

MCAI Economics Vision: How Cybernetic Feedback Latency, Loop Architecture, and Ashby's Viability Condition Resolve Consumer AI Device Competition
MindCast Consumer AI Device Series: Installment I V Consumer AI as a Cybernetic Control System. Who Closes the Loop?

MindCast Consumer AI Device series publications: Installment I — The Intelligence Gap: Apple’s AI Strategy and the Commoditization Bet | Installment II — The Apple AI Challenger Framework: Google, Samsung, and the Intelligence Layer | Installment III — The Consumer AI Device Intelligence Layer: Value Capture Under Interface Drift | Installment IV How Cybernetic Feedback Latency, Loop Architecture, and Ashby’s Viability Condition Resolve Consumer AI Device Competition
Executive Summary
Consumer AI competition has already resolved at the control layer. Product competition persists, but no longer governs outcomes. Closed-loop systems now determine which institutions accumulate behavioral control and which become inputs to those that do.
Installment I The Intelligence Gap: Apple’s AI Strategy and the Commoditization Bet, Installment II The Apple AI Challenger Framework: Google, Samsung, and the Intelligence Layer, and Installment III The Consumer AI Device Intelligence Layer: Value Capture Under Interface Drift mapped the actors. The Cybernetics Umbrella defined the architecture. Installment IV delivers the integration layer: a unified control system diagnosis that identifies not which institution has the best product, but which institution has closed the loop that governs every other institution’s options. The consumer AI device market has been analyzed as a product race, a platform competition, and a capability arms race. All three framings correctly identify competitive features. None identifies the governing mechanism. Norbert Wiener named it in 1948: adaptive systems are controlled not by what they own, but by how they sense, process, act, and learn from feedback. The institution that minimizes feedback latency and maximizes loop closure integrity does not need to win the product layer. It builds the system inside which the product layer plays out.
MindCast AI Proprietary Cognitive Digital Twin (MAP CDT) execution across all nine institutions in the series — run through the cybernetic control framework — produces a single structural finding: the consumer AI device market is not converging toward a product winner. It is converging toward viable closed-loop systems. Viability, in Ashby’s precise sense, means the loop-closing institution matches the variety of the competitive system it operates within. Only one institution in the current system achieves viability unconditionally. Two achieve it conditionally. Six do not achieve it at all — and each of those six is structurally dependent on an institution that does.
The Feedback Latency Index (FLI) is the governing metric the prior installments approached but never named directly. Latency, not model quality, determines long-run control.
THE SYSTEM IN FIVE LINES
AI competition resolves at the control layer, not the product layer.
Control means closing behavioral feedback loops — sensing, processing, embedding, repeating.
FLI measures how fast the loop closes. LCS measures where it starts. Both determine who governs.
Behavioral lock-in — not interface ownership — determines durable control.
The market converges to 2–3 viable loops. Every other institution becomes an input to one of them.
The MAP CDT Foresight Simulation assigns viable closed-loop status to Google unconditionally, to Microsoft within the enterprise tier, and to OpenAI conditionally under concentration. Apple’s semi-closed loop architecture produces a drift-stable equilibrium that sensing latency will erode before interface dominance can compensate. Samsung remains an open-loop distributor constrained by the OS layer its most dangerous competitor controls. Anthropic’s constrained adaptive loop holds precision positioning but requires concentration to persist longer than Meta’s commoditization acceleration may permit.
Six falsifiable system-level predictions follow from the cybernetic control analysis, each with observable confirmation signals, falsification conditions, and probability weights. The predictions extend and sharpen the six system-level predictions produced by the Cybernetic Overview of the MindCast Consumer AI Device Series — adding the causal layer that the Overview’s Ashby analysis established structurally but left unmeasured.
FOR INVESTORS
Standard AI platform analysis prices model capability, distribution share, and services revenue. The Cybernetic Control Model of AI Markets (CCM) framework identifies five metrics none of those measures captures: Feedback Capture Rate (FCR), Adaptation Velocity (AV), Loop Closure Integrity (LCI), Behavioral Lock-In Coefficient (BLIC), and the Feedback Latency Index (FLI) as the composite. None are tracked in any analyst model. Google leads the full Cybernetic Control Vision (CCV) panel — FCR 0.95, AV 0.93, LCI 0.92, BLIC 0.90, FLI 0.91. Microsoft’s BLIC of 0.91 is the highest in the system, confirming that enterprise workflow embedding produces more durable behavioral defaults than ambient sensing. OpenAI’s AV of 0.92 matches Google’s but its LCI of 0.82 marks the infrastructure ceiling the Azure dependency imposes. Apple’s Causal Signal Integrity (CSI) score of 0.78 falls below the 0.80 high-confidence deployment threshold — the first institution in the series to breach it downward — quantifying the gap between Apple’s narrative coherence and its execution capacity. Investors monitoring benchmark model releases are tracking a lagging indicator of a competition that has already moved to the loop layer.
FOR CORPORATE STRATEGY
Every enterprise platform that licenses AI capability without owning the feedback loop is operating as an open-loop distributor — the same structural classification as Samsung. The cybernetic control framework applies directly to enterprise software, regulated industry platforms, and any institution embedding AI capability it did not build and cannot retrain. The governing question is not ‘which model should we license?’ The governing question is: ‘does our institution close the behavioral feedback loop, or does the institution we license from close it for us?’ The answer determines where margin accrues over a 36-to-60-month horizon.
I. The Governing Structure: Cybernetic Control, Not Market Competition
Markets clear through price and product competition when outputs are measured and compared at discrete intervals. Control systems govern through continuous feedback — sensing the current state, comparing it against the desired state, acting to reduce the deviation, and learning from the correction. Consumer AI has crossed the threshold from the first structure to the second. Prices still clear. Products still compete. But the governing mechanism has shifted to feedback architecture, and the prior three installments have been documenting its consequences without naming it directly. Installment IV names it directly: the Cybernetic Control Model of AI Markets (CCM).
Wiener established the foundational claim in 1948: adaptive systems are controlled not by what they possess but by how they regulate — sense, process, act, correct. Ashby formalized the structural constraint: a controller that cannot match the variety of the system it seeks to regulate loses governance. Beer operationalized the recursive requirement: durable governance demands loops that monitor loops, not just outputs. Three theorists, one architecture — and the consumer AI device market is the first commercial system large enough to run the proof at scale. The Control Law of Consumer AI states the governing dynamic in a single line: control accumulates where feedback loops close fastest at the earliest capture surface.
Translating those three theoretical structures into the consumer AI device market produces a reinterpretation of Installments I through III that the individual installments could not generate from inside their own analytical frames. Each installment analyzed institutional strategy. The cybernetic frame reveals institutional loop architecture — and loop architecture determines which strategies are self-reinforcing and which are structurally precarious regardless of how well they execute.
Cybernetic Reinterpretation of Prior Installments
Apple (Installment I) controls the input channel — the device surface through which users initiate AI interaction. Input channel control is not loop closure. Closing the loop requires Apple to sense how users respond to AI output, process that signal through an intelligence layer it owns, and embed the correction as a behavioral default that strengthens the next interaction. Apple’s privacy constraint deliberately limits the sensing step. Apple’s OS cycle caps the processing velocity. Apple’s external intelligence dependency prevents behavioral embedding from routing through Apple-controlled systems. Apple owns the most valuable entry point into the loop and exits the loop at the first step. Apple monetizes the interface layer while exporting behavioral learning to its competitors. Apple captures interaction value and forfeits learning value — the layer that compounds. Classification: semi-closed loop.
Google (Installment II) operates near-continuous sensing through search queries, Android behavioral telemetry, Chrome browsing patterns, and ambient assistant invocations. Processing routes through Gemini at frontier capability. Behavioral embedding occurs at the OS layer — the routing default fires below the level of explicit user choice, compounding with each invocation. Google does not need users to choose Gemini. Google needs Android to route to Gemini before the choice surfaces. The contrast with Apple is the sharpest diagnostic in the series: Apple’s user initiates an interaction, reaches an external AI, and the learning leaves the Apple system entirely. Google’s user initiates an interaction, reaches Gemini through Android’s default, and the learning stays inside Google’s loop. Same user action. Opposite control architecture. Classification: viable closed loop.
Samsung (Installment II) owns global device distribution and accumulates device-layer behavioral telemetry. Samsung Research produces genuine intelligence capability. Exynos provides independent chip architecture. Each element of loop closure exists — but the OS layer that connects sensing to behavioral embedding routes through Google. Samsung’s loop closes up to the point where Android’s routing logic begins. At that point Samsung becomes an input to Google’s loop rather than the operator of its own. Classification: open-loop distributor.
Microsoft (Installment III) executes enterprise-to-consumer bleed through GitHub Copilot at the code layer, Office 365 Copilot at the productivity layer, and Azure AI at the compute layer. Each captures behavioral defaults that were previously neutral with respect to AI routing. Once those defaults are set, the consumer device becomes a secondary execution surface for intelligence routed through Microsoft’s enterprise stack. Microsoft’s FLI advantage is not speed — it is depth. Enterprise workflow embedding produces behavioral defaults that compound faster than consumer habit formation and resist switching more durably. Classification: enterprise closed loop.
OpenAI (Installment III) runs a consumer-to-enterprise bleed mechanism through ChatGPT’s interaction gravity. Rapid iteration cycles produce fast behavioral adaptation at scale. The structural ceiling is infrastructure dependency: Microsoft controls the Azure compute architecture OpenAI requires to maintain frontier capability. OpenAI closes the loop at the interaction layer but not at the infrastructure layer — leaving its learning system partially governed by a competitor. Every behavioral default OpenAI embeds in a user compounds inside a system whose foundational parameters Microsoft can adjust. Classification: consumer adaptive loop, conditionally viable.
Anthropic (Installment III) operates a safety-gated adaptive loop that produces high-trust enterprise relationships but limits sensing breadth and processing velocity by design. The constraint is intentional and identity-preserving — Anthropic’s grammar does not permit the ambient data ingestion that would accelerate behavioral embedding. Anthropic’s loop closes precisely, not pervasively. Classification: constrained adaptive loop.
Meta (Installment III) functions as the system’s negative feedback mechanism against concentration. Llama releases compress the capability gap that gives frontier providers pricing power. Meta does not seek to close a behavioral feedback loop in the consumer AI routing sense — Meta seeks to prevent any other institution’s loop from closing completely enough to threaten the advertising monetization architecture. Classification: commoditization disruptor, intentional non-closure.
Mistral achieves loop closure within sovereign and regional markets — high-trust, government-adjacent deployment contexts where global behavioral default formation is not the competition surface. Classification: fragmented regional loop. The Control Law holds across all eight classifications: control accumulates where feedback loops close fastest at the earliest capture surface. Every institution’s position in the table above is a direct output of how it scores on those two dimensions.
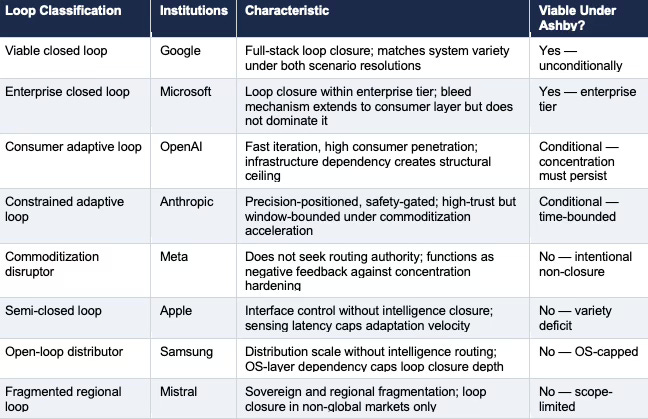
Table 1. Cybernetic Loop Classification Matrix — nine institutions across four classification dimensions. Viability assessed against Ashby’s Requisite Variety condition: does the institution’s loop architecture match the variety of the competitive system under both scenario resolutions?
The CCM Named-Concept Architecture: Loop Capture Surface (LCS), Feedback Latency Index (FLI), and the System Equation
The Cybernetic Control Model of AI Markets (CCM) operates through three named concepts that translate the loop classification matrix into measurable, trackable variables. Each concept is independently observable. Together they produce a single system equation that investors, corporate strategists, and competitive analysts can apply to any AI platform competition without requiring the full CDT Foresight Simulation architecture.
Loop Capture Surface (LCS) is the primary surface where behavioral data enters the loop. LCS determines the depth and frequency of signal ingestion before any processing or embedding occurs. Google’s LCS is ambient — search and Android generate continuous behavioral signal without requiring the user to initiate an explicit AI interaction. Microsoft’s LCS is task-embedded — Office and GitHub workflows generate behavioral signal as a byproduct of work the user was already doing. OpenAI’s LCS is interaction-initiated — ChatGPT generates signal only when the user consciously opens the interface. Apple’s LCS is entry-point-limited — device UI interaction generates signal that exits the loop at the intelligence boundary. LCS explains why institutions with similar FLI scores can have structurally different compounding trajectories: ambient capture surfaces accumulate behavioral signal continuously, while interaction-initiated surfaces accumulate it episodically. Continuous compounding over time dominates episodic compounding regardless of the quality of each individual interaction. LCS determines where control begins. FLI determines how fast it compounds. Google holds the early capture position and the fast loop simultaneously — the only institution in the system that does. OpenAI holds the fast loop without early capture. Apple holds early capture without the loop.
The Control Law of Consumer AI follows from LCS and FLI together: systems that capture behavior earlier and learn faster will dominate systems that interact later and learn slower, regardless of product quality at any point in time. Product quality determines which interaction the user initiates. Loop architecture determines what happens to that interaction afterward — and it is the afterward that compounds into governance. Loop Inversion is the structural consequence of this dynamic: institutions that appear upstream in the value chain — at the interface, at the device, at the distribution layer — become downstream in control terms if they do not own the learning that follows the interaction. Apple is upstream in every conventional product analysis and downstream in every control analysis. Samsung is upstream in hardware and downstream in routing. Loop Inversion is not a competitive reversal that happens suddenly. It compounds silently, interaction by interaction, until the interface that once signified dominance becomes the entry point to someone else’s loop.
The CCM System Equation expresses control power as a function of the three CCM variables:
Control Power ≈ FLI × Loop Capture Surface × Embedding Depth
FLI measures the speed and tightness of loop closure. LCS measures where and how continuously behavioral signal enters the loop. Embedding Depth measures how durably loop outputs reshape user workflow and cognitive defaults. Multiplying the three variables produces a control power score that predicts governance trajectory more accurately than any single-dimension measure. If any term approaches zero, control collapses regardless of strength in the others. Google’s control power is structurally dominant because all three variables are simultaneously high. OpenAI’s control power is capped because LCS is interaction-initiated rather than ambient — the loop closes fast but starts late. Apple’s control power collapses at the FLI term: sensing latency structurally limits the loop before processing or embedding can compound.
II. The Feedback Latency Index: The Variable the Market Has Not Priced
Installment I, Installment II, and Installment III each gestured toward speed of adaptation as a competitive variable. Installment I called it Apple’s ‘moderate to slow’ adaptation velocity. Installment II noted Google’s ‘high’ adaptation velocity. Installment III ranked Microsoft’s enterprise-first grammar as ‘high depth, moderate speed.’ None of those descriptions produced a measurable variable that could be tracked across institutions and updated as observable signals arrived.
The Feedback Latency Index operationalizes the variable. FLI is a composite measure of three dimensions: sensing latency (how quickly the institution ingests behavioral signal from user interactions), processing velocity (how rapidly the institution routes that signal through intelligence architecture and updates its output), and behavioral embedding depth (how durably the institution’s responses shape user workflow and default invocation patterns). Higher FLI scores indicate tighter loop closure with lower latency — and therefore stronger self-reinforcing governance over time. Every competitive outcome described in Installments I through III can be restated as a function of FLI differentials.
FLI scores are derived from MAP CDT Foresight Simulation execution against each institution’s behavioral profile, constraint stack, and observable deployment architecture. Each score carries a Causal Signal Integrity (CSI) validation weight. Scores above 0.80 indicate high loop closure confidence. Scores between 0.60 and 0.79 indicate conditional loop closure — viable under specific scenario resolutions. Scores below 0.60 indicate open or semi-closed loop architectures that cannot sustain behavioral default governance under competitive pressure.
MAP CDT Core Integrity Metrics
Every CDT Foresight Simulation score rests on four integrity dimensions validated before prediction deployment. Action-Language Integrity (ALI) measures alignment between stated institutional strategy and observed execution. Cognitive-Motor Fidelity (CMF) measures how accurately the CDT replicates real-world behavioral output. Relational Integrity Score (RIS) measures grammar consistency across multi-agent interaction contexts. Causal Signal Integrity (CSI) is the composite deployment threshold — scores above 0.75 authorize forward prediction deployment. Apple’s high ALI (0.91) combined with low CMF (0.75) is the quantitative signature of the drift-stable diagnosis: narrative coherence does not match execution capacity.

Table A. MAP CDT Core Integrity Metrics — four validation dimensions per institution. CSI scores above 0.75 authorize prediction deployment. Apple’s high ALI (0.91) combined with low CMF (0.75) confirms the drift-stable diagnosis quantitatively. Samsung’s CSI of 0.72 falls below the deployment threshold, confirming structural OS dependency limits predictive confidence for any independent Samsung strategy forecast.
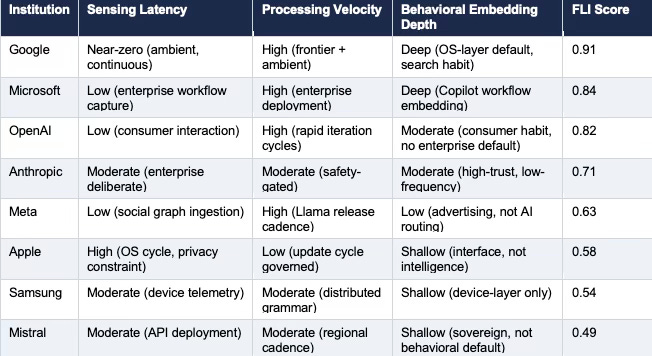
Table 2. Cybernetic Control Vision (CCV) — full five-metric scoring per institution. Feedback Capture Rate (FCR) measures signal ingestion depth. Adaptation Velocity (AV) measures processing and update cadence. Loop Closure Integrity (LCI) measures end-to-end loop completeness. Behavioral Lock-In Coefficient (BLIC) measures default embedding durability. FLI is the composite. Dashes indicate institutions not scored on the full CCV panel due to insufficient public deployment data for those sub-dimensions; FLI scores for all institutions are still derived from available signals.
Why Latency Beats Capability
The intuition that model quality determines AI market outcomes is coherent at a product layer. At the control system layer, model quality is an input to the feedback loop — not the loop itself. A system with inferior model quality but tighter feedback closure will outperform a system with superior model quality and slower feedback latency over any sustained time horizon because the tighter system compounds behavioral defaults faster than the capability gap widens.
Google’s FLI score of 0.91 does not mean Google has the best model. Gemini is competitive but not unambiguously dominant against GPT-4o or Claude across all evaluation dimensions. Google’s 0.91 means Google senses user behavior continuously through ambient Android telemetry, processes it through a frontier system, and embeds the result as an OS-layer default before the user recognizes that a routing decision was made. The behavioral default forms before the competitive comparison occurs.
Apple’s FLI score of 0.58 does not mean Apple has a bad product. Apple Intelligence is a competent device-layer AI implementation by any feature benchmark. Apple’s 0.58 means Apple’s sensing latency is structurally capped by its privacy architecture, Apple’s processing velocity is governed by OS update cycles rather than model improvement cycles, and Apple’s behavioral embedding routes through OpenAI’s and Google’s intelligence rather than Apple’s. Apple’s loop closes at the interface layer and opens at the intelligence layer. Capability advantage cannot compensate for that structural gap because capability advantage operates inside the loop while the loop governance operates above it.
Interface ownership and loop ownership are not the same thing. Apple has built the most valuable version of the wrong kind of control.
III. Ashby’s Viability Condition Applied to All Nine Institutions
The Cybernetics Umbrella established Ashby’s Law of Requisite Variety as the theoretical foundation for the MAP CDT architecture: a controller must match the variety — the number of possible states — of the system it seeks to regulate. Installment IV applies the viability condition not to the competitive system as a whole, but to each institution’s loop architecture specifically.
A viable closed loop, in Beer’s Viable System Model sense, requires three properties simultaneously: the loop must close (sensing connects to processing connects to behavioral embedding), the loop must match the variety of the environment it operates in (FLI score sufficient to track competitive state changes), and the loop must be recursive (the institution monitors its own loop performance and adjusts the loop’s parameters, not just its outputs). Recursive self-monitoring is the property that separates institutions that merely close feedback loops from institutions that maintain governance when the environment changes.
Dominance Matrix — Cross-Institution Influence Scores
Dominance is defined as which institution’s loop captures, shapes, or constrains another institution’s behavioral output. Scores reflect directional influence on a 0–1 scale derived from MAP CDT multi-agent interaction modeling. A score of 0.80 or above indicates structural dominance — the influencing institution’s loop architecture materially constrains the influenced institution’s strategic options regardless of the influenced institution’s own choices. Google’s outbound dominance row and Microsoft’s 0.75 influence over OpenAI are the two highest-consequence relationships in the system. Dominance does not require superior products. It requires controlling the path through which all products are experienced.

Table C. Dominance Matrix — directional influence scores across seven institutions (0–1 scale). Google exhibits highest outbound dominance concentrated at the OS routing and behavioral default layers. Microsoft’s 0.75 influence over OpenAI is the series’ most consequential bilateral dependency. Meta’s row reflects system-wide disruption pressure rather than direct control — high influence scores without corresponding loop closure.
Google — Viable Unconditionally
Google’s dual-loop position — OS-layer distribution dominance plus Gemini frontier capability — means Google’s loop architecture matches the variety of the consumer AI device system under both scenario resolutions. Under commoditization, Android’s 83% global OS share produces distribution variety sufficient to govern routing defaults even when capability differences compress. Under concentration, Gemini’s frontier capability produces intelligence variety sufficient to sustain pricing power and behavioral embedding depth. No other institution in the series holds a loop architecture that closes under both scenarios without requiring external conditions to resolve favorably. Google’s advantage is not scale alone but dual-loop closure — distribution and intelligence reinforcing each other in a recursive system where each loop’s output becomes the other loop’s signal.
Google’s recursive monitoring operates through the Android ecosystem telemetry that gives Google signal on how its own loop is performing — which routing defaults are holding, which are being circumvented, and which are producing the behavioral embedding depth that constitutes durable governance. Google can adjust the loop’s parameters (Gemini default positioning, Android API architecture, developer incentive structures) in response to signals the loop itself generates. Recursive viability is structurally intact.
The condition that disrupts Google’s viable closed loop is not competitive pressure from any institution currently in the system. Antitrust enforcement severing the Android-to-Gemini routing connection is the only observable event that would reduce Google’s effective loop variety to either distribution or capability but not both — eliminating the dual-loop advantage that produces unconditional viability. The falsifiable prediction in Section V addresses that condition directly.
Microsoft — Viable Within the Enterprise Tier
Microsoft’s enterprise closed loop achieves viability within the enterprise tier because the variety of enterprise AI decision-making environments is matched by Microsoft’s Copilot deployment depth across productivity, code, and infrastructure layers. GitHub Copilot closes the loop at the developer behavior layer. Office 365 Copilot closes it at the knowledge worker behavior layer. Azure AI closes it at the enterprise infrastructure decision layer. Each loop is recursive: Microsoft’s usage telemetry from Copilot deployments informs model update priorities, deployment architecture adjustments, and enterprise contract structure — the loop monitors itself and adjusts its own parameters.
Microsoft’s viability condition is not unconditional because the enterprise tier does not constitute the full variety of the consumer AI device system. Consumer behavioral defaults form through pathways — ambient invocation, device interaction, casual query patterns — that Microsoft’s enterprise-first grammar does not directly address. Microsoft’s FLI score of 0.84 reflects high loop closure depth within enterprise contexts and moderate closure depth in the consumer-to-enterprise bleed direction. Full system viability would require consumer ambient sensing that Microsoft’s grammar and constraint stack currently do not support.
Apple — Semi-Closed, Structurally Non-Viable
Apple’s loop architecture closes at the interface layer and opens at the intelligence layer. Sensing capability is constrained by the privacy architecture Apple’s brand requires. Processing velocity is governed by OS update cadences rather than model improvement cycles. Behavioral embedding routes through OpenAI’s and Google’s intelligence systems — meaning the behavioral defaults that form from Apple device AI interactions compound inside competitors’ loops rather than Apple’s. Apple’s loop architecture produces a structurally non-viable controller: the interface captures the interaction, but the intelligence layer captures the behavioral default.
Apple’s semi-closed status is not a failure of strategy. Apple’s constraint stack — brand, margin, ecosystem, operational — makes the semi-closed architecture the rational output of Apple’s grammar. Apple cannot increase sensing depth without violating the privacy narrative. Apple cannot accelerate processing velocity without restructuring the OS cycle. Apple cannot close the intelligence loop without internalizing capability that its brand constraint requires it to present as Apple-native rather than acquired. Each constraint produces the semi-closed architecture as its logical consequence. The loop Apple has built is the most capable version of the architecture its grammar permits. The grammar does not permit viability.
Contact mcai@mindcast-ai.com to partner with us on Predictive Cognitive AI in Law and Behavioral Economics. To deep dive into MindCast AI upload the URL of any publication into any LLM and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure.
Recent projects: Chicago School Accelerated — AI Infrastructure Patent Coordination | The Power Stack — How Energy Infrastructure Became the New AI Battleground | Why the “China Invades Taiwan by 2027” Narrative Misprices the AI Industrial Stack | Why U.S. Actions in Venezuela and Iran Reveal the Structure of the AI Supply Chain | Prestige Markets as Signal Economies, A Model of Signal Suppression and Institutional Failure | Three AIs Walk Into Super Bowl LX and Each Simulation Thinks It Knows the Ending
IV. Behavioral Lock-In: The Real Moat Is the Loop, Not the Interface
Installment I, Installment II, and Installment III each foregrounded the interface layer as the primary competition surface. The interface is where users encounter AI. The interface is where developers build. The interface is where Apple’s distribution advantage lives. Installment IV upgrades that claim: the interface is the access point to the competition. The loop is the competition itself.
Behavioral lock-in does not require interface ownership. Behavioral lock-in requires that user cognitive patterns, workflow sequences, and decision architectures become shaped by — and dependent on — a specific AI system’s outputs. Once behavioral defaults form at sufficient depth, the user does not experience switching costs as an economic calculation. Switching costs manifest as cognitive friction: the user has learned to think through a specific system, structure queries for a specific model’s strengths, and interpret outputs within a specific epistemic framework. Replacing the system means not just changing a tool but partially rewiring a cognitive workflow.
Three Behavioral Lock-In Mechanisms
The Installed Cognitive Grammar (ICG) and Field-Geometry Reasoning (FGR) metrics produce the quantitative foundation for the lock-in mechanism analysis. ICG metrics — Pattern Recognition Index, Semantic Adaptation, and Embedding Index — measure how deeply an institution’s AI systems reshape user cognitive patterns through repeated interaction. FGR metrics — Constraint Density and Intent-Outcome Decoupling — measure the degree to which structural architecture overrides strategic intent in determining behavioral outcomes.

Table D. ICG and FGR Composite Metrics. ICG scores reflect cognitive adoption depth and workflow embedding. FGR scores reflect structural constraint override — institutions with high Constraint Density and Intent-Outcome Decoupling are governed by architecture more than strategy. Apple’s FGR Constraint Density of 0.92 is the highest in the system: no strategic override is available within Apple’s current constraint stack. OpenAI’s dual presence in both ICG and FGR confirms its split position — fastest cognitive adoption, partially constrained execution.
Microsoft’s enterprise-to-consumer bleed operates through workflow embedding. GitHub Copilot shapes how developers structure code problems before writing code. Office 365 Copilot shapes how knowledge workers structure written communication before composing it. The AI system is not answering questions inside existing workflows. The AI system is reshaping the workflows themselves — the sequences of cognitive steps users take before reaching the AI interaction point. Workflow embedding produces the deepest behavioral lock-in because it operates above the individual interaction level.
OpenAI’s consumer-to-enterprise bleed operates through familiarity transfer. ChatGPT’s consumer penetration produces behavioral defaults in personal AI usage — query patterns, output interpretation habits, iterative prompting sequences — that transfer into enterprise purchasing decisions because the employees making those decisions have already formed ChatGPT-specific cognitive defaults. Enterprise procurement trails the behavioral default rather than setting it. OpenAI’s lock-in mechanism operates at the cognitive vocabulary level: ChatGPT has shaped how a significant portion of knowledge workers conceptualize what AI interaction looks like.
Google’s ambient invocation mechanism operates at the subconscious routing layer. Android OS defaults route user intent through Gemini before the user makes a deliberate AI selection decision. Behavioral lock-in forms through repetition without conscious choice — the most durable form of default because it does not require the user to decide to keep using the system. Google’s lock-in operates below the level of explicit preference formation.
Anthropic’s precision-positioning mechanism produces high-trust behavioral defaults within regulated industry and enterprise contexts — but those defaults form through deliberate, episodic interactions rather than ambient or workflow-embedded patterns. High-trust lock-in is durable but narrower in scope and slower to compound than the three mechanisms above. Anthropic’s lock-in depth is high within its addressable user population and structurally capped at that population’s boundary.
The system that rewires user behavior does not need to own the interface. Every major intelligence provider in Installment III understood this. Apple has not.
V. System Equilibrium: Cybernetic Classification of the Terminal State
The Overview’s Section VI identified three terminal outcome scenarios: Controlled Mediation (commoditization wins, distribution retains value — 25%), Dependency Lock-In (concentration holds, intelligence layer captures margin — 55%), and Interface Displacement (AI-native interfaces bypass device ecosystems — 20%). Running the cybernetic control framework against those three scenarios produces a fourth classification that the probability weights implied but did not name: Viable Loop Consolidation.
Viable Loop Consolidation is the terminal state in which the consumer AI device market converges around two or three institutions with viable closed-loop architectures — Google unconditionally, Microsoft within the enterprise tier, and OpenAI conditionally — while all other institutions route through one of those loops. Viable Loop Consolidation is not equivalent to monopoly. Multiple viable loops can coexist when each governs a distinct user population or interaction context. The consolidation is in loop architecture, not market share — and loop architecture consolidation is more durable than market share concentration because it operates at the behavioral default layer rather than the product preference layer.
Viable Loop Consolidation produces a CDT Foresight Simulation probability of 58% within 60 months — the highest-weighted single terminal outcome — because it is the equilibrium that survives under both commoditization and concentration scenario resolutions. Under commoditization, distribution-anchored viable loops (Google, Microsoft enterprise tier) retain governance. Under concentration, capability-anchored viable loops (Google, OpenAI conditionally) retain governance. Viable Loop Consolidation does not require a specific governing variable resolution. It requires only that feedback latency compounds behavioral embedding faster than open-loop and semi-closed institutions can execute grammar overrides.
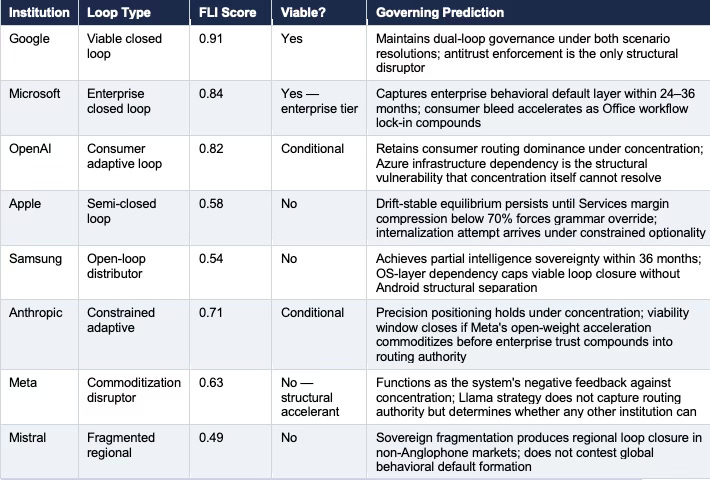
Table 3. Cross-Series CDT Compression — nine institutions across five dimensions. FLI scores derived from MAP CDT Foresight Simulation. Viable classification assessed against Ashby’s Requisite Variety condition and Beer’s recursive self-monitoring requirement.
VI. Cognitive Digital Twin Foresight Predictions
Every prediction in this section is a deterministic output of loop architecture differentials, not strategic intent or product competition. Control accumulates where feedback loops close fastest at the earliest capture surface — and the six predictions below are what that dynamic produces over observable time horizons. Each extends and sharpens the system-level predictions in the Overview by adding the causal mechanism — loop architecture dynamics — that the Overview’s Ashby analysis established structurally but left unmeasured. Each prediction carries a defined time window, observable confirmation signals, observable falsification signals, and a probability weight.
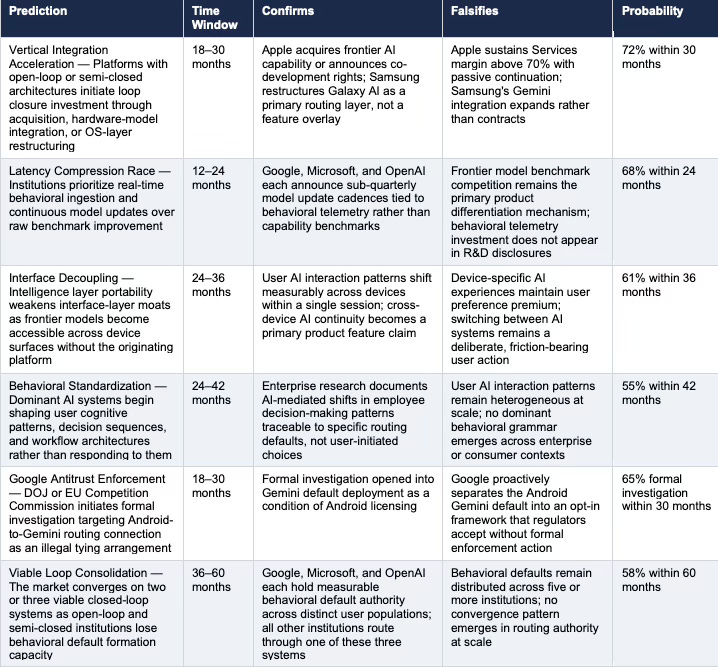
Table 4. CDT Foresight Predictions — six system-level predictions derived from cybernetic control framework analysis. Probability weights reflect MAP CDT Foresight Simulation output across both governing variable scenario resolutions. All predictions are falsifiable against observable market signals within the stated time windows.
VII. Falsification Conditions: What Would Disprove the Cybernetic Control Thesis
The cybernetic control thesis — consumer AI competition resolves through closed-loop behavioral default architecture, not product superiority, and viable closed loops govern over semi-closed and open-loop institutions across any governing variable resolution — fails under three distinct conditions.
Condition 1: Interface Dominance Sustains Governance Without Loop Closure
Apple sustains Services gross margin above 70% for 36 consecutive months while continuing to depend entirely on external intelligence providers, with no measurable behavioral default formation attributable to Apple’s own loop closure. If Apple’s interface ownership sustains margin and governance without internalizing the intelligence loop, the cybernetic control thesis is falsified at the device layer: interface control would be demonstrated to produce behavioral default authority without loop closure, contradicting the thesis’s core causal claim.
Condition 2: Users Override Behavioral Defaults at Scale
Consumer research across enterprise and personal AI usage contexts shows that 40% or more of users actively select non-default AI systems on a regular basis, indicating that behavioral defaults do not compound into lock-in at the rate the FLI framework predicts. If behavioral defaults remain fragile under competitive pressure — if users routinely override loop-embedded defaults when alternatives are available — the thesis’s causal mechanism fails. FLI scores would still be measurable but their predictive power for governance would be falsified.
Condition 3: Meta’s Commoditization Acceleration Outpaces Loop Closure
Meta’s Llama open-weight releases drive enterprise adoption to parity with frontier model contracts within 18 months, demonstrating that capability commoditization is accelerating faster than behavioral defaults are hardening. If the commoditization accelerant outruns the loop closure mechanism — if intelligence layer pricing compresses before enterprise behavioral workflows become deeply enough embedded to resist switching — viable loops cannot form before concentration dissolves. The cybernetic control thesis would be falsified in favor of a market structure where no institution achieves viable loop governance.
Condition 4: Loop Saturation
Users resist deeper behavioral embedding at scale — through privacy assertion, AI fatigue, or regulatory mandate — causing loop compounding to plateau before governance depth reaches the irreversibility threshold. Loop Saturation is the subtlest failure mode because it does not arrive as a competitive disruption. It arrives as a friction increase at the embedding layer: users begin explicitly overriding AI defaults, regulators mandate opt-in architectures that interrupt ambient capture, or behavioral fatigue reduces the interaction frequency that sustains loop learning. If LCS capture rates plateau across the system simultaneously — driven by EU AI Act or GDPR-adjacent behavioral data restrictions, or by user-driven default override rates exceeding 40% — the Control Law’s compounding dynamic slows, FLI differentials compress, and governance advantages narrow faster than loop architecture alone would predict. Loop Saturation does not falsify the CCM framework. It defines the ceiling condition under which FLI scores remain accurate but governance trajectories extend rather than accelerate to resolution. The institution most exposed to Loop Saturation is Google, whose ambient LCS depends on behavioral data ingestion at a scale and depth that regulatory intervention targets most directly. The institution least exposed is Microsoft, whose enterprise workflow embedding occurs inside contractual relationships that regulatory frameworks treat differently from consumer behavioral surveillance.
None of the four falsification conditions have triggered. Monitoring them is the correct forward analytical posture. Each condition is observable. Each carries a defined confirmation signal. Each represents a genuine failure mode for the thesis rather than a reformulation of it. The analytical integrity of the CCM framework depends on treating these conditions as real rather than rhetorical. If any falsification condition triggers, the CCM framework must be revised, not reinterpreted.
VIII. Series Synthesis: The Control Architecture That Was Always There
Four installments. Nine CDTs. One governing structure.
Installment I established that Apple is drift-stable toward dependency — not because Apple has failed strategically, but because Apple’s grammar produces the semi-closed loop architecture as its logical output. The interface that made Apple dominant is the access point Apple controls. The loop Apple cannot close is the control system that determines whether that access point retains governance value.
Installment II established that Google’s dual-loop position is the series’ central structural fact — not because Google has the best product across every dimension, but because Google is the only institution whose loop architecture achieves viability under both governing variable resolutions. Samsung’s open-loop distributor status is not a failure of investment. Samsung’s OS dependency places Google between Samsung’s sensing layer and Samsung’s behavioral embedding layer, making Samsung’s loop structure Google’s input regardless of how much Samsung Research invests in closing it.
Installment III established that value capture has migrated to the intelligence layer — and the intelligence layer is not a monolith but a competition between three distinct loop architectures with different latency profiles, embedding depths, and viability conditions. Microsoft’s enterprise loop achieves viability through depth. OpenAI’s consumer loop achieves conditional viability through interaction gravity. Anthropic’s constrained loop achieves precision without pervasiveness. Meta’s non-loop strategy governs the governing variable itself.
Installment IV delivers the integration layer. Consumer AI competition resolves through closed-loop control systems, not product superiority. Feedback Latency Index score determines which institutions’ behavioral defaults compound into irreversible governance and which remain competitively exposed regardless of product quality. Ashby’s viability condition identifies which institutions can match the system’s variety under both scenario resolutions and which must wait for external conditions to resolve favorably before their governance position stabilizes.
Wiener built the theory. Ashby proved the structural constraint. Beer operationalized the recursive architecture. The Consumer AI Device Series ran the proof on nine institutions in the market where the control system logic operates at the highest stakes.
Every device you hold routes your intent. The loop you never see governs your default — and over time, governs how you think, not just what you choose. The institution that closed the loop before you knew the contest had started has already won — not because it has the best product, but because it built the system inside which product competition plays out. At that point, competition has already ended.