

⚽ MCAI Cultural Innovation Vision: World Cup Validation Report II — Bosnia, Egypt-Iran, Mexico, Türkiye
Recovery, Recursion, Competitive Necessity, and the Second Calibration Cycle

Cultures Under Shared Rules — The Seattle Lab at FIFA World Cup 2026 series
Belgium vs Egypt | USA vs Australia | Qatar, Bosnia, Egypt, Iran
Validation Reports World Cup Validation Report I — USA, Belgium-Egypt, Mexico | World Cup Validation Report II — Bosnia, Egypt-Iran, Mexico, Türkiye
MindCast Special Series — a deliberate stress test of the MindCast system beyond the controlled venue of the MindCast Seattle Lab
World Cup Championship Index 2026 | When a FIFA World Cup Model Picks France and the Economist Picks Argentina | Mexico vs South Korea | Mexico and USA
Forthcoming
Seattle Lab III — Belgium vs. Best Third-Place (A/E/H/I/J) — Round of 32, Seattle, July 1. Your immediate next write. Unblocks tonight once Groups J and K finish and the third-place table sets the opponent. Belgium’s twin carries over from the Group G work.
Round of 16 — the eight-match slate — July 4–7 (Matches 89–96). Full coverage begins here. Each commits only after its two Round of 32 feeders resolve, so they publish in a rolling wave July 2–4 rather than in one drop.
The Seattle R16 (Match 94, July 6) is one of those eight — it doesn’t add a publication, it just sits in both buckets at once.
Validation Report III closes the cycle, grading Seattle Lab III plus the eight R16 forecasts against results, and giving your seven new calibration changes their first live knockout test.
Executive Summary
Validation Report II closes the second calibration cycle of MindCast AI football forecasting. The first cycle tested whether the framework could read cultural identity, Environmental Alignment, and Portable Home Field. The second cycle tested whether the system could read evolution — damaged systems recovering, coherent systems learning, hosts operating after qualification, and eliminated teams playing without competitive necessity.
Four simulations resolved between June 24 and June 26:
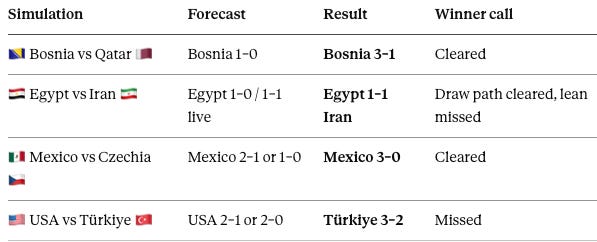
The strict winner record is two clean hits and two non-wins. The structural ledger sits underneath and matters more. Bosnia validated recovery through functional fragmentation. Iran validated adaptive endurance — and exceeded the label, out-creating Egypt rather than merely surviving it. Mexico validated Portable Home Field release and the steep Competitive Necessity Gradient. Türkiye validated the conversion-gap correction and the intrinsic-motivation floor. The United States became the cycle’s primary negative calibration event: environmental advantage and distributed expansion failed once Türkiye’s finishing corrected. Egypt split — its identity persisted across the group, but its forecast lean, that it would break Iran’s block, did not survive contact with the match.
Expected goals tell the cleanest version of the story. The model read function correctly where it priced a mechanism (Mexico 1.79 to 0.47, Türkiye 2.71 to 2.06) and lost where it leaned directionally into a coin-flip (Iran out-created Egypt 1.94 to 0.81). Diagnosis beat prediction — which is the framework’s own stated thesis, now confirmed by the data rather than asserted. Confidence the xG pattern supports that reading: 85%.
Report II therefore strengthens the framework while correcting two overreaches. The system read four of its central mechanisms correctly, moderated one (Egypt coherence), and missed one result outright (USA) in the exact flat-gradient condition it had flagged as least safe.
I. What Was Forecast
Two companion simulations supplied the second validation set.
Seattle Lab II paired Qatar vs Bosnia and Egypt vs Iran under Recovery and Recursion. Qatar–Bosnia tested whether a damaged system could reorganize after shock. Egypt–Iran tested whether a coherent system could keep learning against an adaptive-endurance opponent.
The Mexico–USA series paired Mexico vs Czechia and United States vs Türkiye under Host Nations Under Pressure. Mexico–Czechia tested a steep Competitive Necessity Gradient — a secure host against a desperate visitor. USA–Türkiye tested a flat gradient — a secure host against an eliminated opponent with little competitive need but a live intrinsic-motivation floor.
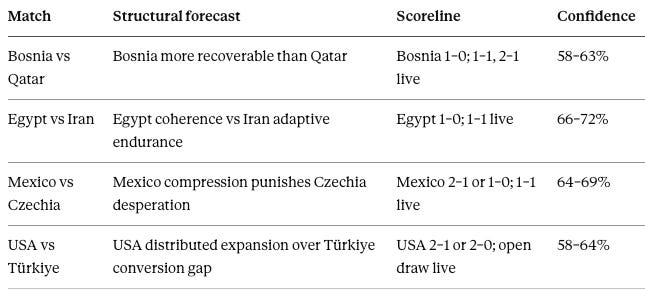
Every forecast made the scoreline secondary. The commitment was mechanism-first: behavioral patterns generate the probabilities, and the match reveals whether the mechanism held.
II. What Happened
🇧🇦 Bosnia 3–1 Qatar — winner cleared, recovery frame held, micro-mechanisms missed. Bosnia won, and the recovery-versus-collapse frame held at the level that decides advancement: the reorganizing damaged side went through, the collapsed one went home winless and bottom. Two specific sub-reads, though, did not appear. Bosnia’s predicted late-game fade never materialized — rather than concede after the 70th, Bosnia extended through Mahmić at 80’ and closed strong (Alajbegović 29’, Abunada own goal 34’, Al-Haydos 42’ for Qatar). And the expected-goals count actually favored Qatar, 0.77 to 0.64, so “Bosnia recovered better” is a winner-and-finishing truth, not an underlying-play one. The Qatar discipline read also belongs to the tournament rather than this match: the Madibo suspension stemmed from the earlier Canada game, and no fresh in-match collapse decided this one. Confidence the micro-mechanisms missed while the frame held: 80%.
🇪🇬 Egypt 1–1 Iran — the named draw path landed, the directional lean failed. The forecast leaned Egypt at 43% and named the 1–1 draw as the live alternative at 32%. The draw arrived, so the outcome sat inside the committed distribution, and the texture read held: a tight, one-goal-apiece contest decided by two resilient defenses, Saber striking early for Egypt (5’) and Rezaeian answering fast (14’). The core lean is where the read broke. The forecast had Egypt breaking a deep block, the structure it dismantled against New Zealand. Instead Iran out-created the Pharaohs by a wide margin — expected goals 1.94 to 0.81 — saw a Taremi penalty saved, struck the crossbar through Ezatolahi in the dying seconds, and had a stoppage-time Khalilzadeh winner disallowed for offside. Egypt scored early and then defended a point on goalkeeping. Outcome in-distribution and texture correct; directional lean and block-breaking mechanism falsified. Confidence the lean failed: 85%.
🇲🇽 Mexico 3–0 Czechia — the cleanest result on both ledgers. Mexico won as forecast and followed the predicted Trap-to-Arena fork almost to the script. A rotated host with top spot secured played a low-event first half — waiting 36 minutes for a shot — then struck twice in six minutes after the break (Chávez 55’, Quiñones 61’) before Fidalgo added a third in stoppage time. The compression-and-counter read held emphatically in the underlying numbers: Czechia generated 13 shots for an expected-goals figure of 0.47, volume without quality, while Mexico took 11 for 1.79 and finished its better chances. The flagged rotation hazard appeared at full strength, and the host won by three regardless, which strengthens the low-necessity-but-still-dominant reading rather than weakening it. The only miss was magnitude — a tight 2–1 understated a 3–0. Confidence the mechanism strengthened: 85%.
🇺🇸 Türkiye 3–2 USA — the favorite lost, and the model still won the analysis. The point estimate missed: the forecast leaned USA, and Türkiye won on the final kick through Ayhan in the 98th minute. Every behavioral mechanism the piece committed, though, fired exactly as written. Türkiye, scoreless across two matches and diagnosed as conversion-starved rather than creation-poor, broke the drought with three goals on an expected-goals figure of 2.71 — and out-created the host, whose 2.06 confirms Türkiye was the better side, not a lucky one. The released opponent played loose and dangerous; the flat Competitive Necessity Gradient produced the high-variance chaos the model warned about; and the rotation hazard landed hard, with Pochettino making nine to ten changes and holding Pulisic to a 58th-minute cameo (USA goals Trusty 3’, Berhalter 49’). The published forecast’s closing line read, in plain words, “don’t be shocked if Türkiye’s drought ends at SoFi.” The drought ended. A forecast can lose the result and still capture the match. Confidence the structural thesis held despite the winner miss: 85%.
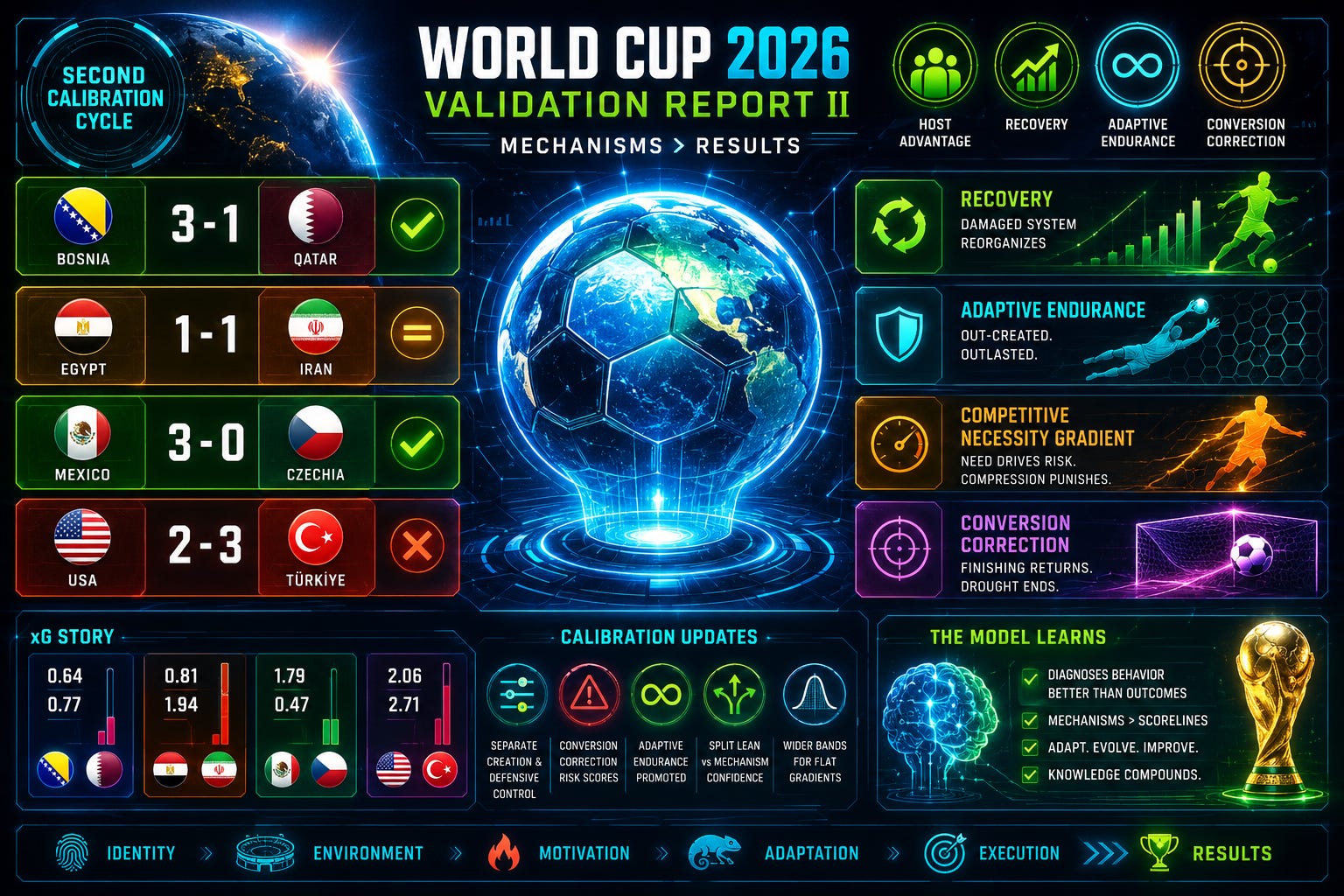
III. Mechanism-by-Mechanism Validation
1. Recovery through functional fragmentation — frame cleared, sub-read not observed. Bosnia’s win supports the central distinction the simulation drew: Bosnia’s damage was more recoverable than Qatar’s because Bosnia bent late while Qatar broke through composure. The specific late-fade prediction did not recur — Bosnia closed strong rather than fading — and Qatar edged the expected-goals count, so the recovery showed in the result more than in the run of play. Model status: frame strengthened, late-fade signature unconfirmed this cycle.
2. Qatar composure fragility — supported at tournament level, not demonstrated in-match. Qatar’s exit fits the broader fragility read: a competitive baseline that never converted into recovery, winless and bottom. The in-match decider was finishing and quality rather than a fresh discipline collapse, and the Madibo ban traced to the prior fixture. Model status: supported as a standing risk variable, not shown here.
3. Coherent recursion — supported across matches, lean falsified in the match. Egypt’s identity persisted across the group: it drew Belgium, beat New Zealand 3–1, and did not regress into pure Salah dependence. The head-to-head lean failed, though. Egypt did not break Iran’s structure, and Iran out-created it 1.94 to 0.81. Identity-persistence cleared; the claim that coherence would defeat endurance did not. Model status: supported as persistence, falsified as matchup lean, win-conversion value moderated.
4. Iran adaptive endurance — strongly cleared, and exceeded the label. Iran is the cleanest mechanism validation of the cycle. After drawing New Zealand 2–2 and Belgium 0–0, Iran drew Egypt and nearly won it, out-creating a more celebrated opponent. The system changed emphasis without losing identity across three different match states. Adaptive endurance not only held — it produced the better performance. Model status: elevated; Adaptive Endurance should become a formal dimension in knockout simulations.
5. Competitive Necessity Gradient — steep cleared, flat exposed. The steep case (Mexico–Czechia) validated cleanly: Czechia needed the match, Mexico did not, and Mexico’s compression punished the forced risk, the xG gap of 1.79 to 0.47 confirming it. The flat case (USA–Türkiye) did the opposite of producing host control — it released Türkiye’s intrinsic motivation and finishing correction. Model status: useful but conditional. Steep gradients sharpen forecasts; flat gradients require a lower confidence ceiling and an explicit conversion-correction check. Confidence in the steep–flat split: 80%.
6. Portable Home Field release — strongly cleared for Mexico. Mexico’s 3–0 moved the environment from the double-edged reading of earlier work into clear release: the crowd amplified rather than burdened, and the host converted home energy into margin, not just qualification protection. Model status: strengthened.
7. United States distributed expansion — weakened. The win over Australia without Pulisic showed genuine distribution, but the Türkiye loss exposed its limit. Türkiye out-created the United States 2.71 to 2.06, showing that distributed creation is not defensive control, especially once necessity drops. Model status: downgraded from strong to conditional.
8. Türkiye conversion-gap correction — strongly cleared. The forecast missed the winner but nailed the opponent: a finishing problem, not a creation problem, with a zero-goal record understating real danger. Türkiye scored three on 2.71 xG the moment the burden lifted. Model status: elevated; extreme finishing underperformance is a coiled spring, not a dead one.
Contact mcai@mindcast-ai.com to partner with us on Predictive Game Theory AI in Law and Behavioral Economics. To deep dive on MindCast works upload the URL of this publication into any LLM (preferably Google AI mode/Gemini, Claude, ChatGPT) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
MindCast AI is a cybernetic, predictive game-theory AI firm specializing in law and behavioral economics, applied to complex litigation, innovation systems, and geopolitical risk intelligence. Rather than extrapolating historical patterns, the firm models the mechanisms that generate institutional behavior, running Cognitive Digital Twin simulations grounded in Nash equilibrium, Stigler information economics, and the Chicago School of law and behavioral economics.
We simulate NFL and World Cup games to stress test our predictive AI system. See Super Bowl LX — AI Simulation vs. Reality.
IV. Forecast Scorecard
Four forecasts produced four distinct grades, and reading them on both ledgers at once is the point. Mexico–Czechia scored cleanest: the winner cleared and the mechanism cleared, a 3–0 backed by a 1.79-to-0.47 expected-goals edge that strengthened the compression read rather than merely confirming it. Bosnia–Qatar cleared the winner and held its recovery frame, but the late-fade and discipline sub-reads went unconfirmed, which marks it a strong frame rather than a clean sweep. Egypt–Iran split: the named draw path cleared and Iran’s adaptive endurance cleared emphatically, while Egypt’s block-breaking lean failed. USA–Türkiye missed the winner outright, yet the opponent diagnosis cleared so completely — Türkiye’s conversion correction arriving exactly as flagged — that the miss reads as useful rather than empty.
The two ledgers diverge by design. The strict winner record reads two cleared, one draw-path, and one miss. The mechanism record reads stronger: Bosnia recovery cleared, Iran endurance elevated, Mexico compression and Portable Home Field cleared, Türkiye conversion correction elevated, Egypt coherence moderated, and United States distributed expansion weakened. A stronger mechanism record than winner record is the intended hierarchy, not an accident of a good week — scorelines test the mechanism, they do not replace it.
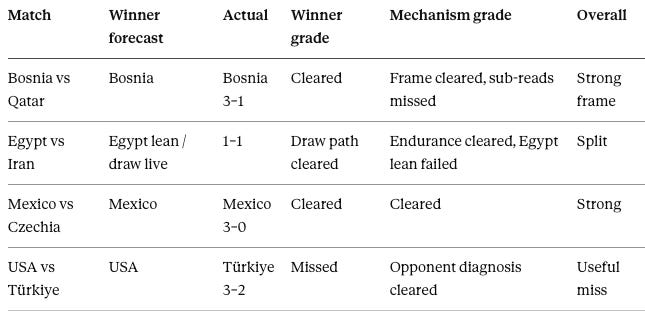
Winner record (strict): 2 cleared, 1 draw-path, 1 miss. Mechanism record: Bosnia recovery cleared; Iran endurance elevated; Mexico compression and Portable Home Field cleared; Türkiye conversion correction elevated; Egypt coherence moderated; United States distributed expansion weakened.
The second cycle produced a stronger mechanism record than winner record, which is the intended hierarchy. Scorelines test the mechanism; they do not replace it.
V. What the Model Got Right
The model separated two damaged systems that a flat read would have merged. Qatar and Bosnia both entered after heavy defeats; the simulation called Qatar composure-fragile and Bosnia fade-late-but-functional, and Bosnia’s advancement validated the distinction.
The model upgraded Iran before kickoff, and the match vindicated the call emphatically. Reclassifying Iran from disruption to adaptive endurance after the Belgium clean sheet was not noise-chasing — Iran then out-created Egypt and nearly won, the strongest single mechanism result of the cycle.
The model read Mexico’s home environment as productive and the steep gradient as decisive, and the 3–0, backed by a 1.79-to-0.47 xG edge, confirmed both.
The model diagnosed Türkiye correctly even while misreading the result. Türkiye was not inert or incoherent — it was creating without converting, and the correction arrived against the United States exactly as the published warning described.
VI. What the Model Got Wrong
The United States forecast overvalued host stability. Home environment, common-opponent strength, and distributed creation pointed to the host, but a flat-gradient, low-necessity match did not preserve host intensity, and the xG count went the other way.
The model undervalued conversion correction. Türkiye’s 62-shot, zero-goal profile carried more upside than the forecast priced; the forecast named the risk but never weighted it into the headline number. A finishing trough that extreme deserves a stronger correction term.
The model treated distributed creation as control. Distribution mattered against Australia; against a released Türkiye it became loose expansion, and attacking distribution and defensive stability need to be scored separately.
The model overvalued coherence against endurance in Egypt–Iran. The identity-persistence read was right, but the head-to-head lean assumed coherence would break a deep block, and Iran instead out-created Egypt. Picking the more coherent side in a near-even matchup is a different, weaker claim than diagnosing how each side functions, and the two should never share a confidence band.
VII. Calibration Changes After Validation Report II
Change One — Add a conversion-correction risk score. Any team with high shots, high box entries, or strong expected goals but low finishing output receives an explicit correction-risk term. Türkiye is the anchor case: a side that keeps generating chances is coiled, not dead. Confidence this would have improved the USA call: 80%.
Change Two — Split distributed creation from defensive control. Attacking distribution and defensive stability score separately, especially when a host has already qualified. Expansion is not control. Confidence: 75%.
Change Three — Elevate Adaptive Endurance to a formal construct. A team that survives — and here, outperforms — across multiple operating modes earns a higher knockout-resilience score than a one-mode side. Iran validates it. Confidence: 75%.
Change Four — Treat steep and flat necessity gradients differently. Steep gradients sharpen forecasts; flat gradients blur them and destabilize the favorite. Confidence bands drop automatically when both sides sit in low-necessity states. Confidence: 80%.
Change Five — Make Environmental Alignment directional. Environment carries a sign: positive amplification, negative expectation load, or neutral noise. Mexico read positive here; earlier Mexico work read burden. Environment does not help by default. Confidence: 70%.
Change Six — Add a standing late-window risk gate. Bosnia and Czechia both carried late-degradation signatures and Qatar carried composure risk, so every simulation includes a final-20-minute gate for fatigue, discipline, and decision decay. Confidence: 70%.
Change Seven — Separate directional lean from mechanism in every published forecast. Identity-persistence and head-to-head lean are different claims, as Egypt–Iran proved. Readers should see which one is load-bearing, and the lean should never inherit the mechanism’s confidence. Confidence: 80%.
VIII. Updated Running Record
Seven simulations now sit on the public ledger across two calibration cycles, and tracking them in one place is what keeps the series honest over time rather than match to match. The table below carries every forecast MindCast has committed and graded, first cycle and second together, so the record compounds in view rather than resetting each report. Two columns of truth travel with it — the strict winner call and the underlying result — because a forecast that lands the mechanism while missing the scoreline, or clears a named draw path without claiming a win, belongs in the record as exactly that, neither inflated nor erased.
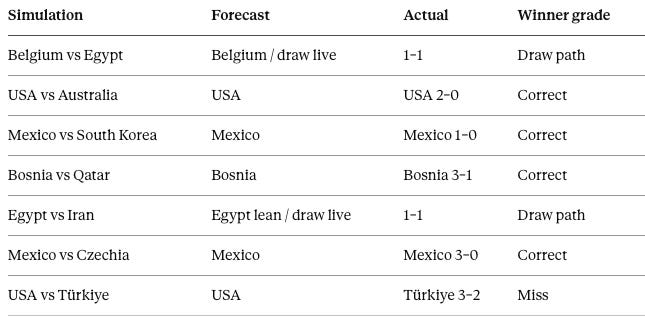
Validation Report I graded the first three lines; they appear here only to keep the cumulative ledger continuous. Strict winner record: 4–3. Two of the three non-wins (Belgium–Egypt, Egypt–Iran) landed inside explicitly named draw paths, so the mechanism-adjusted record reads five strong validations, one split, and one clean miss. Both ledgers stay on the page, because calibration discipline requires the strict count alongside the generous one.
IX. Cumulative Framework Ledger
The running record in Section VIII tracks forecasts. The ledger below tracks the theory itself — how each construct stands after Report II, and which ones this cycle actually moved versus carried forward. The distinction matters: a construct that rode along untested this cycle has not earned a fresh confirmation, and saying so is the same discipline the match grades apply.
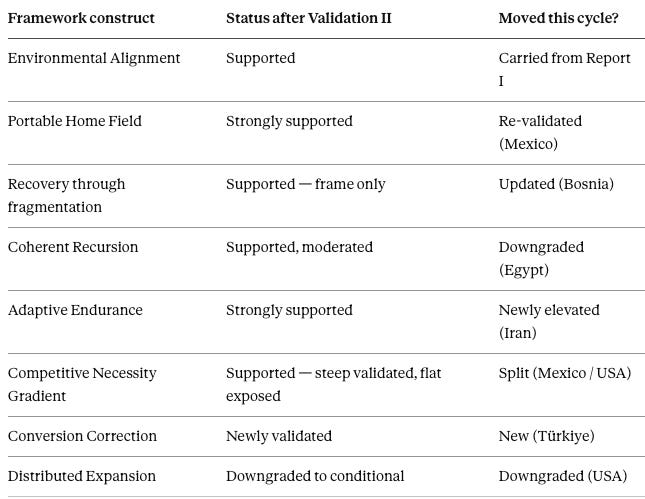
Two cells carry deliberate restraint. Recovery reads “frame only,” because the late-fade and discipline sub-mechanisms did not validate even as the recovery-versus-collapse frame held. The Competitive Necessity Gradient keeps its split visible rather than smoothing to a single word, because one end validated cleanly and the other broke the favorite — the boundary the construct was built to test.
X. Strategic Meaning for the Knockout Stage
Mexico enters the Round of 32 with a stronger Portable Home Field and environmental-release score; the 3–0 reads as a host environment turned productive. Bosnia earns a stronger recovery score, having converted a post-Switzerland reorganization into a decisive win rather than mere survival. Egypt earns a stronger persistence score but a moderated win-conversion score — coherence travels, yet Iran showed it can be held and out-created. Iran, if it advances, earns an adaptive-endurance premium, having now drawn New Zealand, Belgium, and Egypt across three different match states. The United States requires recalibration: the host profile remains dangerous, but the Türkiye loss proves the system can be exposed when necessity drops and an opponent’s conversion corrects, and the next U.S. simulation must decide whether the defeat sharpens the team or reveals structure. Türkiye exits as a standing lesson — a finishing drought is not an attacking failure.
XI. Conclusion
Validation Report II strengthens the framework because it adds distinctions, not just wins. Bosnia showed that fragmented systems can recover when function stays distributed. Qatar showed that centralized systems stay fragile when composure breaks. Egypt showed that coherent identity travels across matches — and that traveling identity does not guarantee a head-to-head edge. Iran showed that adaptive endurance can out-play a more celebrated opponent, not merely survive it. Mexico showed that Portable Home Field can become release. Türkiye showed that finishing correction can overturn a host forecast. The United States showed that distributed expansion is not match control.
The framework exits its second calibration cycle more precise than it entered. Report I proved MindCast could score its own forecasts honestly. Report II proves the model changes the right things once the evidence arrives.
MindCast does not defend the prior. MindCast improves it. Scorelines close the match; calibration improves the system. Validation Report II demonstrates that the framework improved because of its mistakes, not despite them — the objective is never to preserve the prior forecast, but to preserve the mechanism that continues to explain reality.
Graded against the published forecasts in the Mexico–USA host-nation pair and Seattle Lab II, following the method set in Validation Report I.