in any single expectation market. Position before the loop closes.
IX. Forward Prediction and Falsification
Expansion of AI-generated content, narrative amplification, and regulatory delay will increase the prevalence of weak-feedback expectation markets. AI content at scale decouples information production from verification cost. A system that generates ten thousand plausible-sounding claims per second imposes negligible marginal cost per claim — and the feedback loop between claim and consequence extends to the point of invisibility. Mispricing will compound across systems that lack rapid, costly, and clear feedback loops.
Eventual resolution will occur through discrete shocks that compress feedback suddenly. Market corrections, regulatory enforcement waves, or institutional failures will force rapid repricing of expectations that previously persisted under weak feedback conditions. Compressed feedback events tend to overshoot equilibrium because the accumulated mispricing resolves simultaneously rather than continuously.
Falsification requires observation of large-scale systems with structurally weak feedback loops self-correcting without external shocks or extended delay. Specifically: if media systems operating under engagement-optimized incentives show sustained improvement in accuracy and calibration without structural intervention — without ownership changes, regulatory pressure, or algorithmic redesign — the model requires revision. If venture capital portfolios in sectors with five-year fund cycles show feedback-driven correction patterns approximating equity market speed, the model’s latency predictions fail. Sustained alignment between expectation and outcome in low-accountability domains without improved feedback integrity would invalidate the architecture.
Structural persistence of weak feedback loops predicts abrupt corrections rather than smooth convergence. Actors who treat the absence of correction as evidence of accuracy are exhibiting exactly the behavioral lock-in that makes the eventual correction severe.
Closing Synthesis
Expectation markets govern decision-making across domains regardless of whether participants recognize them as markets. A man who bets his friend twenty dollars on an election outcome has formed an expectation and attached a consequence to it. He has not built a prediction market. The distinction separates noise from signal, wagering from forecasting, participation from intelligence.
Feedback loops determine whether expectation systems learn or drift. Strong feedback produces convergence toward truth — signals that survive repeated testing and impose consistent consequences. Weak feedback allows narrative to dominate — signals that persist because loops remain open, not because the underlying claim has been validated. Prediction markets illustrate the principle but do not define the frontier.
Feedback integrity defines the frontier. Systems that engineer faster, costlier, and clearer feedback loops will dominate those that rely on delayed or distorted signals. Actors who understand the structural conditions that produce accurate forecasting — and who can identify where feedback debt has accumulated in high-influence domains — hold a systematic advantage over actors who mistake wagering for intelligence and narrative persistence for truth.
Every reader of this paper operates inside at least one expectation market with degraded feedback integrity. The hedge fund manager asking which sectors are running on narrative rather than reality is asking a feedback question. The regulator asking why enforcement always arrives after the damage is a feedback question. The venture investor asking which portfolio company valuations will survive a liquidity event is a feedback question. The technology executive asking where AI deployment has outrun operational reality is a feedback question. The prediction market operator asking why clean signals fail to convert into institutional adoption is a feedback question. The framework here does not answer each of those questions individually. It provides the diagnostic architecture that makes each of them answerable — before the loop closes and the answer becomes obvious to everyone.
Prediction markets reveal how feedback loops produce truth. Predictive Cognitive AI models how those loops interact — and predicts when reality will force every system to update.
Confidence signals belief. Feedback determines truth. MindCast predicts when systems run out of the distance between the two.