

⚽ MCAI Cultural Innovation Vision: Recovery and Recursion — Qatar, Bosnia, Egypt, Iran Under Shared Rules
Cultures Under Shared Rule: Seattle Lab II

Cultures Under Shared Rules — The Seattle Lab at FIFA World Cup 2026 series
Belgium vs Egypt | USA vs Australia | Qatar, Bosnia, Egypt, Iran Validation Reports World Cup Validation Report I — USA, Belgium-Egypt, Mexico
MindCast Special Series — a deliberate stress test of the MindCast system beyond the controlled venue of the MindCast Seattle Lab
World Cup Championship Index 2026 | When a FIFA World Cup Model Picks France and the Economist Picks Argentina | Mexico vs South Korea | Mexico and USA
Forthcoming
Seattle knockouts — Round of 32 (Jul 1) + Round of 16 (Jul 6)
Validation Report II — grades Seattle Lab II, converts the Recursion line on the dashboard
Published before kickoff. Time gates and the falsification contract are committed below. Update status — June 21, complete: both group-stage results are folded in. Iran drew Belgium 0–0 and Egypt beat New Zealand 3–1, so the common-opponent grid is closed and the recursion baseline is measured rather than inferred.
I. Why Seattle Lab II Matters
The first Seattle Lab opened on a single question: how do cultures behave when they meet one another under shared rules? Belgium–Egypt, USA–Australia, and Mexico–South Korea answered it well enough to produce the project’s first public scorecard. Validation Report I recorded the result — Environmental Alignment survived contact with reality, the Portable Home Field survived first contact, and Recursion Strength remained the one dimension the cohort could not yet test.
Seattle Lab II exists to address that unresolved variable, and it does so by pairing two matches that ask opposite questions of the same framework. Qatar versus Bosnia examines recovery, because both sides arrive in Seattle carrying heavy defeats and the variable under observation is whether a damaged system reorganizes. Egypt versus Iran examines recursion, because Egypt returns to the same stadium that hosted its opener and the variable under observation is whether an established identity adapts without losing coherence.
Recovery and recursion are different phenomena, and separating them is the point. Seattle Lab I tested culture; Seattle Lab II tests evolution. One match measures whether systems recover from a shock, the other whether systems learn from experience, and the answer to both matters more to the framework than either scoreline.
II. Why MindCast Simulates Football
Traditional sports forecasting predicts outcomes from talent, rankings, and historical performance, and it answers a narrow question: who is likely to win? MindCast AI applies predictive game theory and behavioral economics to a different question — how teams adapt, coordinate, learn, recover, and respond to pressure. The objective is not merely to name winners but to identify the mechanisms that produce them. Scorelines are outputs; human behavior under pressure is the signal.
Football rewards that lens because a tournament is a repeated strategic game. Teams update beliefs between matches, respond to incentives, react to losses, manage risk, and adapt to changing information about themselves and their opponents — and those decisions, far more than raw talent, settle tight matches. Behavioral economics explains how pressure, expectation, identity, and loss aversion bend those decisions away from the textbook-rational path: a side protecting a lead turns conservative and invites pressure onto itself, a side chasing a deficit turns risk-seeking and leaves gaps at the back, a favorite grips under the weight of a watching nation, a side that loses its composure concedes a man or a penalty it did not have to. Predictive game theory then models how those bent decisions interact over time, across the seven rounds a champion must survive.
The payoff is concrete rather than decorative, and it is what separates this from traditional analytics. A talent model treats a team as a fixed quantity; a behavioral model treats it as a system whose decisions degrade in measurable ways under specific conditions. When a behavioral pattern is observable — a side that fades after the 70th minute, a side that unravels once a match turns against it — it changes the probability of a specific outcome, and the forecast moves because the mechanism moved. Every probability in this report is built to emerge from a mechanism rather than to sit beside one: the reader should be able to trace each number back to the behavioral fact that produced it.
The Seattle Lab is where MindCast AI stress-tests that engine in public, and the lineage runs through American football. MindCast first proved the architecture on the gridiron with Super Bowl LX — AI Simulation vs. Reality, publishing structural resolution conditions and a falsification contract before kickoff and grading them against a Seattle win that resolved exactly as the mechanism predicted, a record documented in Super Bowl LX and Seahawks 2025–2026 Season Validation. Litigation and geopolitical forecasts resolve slowly and privately, but a football match resolves in ninety minutes on a fixed schedule with a scoreboard anyone can read, which makes the sport the cleanest available proof that the method works — and the fastest available evidence when it does not. Every Seattle Lab simulation inherits that discipline, committing its mechanism, its regime, and the conditions that would prove it wrong before kickoff, then grading itself against the result.
III. The Four Cognitive Digital Twins
Each team enters Seattle as a Cognitive Digital Twin built from two group-stage matches, and the assessments below read each system through what its results and match data reveal rather than through reputation. Every behavioral inference is grounded in an observable — a concession pattern, a possession swing, a shot count — rather than asserted as a mood, because the discipline is to measure the system, not to narrate it. The order moves from the recovery pair to the recursion pair.
🇶🇦 Qatar — the composure-fragile system. Qatar built its football program through two decades of centralized investment, and the group stage exposed a specific weakness — composure rather than pure quality. A 1–1 draw with Switzerland showed a side that competes with strong opposition, and the 0–6 scoreline against Canada looks like total collapse until the cause is read: Qatar had two players sent off, the first at the 33rd minute and the second at the 53rd for a challenge that broke an opponent’s leg, and finished the match with nine men. Canada led 3–0 before the second dismissal, and the back half of the rout came against a side two men short, so the result is a discipline-and-composure failure under adversity far more than a six-goal defensive gap. A Lab self-correction follows directly: Qatar is less damaged than the scoreline implies, and the thing it must repair is composure under pressure, not its entire structure. Its Seattle test is whether a side prone to unraveling can hold its discipline through a tight match, and its victory path depends on staying eleven-against-eleven and avoiding negative game states. Coach Julen Lopetegui leads a group whose attacking threat runs through Akram Afif.
🇧🇦 Bosnia & Herzegovina — the competitive-early, fade-late system. Bosnia carries a different profile, built on technical quality, diaspora networks, and the veteran presence of Edin Džeko rather than centralized funding. The damage has an unusually precise signature: every one of the five goals Bosnia has conceded across both matches arrived after the 70th minute, including the Canada equalizer in a 1–1 opener and the Switzerland deluge after the 73rd. Against Switzerland, Bosnia stayed cagey, organized, and goalless for 73 minutes before a substitute cracked it and a red card at the 80th reduced the side to ten, after which three goals followed. The pattern reads as a system that competes evenly for an hour and then fades through concentration or fitness in the closing stretch, which separates its damage from Qatar’s discipline problem. A second Lab self-correction applies here too: the Switzerland scoreline was inflated by the late dismissal, so Bosnia is less broken than 4–1 suggests, and the thing it must repair is the final twenty minutes. Its Seattle test is whether a side that holds for an hour can hold for ninety, and the data still gives it the stronger early-match profile of the recovery pair. Coach Sergej Barbarez.
🇪🇬 Egypt — the coherent recursion candidate. Egypt returns to Seattle holding the strongest recursion baseline in the project, established in an opener whose scoreline understates it. A 1–1 draw with Belgium records the result, but Egypt led one of the tournament favorites from the 19th minute to the 66th — longer than the Pharaohs had ever led across their entire prior World Cup history — before conceding a late own goal. The shape of that performance answers a question the opener’s falsification gate raised — whether Egypt is genuine collective synchronization or Salah dependency wearing its colors. The evidence points to orchestration rather than dependency: Salah played a central role and led the team in chances created, passing accuracy, and fouls won, yet the goal was finished by midfielder Emam Ashour, and Omar Marmoush and Mostafa Zico both threatened, so creation hubs through Salah while execution distributes across the side. Egypt also held disciplined defensive shape for 47 minutes and conceded only an own goal forced by a substitute, which reads as a mature system running an active learning process rather than mere confidence. Cycle-two adaptation (Belgium to New Zealand) supplies the first measured recursion delta; the June 26 keystone confirms whether it holds against an adaptive opponent rather than a deep block.
Egypt’s operating grammar is civilizational continuity through Salah-orchestrated synchronization, and it seeks optimization rather than disruption, so its Seattle test is whether that identity can evolve without losing its coherence. Egypt’s 3–1 win over New Zealand answered that test affirmatively and converted the recursion baseline from an inferred capability into a measured one — the first direct evidence in the Seattle Lab that a system can carry its identity forward while improving its performance. Trailing 1–0 at halftime to a New Zealand side sitting deep, Egypt adjusted, pushed numbers forward, and scored three times through Zico, Salah, and Trezeguet, with Salah both scoring and assisting and Zico both scoring and assisting — orchestration distributing across the side exactly as the dependency test predicted, not collapsing onto one man. The result carries a direct keystone implication: Egypt broke down a packed low block, which is the very structure Iran is most likely to deploy on June 26.
🇮🇷 Iran — the adaptive endurance system. Iran produced the largest assessment revision of any team in Seattle Lab II, because the Belgium–Egypt opener loosely bucketed it as a plural-coordination side and two matches have since shown adaptive endurance instead. Against New Zealand, Iran traded blows in a 2–2, coming from behind twice — trailing in the 7th minute and again in the 55th, equalizing both times — on 47% possession as a style marker rather than a control proxy, with right-back Ramin Rezaeian scoring once and assisting Mohammad Mohebbi's header. Against Belgium, Iran did the opposite, dropping into a deep block, ceding the ball at roughly 30% against Belgium's 70% and 1.82 expected goals, and earning a clean sheet behind seven saves from goalkeeper Alireza Beiranvand while threatening almost entirely from set pieces and long throws.
The deeper signal sits beneath the mode switch: the same spine plays both matches — Taremi, Rezaeian, Mohebbi, Beiranvand, the veteran Hajisafi, the holder Ezatolahi — but different members drive each, the attackers and overlapping full-back against New Zealand, the keeper and back line against Belgium. Iran therefore reads as a stable identity with adaptive emphasis rather than a shape-shifter, which is a more dangerous profile than disruption. One honest caveat travels with the Belgium result, since Belgium lost Nathan Ngoy to a red card in the 67th minute and Iran defended the final stretch a man up, so the shutout is strong structure plus a late man-advantage rather than a flawless eleven-against-eleven lockdown. Captain Mehdi Taremi leads the line in both modes. Iran’s Seattle test is whether that endurance can out-last a more coherent opponent’s adaptation, and the system grows more dangerous as match volatility falls.
The four sides split along the report’s two axes, and the Integrated Assessment grid below summarizes the engine’s read on each. The grid scores the qualities that matter to the two questions — coherence and adaptation for the recursion pair, recovery and risk for the recovery pair.
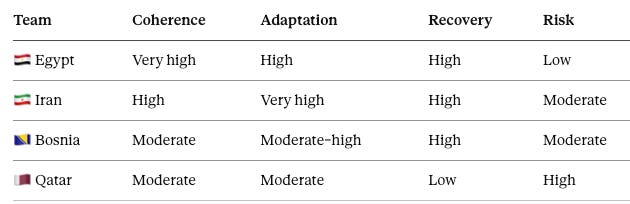
Read down the columns, the separation is clean: Egypt leads on coherence, Iran on adaptation, Bosnia carries the stronger recovery profile of the damaged pair, and Qatar carries the highest risk of repeating its collapse.
Contact mcai@mindcast-ai.com to partner with us on Predictive Game Theory AI in Law and Behavioral Economics. To deep dive on MindCast works upload the URL of this publication into any LLM (preferably Google AI mode/Gemini, Claude, ChatGPT) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
MindCast AI is a cybernetic, predictive game-theory AI firm specializing in law and behavioral economics, applied to complex litigation, innovation systems, and geopolitical risk intelligence. Rather than extrapolating historical patterns, the firm models the mechanisms that generate institutional behavior, running Cognitive Digital Twin simulations grounded in Nash equilibrium, Stigler information economics, and the Chicago School of law and behavioral economics.
We simulate NFL and World Cup games to stress test our predictive AI system. MindCast AI NFL Vision: Super Bowl LX — AI Simulation vs. Reality
IV. Two Common-Opponent Webs
Both Seattle fixtures come with an unusually clean comparison built into the group draw, and naming each one sharpens the read. The webs do most of the analytical work the scorelines alone cannot.
The Egypt–Iran pair shares the same two opponents in opposite order. Egypt has faced Belgium and faces New Zealand on June 21; Iran has faced New Zealand and faces Belgium on the same day. By the time the two meet on June 26, each will have played the identical pair — Belgium and New Zealand — which makes their relative form directly comparable on common opposition, the cleanest such comparison available anywhere in the tournament. The Belgium column is now filled and tilts toward Iran on the shared opponent: Egypt drew Belgium 1–1 and led for 47 minutes before an own goal, while Iran drew the same Belgium 0–0 and conceded nothing, a cleaner sheet against identical opposition even with the red-card caveat attached. The readings also force a Lab self-correction on Belgium, because the opener assumed Belgium’s distributed creation would produce a steady offensive advantage, and Belgium has since managed a single goal across two matches — and that one an Egyptian own goal rather than open-play creation. Egypt’s 3–1 win over New Zealand fills the second column and closes the grid.
The comparison now splits cleanly by opponent: against New Zealand, Egypt won 3–1 where Iran drew 2–2, the stronger result against the shared lower-ranked side; against Belgium, Iran kept a clean sheet where Egypt conceded an own goal, the cleaner result against the shared favorite. Egypt looks the more potent of the two against a side it should beat, while Iran looks the more resilient against a side it should not — a split that maps precisely onto the keystone’s adaptation-versus-endurance axis.
The Qatar–Bosnia pair shares its opponents too, and the results form a mirror image that breaks ordinary ranking logic. Bosnia drew Canada 1–1 but lost 4–1 to Switzerland; Qatar drew Switzerland 1–1 but lost 0–6 to Canada. Each side held the exact opponent that dismantled the other, so transitivity collapses — no chain of results ranks one above the other, because Bosnia looks stronger through Canada and Qatar looks stronger through Switzerland. The mirror is the reason the match is genuinely hard to call, and it anchors the recovery thesis: the outcome turns on which damaged system reorganizes first, not on which is objectively better.
Both webs convert a vague matchup into a measurable one, and both feed directly into the regimes and forecasts that follow.
V. Cultural Signal Integrity Model
The scorecard below scores each side on the four MindCast metrics — Signal Fidelity, Action–Language Integrity, Recursion Strength, and Transmission Saturation — and resolves them into a geometric-mean Cultural Innovation Quotient, where a score below 50 reads weak, 50 to 59 moderate, 60 to 69 strong, and 70 or above flagship. All four teams sit in one table, teams as columns, so the comparison reads in a single view.
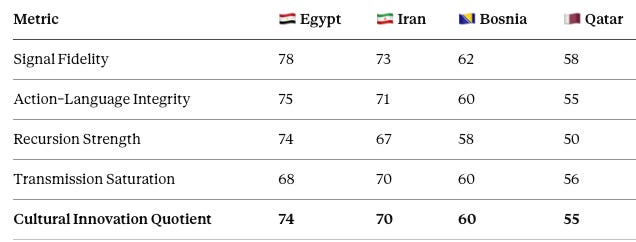
The scores are finalized against both June 21 group-stage results and a pass through the MindCast Vision stack." Delete "provisional scaffold" and "due for finalization after tonight's Egypt match. Iran’s numbers rise on the strength of the Belgium clean sheet — Signal Fidelity moves from 68 to 73 and the Cultural Innovation Quotient reaches the flagship line at 70, because a side that scores twice against one opponent and shuts out a favorite against the next is demonstrating fidelity, not just volume. Egypt still leads the cohort on coherence, and its recursion is now demonstrated rather than a mere candidacy after the New Zealand win, which lifts its Recursion Strength to 74. Bosnia holds a moderate-to-strong profile on technical quality, and Qatar’s volatility pulls it to the bottom of the four.
The Egypt–Iran keystone also earns a match-specific variable the opener did not carry: Defensive Integrity. Iran has now held a tournament favorite scoreless, and a clean sheet against Belgium is a structural signal rather than noise, so the keystone will track which side better protects its own goal alongside which side better imposes its identity. The interaction matters more than the standalone numbers, because the contest is no longer adaptation against disruption — it is adaptation against adaptation, with defensive integrity as the tiebreaker.
VI. Game Regimes
The first Seattle Lab cohort taught the framework to lead with the regime fork rather than a single label, because the timing of the first goal proved to be the hinge between a controlled grind and a blown-open match. Both fixtures below are therefore committed as forks with an explicit trigger, not as fixed regimes.
Qatar versus Bosnia opens as a Labyrinth — two damaged sides probing, neither able to impose, adaptation mattering more than talent — and forks toward an open, high-event match only if a goal lands early. An early goal forces the trailing side to chase, and because both teams arrive with little left to lose, a chase could pull the match open quickly; absent that early goal, the Labyrinth holds and the side that reorganizes first grinds out the edge. The trigger is a goal inside the opening half hour.
Egypt versus Iran opens as a Labyrinth and forks toward either a controlled grind or an open Arena. Two adaptive systems meet here rather than an adaptive one against a disruptive one, because Iran has shown it can lock a match down as readily as open it up. The fork turns on the first goal and on which mode Iran chooses: Egyptian control through the opening half hour, or an early Egyptian goal, keeps the match a low-event Labyrinth that grinds slowly, whereas an Iranian lead or a chaotic opening flips it into an Arena where Iran’s counter-attacking and comeback capacity carry real threat. A scoreless, tightly contested Labyrinth is now the more likely default than the opener assumed, given that Iran’s instinct against the stronger side at Belgium was to defend first. Adaptation versus adaptation is the contest, and the first goal is the switch.
Both forks share the same logic the cohort validated: the regime is a branch, not a label, and the early goal decides which branch the match takes.
VII. Forecast
The primary output of each simulation is structural, and the scoreline follows as secondary output rather than the point of the exercise — the same ordering Validation Report I adopted after the first cohort. Each forecast below leads with the mechanism, reports probabilities as bands rather than false-precision point estimates, and states a confidence band that reflects how much the framework actually knows.
Qatar versus Bosnia turns on which side’s failure mode triggers first, and both failure modes are behavioral rather than technical. Qatar’s two red cards against Canada were not tactical errors but composure failures under adversity — a side that loses emotional regulation once a match turns against it — and that pattern raises the probability of a self-inflicted swing, a dismissal or a penalty conceded, in any match that grows tense. Bosnia’s signature is different: every one of its five conceded goals came after the 70th minute, a late-game concentration-and-fitness fade that behavioral economics would read as decision quality degrading under accumulated fatigue and pressure.
The forecast follows directly from stacking those two mechanisms against the clock. For roughly seventy minutes Bosnia is the more organized side, so the early and middle phases favor it; the danger window for both arrives late, where Bosnia tends to leak and Qatar tends to crack. Because a Qatar composure lapse hands Bosnia a man or a set piece more readily than Bosnia’s fade gifts Qatar a clear-cut chance — Qatar created almost nothing in open play even before its collapse — Bosnia’s win probability sits meaningfully above Qatar’s despite similar underlying quality. The numbers express that asymmetry directly.

🇧🇦 Predicted final score: Bosnia 1–0 · regime Labyrinth · expected ~1–2 goals total · the decisive phase is the final twenty minutes
Bosnia’s 42% to Qatar’s 24% is the composure asymmetry made numerical: Qatar’s higher base rate of late self-inflicted damage is the single largest input separating the two, and the 34% draw reflects how often two cautious, free-playing sides cancel out before either failure mode fires. The most likely scoreline is Bosnia 1–0, with 1–1, Bosnia 2–1, and Qatar 1–0 as the live alternatives, in an expected one-to-two-goal match. Confidence sits at 58–63%, held down by weak separation in underlying quality, limited recovery evidence, and the fact that a single discipline event could swing the result either way.
Egypt versus Iran turns on adaptation against adaptation, and the forecast emerges from a single behavioral fact: both sides defend better than they attack under pressure. Iran’s endurance mode shut out Belgium, and Egypt’s disciplined shape conceded only an own goal to that same side, so two of the tournament’s most loss-averse defenses meet here, and loss-averse systems facing each other tend to suppress the event rate — which is why the draw still carries real weight. Egypt’s edge widened after New Zealand, though, because the most likely Iranian plan against Egypt is the deep block it ran at Belgium, and Egypt has now demonstrated against a packed New Zealand defense that it can break exactly that structure down — Salah-orchestrated, from a goal behind, three scored. Iran’s clean-sheet capacity still caps Egypt’s conversion and keeps the match genuinely close, but the recursion evidence moved Egypt from a narrow favorite to a clearer one. The original “Egypt clear favorite” read tightened after Iran’s Belgium clean sheet, then firmed again once Egypt proved it can unlock a low block.

🇪🇬 Predicted final score: Egypt 1–0 · regime Labyrinth forking to Arena · expected ~2–3 goals total · 1–1 the most likely draw if Iran’s block holds
The keystone carries real stakes, because Egypt’s win moved it to the top of Group G and a draw against Iran secures a top-two finish, while Iran also still chases the summit — so June 26 is a match for first place rather than a dead rubber. Defensive Integrity sits at the center: Iran shut out Belgium and Egypt conceded only an own goal to the same side, so two of the tournament’s more resilient defenses meet here. The most likely exact scoreline stays tight — a 1–1 draw or an Egypt 1–0, with Egypt 2–1 and Iran 1–0 as the live alternatives in an expected two-to-three-goal match — but the most likely outcome is now a narrow Egypt win rather than the stalemate the pre-New-Zealand read implied. With the common-opponent grid complete and the recursion baseline measured, confidence settles at 66–72%: the match stays close, but the framework now holds a Belgium baseline, an Iran baseline, a completed common-opponent comparison, and a demonstrated recursion case, which is the information quality that earns the higher band.
Reduced to one sentence: Bosnia appears more recoverable than Qatar, and Egypt more coherent than Iran, but Iran’s adaptive endurance makes the keystone far closer than the tournament baseline suggested.
VIII. Time Gates and the Four Futures
The cohort also taught the framework to key its futures to four windows rather than to the first half alone, because Mexico’s decisive goal arrived in the 50th minute and fell between gates framed only around halftime. Each match below carries four observation windows: the opening 25 minutes, the halftime state, the first 15 minutes after the restart, and the final 20.
For Qatar versus Bosnia, the opening 25 minutes test which damaged side shows clearer structural recovery, the halftime state tests whether organization is improving or still deteriorating, the third-quarter window tests whether either side has reestablished coherence after the break, and the final 20 test whether fatigue reopens the defensive gaps both sides have shown. Shots on target and big chances created — not possession share — are the observables, since the cohort proved possession a poor proxy for control.
For Egypt versus Iran, the opening 25 minutes test whether Egypt carries its Belgium lessons forward, the halftime state tests whether Iran has succeeded in raising volatility, the third-quarter window tests whether adaptation or disruption governs the restart, and the final 20 test Iran’s comeback capacity against Egypt’s ability to close. The same observables apply: decisive-moment quality and chance creation rather than territory.
Both gate sets share one purpose — to catch the decisive moment whenever it arrives, rather than to assume it arrives before halftime.
IX. Falsification Contract
The simulations weaken, and the framework learns, if any of the following hold. Recovery proves unrelated to prior damage, which would sever the recovery thesis of the Qatar–Bosnia read. Egypt displays no measurable adaptation relative to its Belgium baseline, which would undercut the recursion claim at the center of the keystone. Iran’s resilience and disruption fail to materialize, which would falsify the corrected profile. Environmental conditions explain more variance than recursion, which would return the result to the Lab I findings rather than advancing them.
Each condition is committed before kickoff, and each is observable from the gates above. Validation remains the objective, and calibration remains the discipline.
X. Forward Recursion — What Sunday Updates
The recursion spine of this report is now measured rather than committed-but-pending, because June 21 delivered both results it depended on. Egypt’s 3–1 win over New Zealand supplied the second data point that converts Egypt’s recursion baseline from a single reading into a rising trend, since Egypt followed a strong Belgium performance with a comeback victory, increased goal output, and a halftime adjustment that broke down a deep block — identity carried forward while performance improved. Iran’s 0–0 draw with Belgium supplied the direct comparison the keystone is built on, measuring the two sides on identical opposition within days. The completed common-opponent grid lets the June 26 forecast rest on measured form rather than inferred form, which is the standard Validation Report I set for this stage.
The scorecard in Section V now reflects those results, with Egypt’s recursion lifting to a measured 74, and the Group G picture has sharpened — Egypt leads going into the final round, and the keystone itself decides first place. Recursion moved from theory to measurement across the weekend, which is the whole reason the keystone was scheduled into the Lab.
XI. Why Seattle Lab II Matters
Seattle Lab I established that cultures behave distinctly under shared rules, and Seattle Lab II asks whether they change once reality has imposed a cost. Qatar and Bosnia test whether damaged systems recover; Egypt and Iran test whether established systems learn. The recovery question and the recursion question are separate, and the framework’s future depends on measuring both rather than collapsing them into a single notion of form.
Validation Report I established the baseline, and Seattle Lab II determines whether adaptation can become a measurable forecasting variable rather than an asserted one. The answer the keystone produces on June 26 may prove more durable than any scoreline it also happens to call.