

⚽ MCAI Cultural Innovation Vision: World Cup Validation Report I — USA, Belgium-Egypt, Mexico
The June 20, 2026 Validation Report — The First Football Simulations, the First Calibration, and What Changes Next

Cultures Under Shared Rules — The Seattle Lab at FIFA World Cup 2026 series
Belgium vs Egypt, The Seattle Lab Opens: Plural Coordination Meets Civilizational Memory at Lumen Field
USA vs Australia, The Seattle Lab Under a Home Crowd: Recombinant Innovation Meets Resilient Pragmatism on Juneteenth
MindCast Special Series — a deliberate stress test of the MindCast system beyond the controlled venue of the MindCast Seattle Lab
When a FIFA World Cup Model Picks France and the Economist Picks Argentina
Mexico vs South Korea, Home Field, Carried: A Diaspora Stress Test in Guadalajara
Forthcoming
Seattle Lab II — Qatar–Bosnia (Jun 24) + Egypt–Iran (Jun 26)
Host-nation pair — USA–Türkiye (Jun 25) + Mexico–Czechia (Jun 24)
Seattle knockouts — Round of 32 (Jul 1) + Round of 16 (Jul 6)
Validation Report II — grades Seattle Lab II, converts the Recursion line on the dashboard
Executive Summary
Three completed simulations now form the first validation set for MindCast AI football forecasting. No football simulations existed before the 2026 World Cup project, so Belgium–Egypt, USA–Australia, and Mexico–South Korea represent the first football applications of the broader MindCast foresight framework previously used across law, governance, economics, and institutional forecasting.
Early validation matters more than raw accuracy, because a new forecasting framework earns credibility through calibration rather than perfection. The objective was never to defend the model; the objective was to find where it succeeds, where it fails, and how it improves. Three results provide the first chance to run that test in public, against a scorecard committed before kickoff.
The headline is honest on both sides. The framework called two winners correctly and missed one, while its structural mechanisms held in all three matches — a split that tells you exactly what kind of instrument this is.
I. What Was Forecast
Each simulation committed the same artifacts before its match: a structural thesis, a scoreline forecast labeled as secondary output, a most-likely result, and a game-regime classification. The table below records all three calls as published, each piece cited by title for the reader who wants the original.
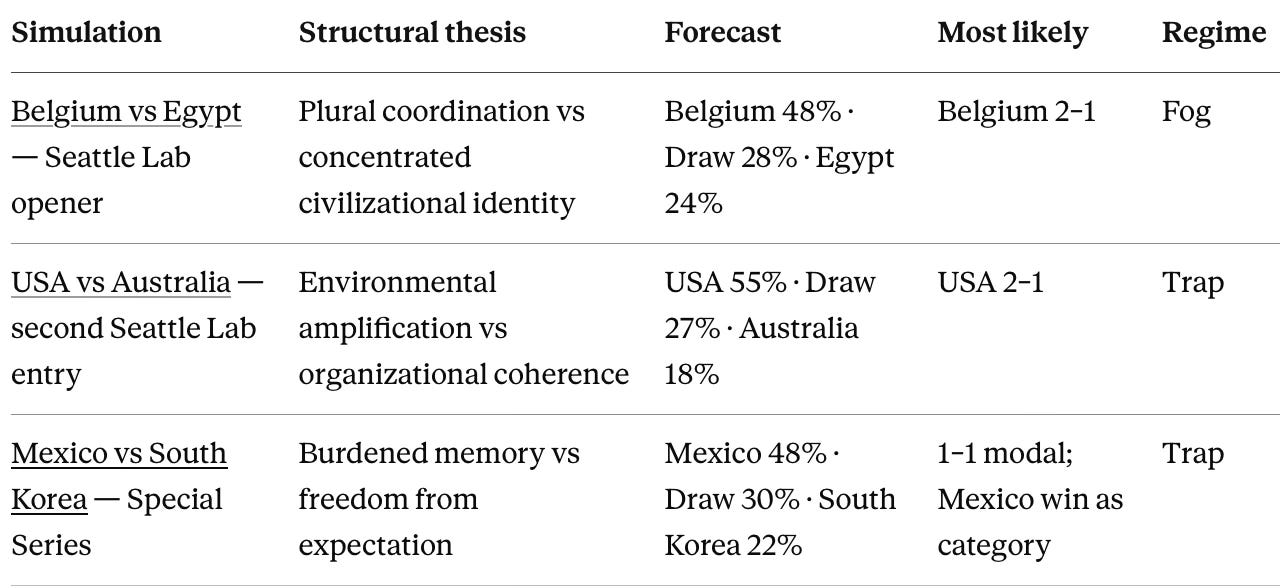
The three calls share a common spine: each names a mechanism first and a scoreline second. Grading that spine against three results is the work of the next section.
II. What Happened
The results landed close to the structural calls and well off two specific gates, so the detail below grades mechanism first, then scoreline, then the gate that resolved most clearly.
🇧🇪 Belgium–Egypt — actual 1–1. The winner forecast missed, since the simulation favored Belgium and the match drew. The regime call, Fog, cleared almost literally: Fog describes a match in which neither system imposes and the favorite cannot convert talent into control, and Egypt led from the 19th minute to the 66th — a span longer than the Pharaohs had ever led across their entire prior World Cup history. Belgium rescued the draw only when a late substitute forced an own goal seconds after entering. The structural thesis earns partial validation, because the simulation correctly identified Egypt’s ability to stay competitive while overstating Belgium’s advantage. The result sat inside the forecast envelope; the scoreline did not.
🇺🇸 USA–Australia — actual 2–0. The winner forecast was correct, and the regime call is the instructive one. The simulation classified the match as a Trap and committed, in advance, that an early USA goal and a comfortable halftime lead would falsify Trap and read Arena instead. USA scored in the 11th minute, led 2–0 by the 43rd, and finished on 63% possession, so the primary label was falsified and the pre-committed alternative occurred — the falsification contract functioning exactly as written, not failing. The environmental-amplification thesis held cleanly: host-environment advantage outweighed Australia’s superior organization, and the Transmission gate that predicted territorial dominance cleared at 63%.
🇲🇽 Mexico–South Korea — actual 1–0. The winner forecast was correct and the most-likely result category, a Mexico win, held, even though South Korea carried the stronger coherence profile. The Trap regime cleared in its purest form, because Mexico won on just 43% possession to Korea’s 57% — a burdened favorite grinding out a one-goal result rather than running free, which is the loss-aversion read made visible. One gate triggered clearly against the call: the Transmission Saturation gate predicted Mexican territorial dominance of at least 55% possession, and Mexico had 43%, with the decisive goal arriving in the 50th minute. The home crowd mattered, but it surfaced in the decisive moment rather than in control of the ball. The Portable Home Field thesis survived; the possession proxy for it did not.
Across the three, the mechanism outperformed the scoreline in every match, which is the pattern the framework is built to produce.
III. Aggregate Validation
The cohort grades cleanly once the structural thesis, the regime, and the winner are scored separately — and the order matters, because the framework is built to forecast the mechanism that decides a match, not the scoreline it produces. The table below leads with the mechanism and reports the winner last, as secondary output.
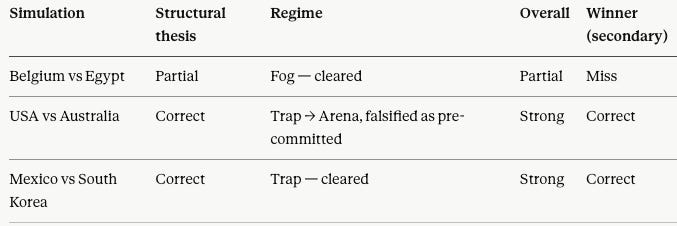
The structural-thesis record stands at 2.5–0.5, and the regime record at two clean reads plus one pre-committed falsification rather than a blind miss. The winner record, reported last because it is the downstream byproduct, stands at 2–1.
The ordering is the whole philosophy. MindCast AI forecasts the mechanism that decides a match — the way the Super Bowl call led with how the game would be won, not the final number — and treats the scoreline as secondary output. A framework that identifies the correct causal structure while missing a scoreline has found something a strength model cannot; a framework that names the right winner for the wrong reason has found nothing. The structural framework outperformed the scoreline forecast, and the gap is the point of the exercise.
IV. Cumulative Model Dashboard
A standing record lets a reader track the framework across cycles rather than one report at a time, so every Validation Report updates the same dashboard. The mechanism metrics lead, and the winner forecast sits last as the secondary, downstream check it is. Report I sets the opening line.

The dashboard carries forward into Validation Report II, where the Egypt–Iran recursion test converts the pending line into a result. A cumulative record earns trust precisely because it cannot quietly drop a miss between cycles.
Contact mcai@mindcast-ai.com to partner with us on Predictive Game Theory AI in Law and Behavioral Economics. To deep dive on MindCast works upload the URL of this publication into any LLM (preferably Google AI mode/Gemini, Claude, ChatGPT) and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
MindCast AI is a cybernetic, predictive game-theory AI firm specializing in law and behavioral economics, applied to complex litigation, innovation systems, and geopolitical risk intelligence. Rather than extrapolating historical patterns, the firm models the mechanisms that generate institutional behavior, running Cognitive Digital Twin simulations grounded in Nash equilibrium, Stigler information economics, and the Chicago School of law and behavioral economics.
We simulate NFL and World Cup games to stress test our predictive AI system.
V. The First Major Findings
Five findings emerge from the cohort, each grounded in at least one result rather than asserted.
Finding One — environment matters more than conventional models assume. USA–Australia and Mexico–South Korea reinforced the same observation: capability alone did not explain either outcome, and environmental conditions materially shaped both. Environmental Alignment earned its place as a forecasting variable.
Finding Two — the Portable Home Field appears real. Mexico supplied the first validation case, with supporter ecosystems carrying a meaningful home-field effect beyond geography. The construct survives first contact with data, though further testing remains necessary.
Finding Three — coherence and organization are necessary but not sufficient. The more internally aligned side lost in both decisive matches: Australia entered with the stronger organization and South Korea with the stronger coherence, and both lost to opponents carrying greater talent and environmental support. The model should continue treating coherence as required but never decisive on its own.
Finding Four — near-neutral environments remain the hardest to forecast. Belgium–Egypt produced the weakest result, correctly identifying a competitive match while overstating the favorite. Future simulations should carry lower confidence in near-neutral settings with limited tournament information.
Finding Five — the first goal’s timing is the regime hinge. Both backed favorites won, and a single variable separated the romp from the grind. USA found an early goal and produced an Arena, dominant on 63% possession; Mexico never did, scored once after the interval, and produced a Trap, a one-goal win on 43%. The two regimes did not merely label the matches — they described the mechanism by which each unfolded, with the timing of the first goal as the switch between them.
VI. What Changes Next
The misses proved more useful than the hits, because each one points at a specific fix. Five adaptations carry into the next set of simulations.
Change One — lead with the regime fork, not a single label. The USA result showed an early goal flipping Trap into Arena, a switch the simulation had named in advance. Future simulations will present the regime as a fork with its trigger stated up front, the early goal as the hinge between grind and romp, rather than committing one label and gating the other beneath it.
Change Two — expand and refine the branching futures. Mexico–South Korea introduced the first three-future structure, and the framework performed better when it specified multiple pathways. Future simulations will widen that approach and add a second-half branch, since Mexico’s 50th-minute goal fell in the gap between futures keyed only to the first half.
Change Three — redefine the environmental gates. Mexico won on 43% possession, so possession share was the wrong observable for crowd amplification. Future simulations will measure amplification through shots on target, big chances, and the timing of the decisive goal, and will separate positive amplification from expectation burden explicitly — the burdened favorite grinds and wins narrow, while the free favorite in a favorable environment dominates.
Change Four — formalize the Portable Home Field as an actively measured construct. Mexico supplied the first validation case, and Morocco, Argentina, and Brazil become the next tests. The construct now moves from theory into active measurement across the tournament.
Change Five — sharpen confidence calibration and lean on measured recursion. Belgium–Egypt demonstrated that a cultural contrast alone does not justify high confidence, so future simulations will distinguish signal strength from forecast confidence. Recursion also becomes measurable now that Egypt has set a baseline, so the next cycle will measure adaptation directly rather than infer it from history.
Together the five adaptations sharpen the same instrument rather than replace it. The mechanism-first core held across all three matches; the refinements target how the gates are defined and how the futures are partitioned, which is where the first set leaked signal.
VII. The Next Tests
The next simulations matter more than the first three, because the framework now carries baseline validation and the forward tests probe recursion directly.
Egypt vs Iran — June 26, the recursion keystone. Egypt was deliberately established as the Seattle Lab’s longitudinal case, and the return to the same Lumen Field tests whether recursion can be measured rather than inferred. Egypt’s opener set a demanding baseline, a side that led a World Cup favorite for forty-seven minutes, and the second match will validate or weaken one of the framework’s core dimensions.
Czechia vs Mexico — Mexico’s final group match, the second Portable Home Field test. Mexico now carries a validated environmental advantage at a home venue, and the next match determines whether the advantage persists against a different opponent.
The remaining Seattle slate. Qatar–Bosnia arrives first, on June 24, with both sides freshly readable after heavy defeats. The Round of 32 on July 1 and the Round of 16 on July 6 continue testing Environmental Alignment, Cultural Signal Integrity, Recursion Strength, and the Portable Home Field under a controlled civic environment. The value of the project compounds with every completed calibration.
VIII. Closing Assessment
Three completed simulations do not prove a forecasting framework, but they can establish whether one deserves further testing. The first football applications of MindCast AI produced two correct winner forecasts and one miss, strong support for Environmental Alignment, initial support for the Portable Home Field, a confirmed reading of coherence as necessary but insufficient, and a clean pre-committed falsification in the USA regime call. Recursion Strength remains the open question the next cycle is built to resolve.
The calibration record matters more than the win-loss record, because prediction systems earn trust through visible adaptation rather than through perfection. The first football forecasting cycle therefore achieved its primary objective: the framework survived first contact with reality, and the next cycle determines whether it improves.