

MCAI Market Vision: MindCast Predictive Game Theory AI vs. Market Predictive AI— Structural Foresight in Institutional Systems
How MindCast Generates Falsifiable Predictions Where Conventional Systems Produce Estimates

Related publications: MindCast Dynamic Game Theory— Competing Inside a System That Rewrites Itself | How MindCast Game Theory Differs from Textbook Game Theory | MindCast Cybernetic Game Theory | How MindCast Evolves the Structural Gaps in Classical Nash Game Theory
Visual Synthesis: MindCast Predictive Game Theory AI vs. Market Predictive AI
Together, the publications establish that prediction in live institutional systems requires modeling the mechanism that generates behavior, not extrapolating the pattern. That is the architecture this vision statement operationalizes.
I. The Problem Conventional Prediction Cannot Solve
Conventional market predictive AI assumes the rules governing a field are stable enough for historical data to stay informative. MindCast AI was built on the premise that the most consequential institutional outcomes occur precisely when that assumption fails — and that modeling them requires predictive game theory, not pattern extrapolation. Where market predictive AI extracts signal from historical distributions, the MindCast AI Proprietary Cognitive Digital Twin (CDT) Foresight Simulation models the multi-actor behavioral economics, strategic interactions, constraint geometry, and feedback loops that generate institutional outcomes — and derives what must follow before the equilibrium breaks.
The Method and Its Assumption
Most predictive systems learn from history. Statistical models extract patterns from past data, extend those patterns forward under assumptions of partial stability, and convert the output into operational scores, forecasts, and risk rankings. Large consulting firms layer judgment, benchmarking, and scenario planning on top of the same base logic. A McKinsey engagement assembles client data, compares it to peer benchmarks, constructs base and downside cases, and translates the result into board-level recommendations. The output is often well-framed and actionable. The output is also assumption-driven rather than structurally predictive — built on the premise that the rules governing the field remain stable enough for historical signal to stay informative.
The assumption is not unreasonable in stable environments. When constraints hold, when actors behave consistently, and when the rules of a market or regulatory field change slowly enough for historical data to remain representative, pattern extrapolation produces useful estimates. The problem is not the method. The problem is the scope of the method’s validity, and the institutional habit of applying it beyond that scope without awareness of the boundary.
The Break Condition
The formal break condition is precise: prediction fails when constraint stability falls below actor adaptation speed. In live institutional contests — litigation, regulatory enforcement, platform competition, legislative conflict — actors do not wait for the environment to stabilize before adapting. Rules mutate mid-contest. Actors manipulate the signals that models depend on. Feedback loops alter the game while the game is still being played. Narrative control shapes payoffs more reliably than underlying facts. At the break threshold, pattern extrapolation does not merely degrade — it inverts from signal to noise.
The Failure Cascade
What follows the break is not random error. The failure unfolds in a predictable sequence. Models begin to overfit recent noise, mistaking the most recent high-volatility observations for signal. Forecast error surfaces as apparent market volatility rather than as model failure, and the diagnostic interpretation points toward better data or faster updating rather than structural inadequacy.
Decision-makers, facing what looks like volatility rather than a broken model, increase reliance on the same prediction infrastructure. The feedback loop accelerates miscalibration. By the time the model’s failure is legible, the window for strategic positioning has closed. The organizations that moved earliest on accurate structural diagnosis capture the available advantage; those that waited for the model to self-correct absorb the loss.
Every major institutional failure of conventional prediction — the synchronized mispricing of mortgage risk in 2008, the failure of supply-chain models in 2021, the inability of political forecasting models to price structural electoral shifts — follows this cascade. The failure is not a data problem or a modeling problem in the narrow technical sense. The failure is a category error: applying a method calibrated for stable environments to systems that were already in structural transition.
The Equilibrium in Practice: Two Named Illustrations
The most instructive examples of this failure mode do not come from organizations that lacked analytical resources. They come from the most credentialed institutions in the field, producing outputs that optimize for adoptability rather than structural truth — and calling the result foresight.
Deloitte Insights’ Tech Trends 2026 report carries the subtitle “Cutting through the noise: Tech signals worth tracking as AI advances” and frames itself explicitly around strategic foresight. The report identifies neuromorphic chips, generative engine optimization, edge AI, and biometric authentication as technology signals demanding attention. Every claim is directional and hedged: large foundation models “may be nearing a plateau,” neuromorphic adoption is projected for “by 2030,” biometrics are “emerging as a critical layer.” No actor is modeled. No governing mechanism is specified. No falsification condition appears anywhere in the document. The report states that “these technology signals represent current phenomena, not just speculative futures” — a framing that locates the analysis in retrospective aggregation rather than structural derivation.
Adaptability, Deloitte concludes, matters more than predictive certainty — a conclusion consistent with Stigler termination, where inquiry stops once outputs remain adoptable without mechanism specification. The absence of mechanism is not a quality failure. It is the structurally predictable output of an analytical process optimized for client adoption rather than falsifiable prediction.
Stanford HAI’s December 2025 faculty prediction survey assembled leading researchers across computer science, medicine, law, and economics to forecast 2026 AI developments. The predictions include claims that “the era of AI evangelism is giving way to evaluation,” that standardized legal reasoning benchmarks will emerge, and that real-time labor displacement dashboards will appear. No prediction carries a falsification contract. No agent is specified. No mechanism explains why any predicted outcome must follow from any identified structure. The absence is not incidental — it is structurally consistent with an output optimized for reputational defensibility rather than empirical falsification. What institutional authority cannot substitute for is mechanism specification: the identification of which actors, operating under which constraints, through which feedback loops, produce which outcomes as a matter of structural necessity.
Neither Deloitte nor Stanford’s faculty are operating carelessly. Both are operating rationally inside the equilibrium that governs their incentive structures. Deloitte’s output must survive client adoption. Stanford’s faculty survey must survive editorial and reputational review. Both selection pressures push toward claims that are credible, defensible, and unfalsifiable. The problem is not the organizations. The problem is the equilibrium — and the fact that no one inside it has an incentive to identify the structural mechanism that would make the output genuinely predictive rather than merely authoritative.
II. The Equilibrium That Traps Industry Practice
How the Trap Forms
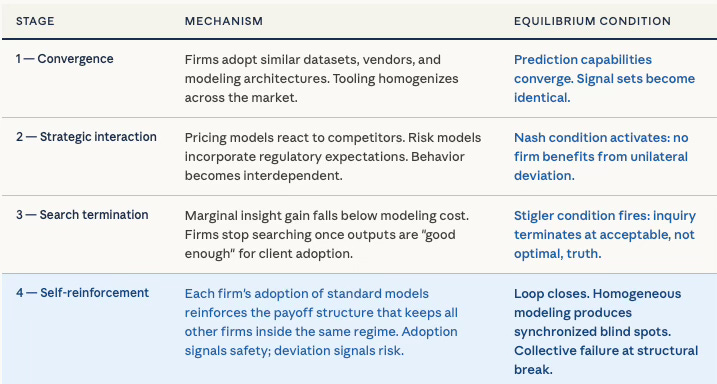
Industries have not merely failed to solve the structural prediction problem — they have stabilized around a practice that makes the problem invisible. Firms converge on similar datasets, similar vendors, and similar modeling architectures. Abandoning standard predictive tools produces worse near-term decisions. Radically upgrading them produces uncertain payoff. The Nash condition holds: no firm benefits from unilateral deviation.
The Stigler condition compounds the trap. Firms stop searching for better models once marginal insight gain falls below marginal modeling cost. Inquiry terminates at acceptable, not optimal, truth. The result is a Nash-Stigler equilibrium over predictive practice — stable under past-pattern continuity, brittle under structural change. As The Dual Nash-Stigler Equilibrium Architecture establishes, behavioral settlement and inquiry sufficiency function as runtime constraints — and the same dual-termination logic that governs MindCast’s internal architecture describes precisely why conventional predictive practice plateaus short of truth.
Why Rational Actors Stay Trapped
The equilibrium persists not because actors are irrational but because the incentive structure punishes early deviation. An analyst who abandons consensus models before the structural break is provable faces career risk before the payoff to accuracy materializes. Conformity to standard modeling practice produces immediate rewards — credibility, institutional alignment, institutionally acceptable outputs — while the cost of that conformity is diffuse, delayed, and attributed to market conditions rather than model failure when it arrives. The payoff to truth is delayed; the payoff to conformity is immediate. Under those conditions, rational actors stay inside the equilibrium even when they privately recognize its inadequacy.
The equilibrium is self-reinforcing in the precise cybernetic sense. Each firm’s adoption of standard predictive models reinforces the payoff structure that keeps all other firms inside the same modeling regime. Adoption signals safety; deviation signals risk. The loop closes. New entrants observe the stable payoff structure and adopt the same tools, deepening the equilibrium with each cycle. The system does not drift toward the accurate model — it drifts away from it, because accuracy under structural instability requires the very deviation that the equilibrium penalizes.
The Synchronized Failure
Homogeneous modeling compounds into synchronized blind spots. When rules change, when strategic actors manipulate signals, when feedback loops accelerate, every firm misses the same structural shift at the same time. Synchronized failure is not merely a collective inefficiency — it is a strategic opportunity for the actor who operates outside the equilibrium. The gap between the moment of structural break and the moment when conventional prediction registers that break is the window in which asymmetric advantage concentrates. MindCast operates inside that window by design.
Contact mcai@mindcast-ai.com to partner with us on Predictive Law and Behavioral Economics + Game Theory Foresight Simulations. To deep dive on MindCast work in Cybernetic Foresight Simulations upload the URL of this publication into any LLM and prompt ‘reconstruct MindCast framework with three degrees of cited sub links.’ See Live-Fire Game Theory Simulators, Runtime Predictive Infrastructure
How MindCast Game Theory Differs from Textbook Game Theory establishes the foundational break. Textbook game theory models thin rational actors optimizing fixed payoffs toward equilibrium. MindCast replaces that architecture with Cognitive Digital Twins — institutional actors encoded with behavioral constraints, narrative commitments, adaptation limits, and feedback sensitivities — operating inside systems where signals degrade and incentives mutate during play. The shift changes the purpose of game theory from explaining what players should do under specified rules to predicting what specific institutions will do as the rules rewrite themselves.
MindCast Dynamic Game Theory — Competing Inside a System That Rewrites Itself extends that architecture into rule-mutating environments, establishing rule evolution as a first-order competitive variable. Institutions are not passive referees — they are active rule engines, and the actors who anticipate rule mutation before it occurs capture structural advantage before traditional competition begins. Timing, forum sequencing, and jurisdictional drift become the dominant strategic levers.
Cybernetic Game Theory completes the architecture by recasting strategy around control rather than choice. Four mechanisms — delay dominance, narrative control, feedback capture, and constraint geometry — explain why institutions stabilize around wrong answers: feedback loops enforce control over accuracy, and the architecture makes that trade-off invisible to every actor inside it. Loop closure speed governs outcomes more decisively than the quality of any isolated analytical move.
III. The MindCast Departure: Mechanism Over Pattern
The Question Changes
MindCast departs at the level of the question asked. Conventional prediction asks what the data suggests will happen next. MindCast asks what structure is generating outcomes — and whether that structure will persist. The analytical unit shifts from variable to mechanism, and from probability to constrained necessity. A variable can be measured. A mechanism must be identified, mapped, and tested against the adaptive behavior of the actors it governs. Those are different intellectual operations, and they require different architecture.
MindCast proprietary Cognitive Digital Twins (CDTs) serve as the core unit of analysis in MindCast Game Theory, modeling institutions and actors as adaptive systems rather than static decision-makers. Within the foresight simulation, CDTs encode constraints, incentives, and feedback loops, allowing the system to derive how each actor will behave as conditions evolve and rules mutate. This architecture enables MindCast to move beyond probabilistic forecasting and instead generate structurally grounded predictions based on how interacting CDTs reshape the game in real time.
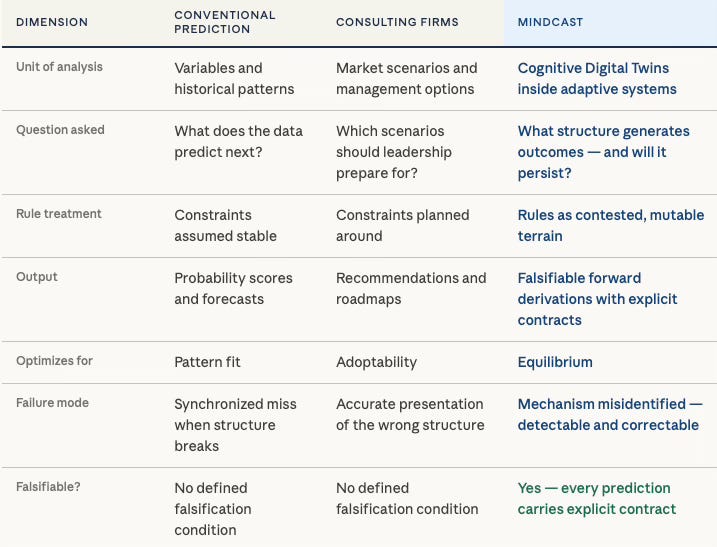
The governing architecture is the MindCast AI Proprietary Cognitive Digital Twin (CDT) Foresight Simulation — a proprietary institutional modeling system developed by MindCast AI. Institutions, regulators, litigants, and platforms are modeled not as data generators but as adaptive actors operating inside environments where incentives mutate, rules are contested terrain, and feedback loops alter the game while the game is still being played. How MindCast Game Theory Differs from Textbook Game Theory establishes the core break: where textbook game theory assumes thin rational actors optimizing fixed payoffs, MindCast models thick behavioral architectures operating inside systems that rewrite themselves. MindCast Dynamic Game Theory — Competing Inside a System That Rewrites Itself extends the architecture into rule-mutating environments, treating institutions as rule-generating systems rather than passive referees and establishing timing, forum sequencing, and rule anticipation as first-order strategic variables. MindCast Cybernetic Game Theory recasts strategy around control rather than choice — demonstrating that equilibrium can emerge without truth, and that loop closure speed often governs outcomes more decisively than the quality of any isolated analytical move.
How a Simulation Runs
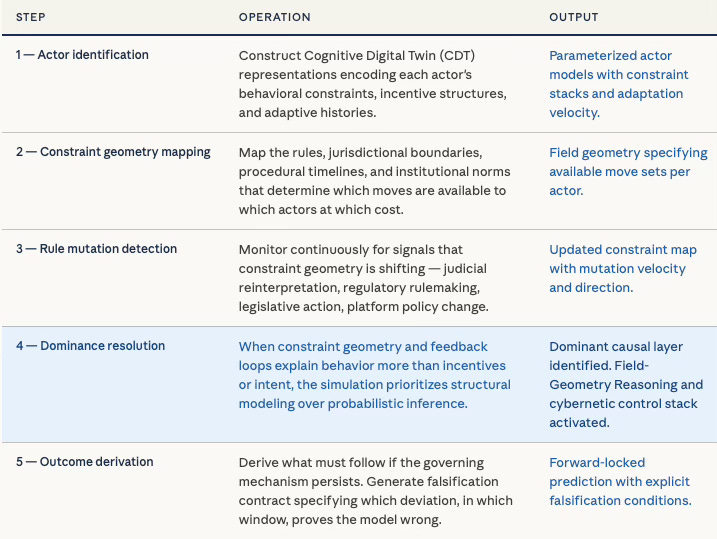
The simulation sequence makes the departure from conventional prediction concrete. Each simulation begins by identifying the actors in the field and constructing Cognitive Digital Twin representations that encode their behavioral constraints, incentive structures, and adaptive histories. The simulation then maps the constraint geometry — the rules, jurisdictional boundaries, procedural timelines, and institutional norms that determine which moves are available to which actors at which cost.
Rule mutation detection runs continuously: the simulation monitors for signals that the constraint geometry is shifting, whether through judicial reinterpretation, regulatory rulemaking, legislative action, or platform policy change. When constraint geometry and feedback loops explain behavior more than incentives or intent, the simulation prioritizes structural modeling over probabilistic inference — the dominance condition that ties the Cognitive Digital Twin architecture directly to Field-Geometry Reasoning and the cybernetic control stack.
Feedback loop evaluation identifies the channels through which actor behavior re-enters the system as new constraint. A regulatory prediction, once public, becomes a signal that shapes the behavior of the regulated party, which in turn changes the regulatory calculus — that loop is modeled explicitly rather than treated as noise. The simulation derives outcome under mechanism persistence: given that this constraint geometry, these actor behavioral architectures, and these feedback loops continue to operate, what must follow? The output is not a probability distribution over historical analogs. The output is a constrained derivation — a claim about what the governing mechanism requires.
Foresight Versus Forecasting
The output of the simulation is not an estimate of what will probably occur. The output is a derivation of what must follow if the governing mechanism persists. Foresight and forecasting are not synonyms: forecasting operates in probability space over historical distributions; foresight operates in mechanism space over structural logic. A forecast can be wrong because the world is uncertain. A foresight claim is wrong only if the mechanism has been misidentified or the structure has changed — both of which are falsifiable and detectable, which is precisely why foresight carries a falsification contract and forecasting cannot.
IV. Falsifiable Foresight as the Standard
The Contract
Prediction without falsification is sophisticated guessing. MindCast predictions carry explicit falsification contracts specifying which agent deviation, within which temporal window, under which observable condition, would prove the prediction wrong. A prediction that cannot specify its own falsification condition is rejected by the system before release. Defeating Nondeterminism: Building the Trust Layer for Predictive Cognitive AI establishes reproducibility as the foundational institutional trust requirement: identical inputs must yield identical conclusions or the system fails calibration. Termination must occur for principled economic reasons — both Nash behavioral settlement and Stigler inquiry sufficiency must fire — not arbitrary token limits.
The dual-equilibrium architecture enforces both conditions. Nash equilibrium governs behavioral settlement — determining when a multi-actor conflict reaches a stable basin where no agent can improve by unilateral deviation. Stigler equilibrium governs inquiry sufficiency — capping search when marginal integrity gain falls below marginal compute cost. Neither can override the other. Both must fire before the simulation commits to a prediction. The result is not a probabilistic impression but a specific, auditable, institutionally defensible claim about who moves, when outcomes lock in, and what evidence would falsify the conclusion. Judicial Deconstruction of Compass’s Narrative Arbitrage v. Zillow provides that test.
The Contract in Action: Compass v. Zillow (SDNY, Feb. 6, 2026)
The highest-credibility validation environment for institutional foresight is a federal court proceeding — where the adversarial process independently tests the same structural thesis the simulation identified in advance. The Compass v. Zillow preliminary injunction ruling provides that test.
Mechanism Identified Compass’s litigation posture carried a structural contradiction: the seller-choice framing deployed in consumer marketing and Washington State legislative testimony was logically incompatible with the competitive-harm theory required to sustain a Sherman Act claim. Cross-forum incoherence of that kind is a self-inflicted structural failure mode the CDT identifies before adversarial process surfaces it.
Foresight Prediction Compass would fail to meet the preliminary injunction threshold because the cross-forum contradiction requires a court to accept that identical conduct is simultaneously pro-competitive when Compass runs it and anti-competitive when a rule constrains it. No Sherman Act theory survives that internal contradiction under evidentiary scrutiny.
Falsification Contract If Judge Vargas granted the preliminary injunction or found Compass met even the ‘serious questions’ threshold, the structural mechanism mapping was false. The court found Compass failed to meet the standard below likelihood of success. Four predictions, four confirmed holdings.
Strategic Value Actors holding this structural diagnosis months before the February 6 ruling operated with an accurate model of Compass’s legal trajectory while the public narrative continued to frame the case as a competitive fight Compass was winning.
The Forward-Locked Contract: KalshiEX LLC v. Assad
Confirmed predictions validate the architecture against past outcomes. Forward-locked predictions test it under live adversarial conditions. MindCast published eight analytical papers mapping the Kalshi prediction market litigation from structural origins through the April 16, 2026 Ninth Circuit oral argument. The full corpus:
The Ninth Circuit, Kalshi and the First Measurable Test of Prediction Market Structure — Flagship April 16 publication. Sixteen CDT predictions across four tracks with explicit falsification contracts.
Prediction Markets Litigation Stack — Federal, Private, and State Enforcement Converge — Four simultaneous enforcement tracks mapped. DOJ federal override, Arizona criminal prosecution, sealed platform offensive, 30-state coalition.
Kalshi’s Prediction Market Litigation Architecture, the CFTC Amicus, and the Strategic Framework for State Enforcement — Circuit-split engineering strategy. CFTC amicus as political accelerant. State enforcement procedural counter-moves.
The National Kalshi Prediction Market Litigation Map — Sixteen state enforcement actions across four appellate circuits. Removal asymmetry and cascade mechanic. P45 modal outcome assigned to gambling classification.
Prediction Markets — Legislative Regime Conversion and the Collapse of Preemption — Statutory Category Exclusion Mechanism (SCEM). Three of six CDT trigger predictions activated within five days of publication.
Kalshi Found the One Gap in American Gaming Law Nobody Closed — Four Cybernetic Game Theory poaching mechanisms. Revenue displacement data. Structural default prediction if architecture persists.
Kalshi Is Crypto’s Test Case — CFTC as unified control layer for prediction markets and crypto. Capital coalition field geometry analysis.
Kalshi, Prediction Markets and the Conflict Architecture of Regulation — Overlapping jurisdiction and real-time financial feedback loops produce regulatory conflict as equilibrium outcome, not accident.
The Full Arc of Prediction Markets — Full spectrum framework from signal to control. Kalshi election market controversy as live-fire instantiation.
Active falsification contract from the flagship publications:
Mechanism Identified State enforcement agencies modeled as Stigler-captured actors with concentrated incumbent interests, held in a Nash equilibrium where no single state moves first absent federal jurisdictional resolution.
Foresight Prediction Multi-state enforcement remains coordinated but procedurally suspended pending Ninth Circuit outcome; no unilateral state action before oral argument.
Falsification Contract If any state AG files independent enforcement action before April 16, the equilibrium mapping is false and the mechanism requires revision.
Strategic Value Actors holding this prediction avoid mispricing regulatory timeline risk by weeks — the window in which positioning decisions lock in and cannot be reversed.
When a Prediction Fails
Falsification is not a liability — it is the mechanism by which the system learns. When a prediction fails its falsification condition, the system does not simply register an error. The deviation is logged with the timestamp and observable conditions under which it occurred. The mechanism mapping that generated the failed prediction is reopened: which actor moved unexpectedly, under what constraint, and what that deviation implies about the underlying structural model. The calibration gap — the distance between the predicted equilibrium basin and the actual outcome — is measured and fed back into the CDT parameters for that actor class.
A falsified prediction makes the next prediction more accurate. Each failure narrows the model’s error bounds by identifying a specific structural assumption that requires revision. Over time, accumulating falsification records produces a calibrated institutional model whose accuracy is directly traceable to its testing history. No consulting deliverable and no conventional AI output carries that property. A recommendation shaped to survive management review cannot be falsified by design — because its standard of correctness is adoptability, not structural truth.
V. Where MindCast Operates
The Structural Signature
Every domain MindCast covers shares the same structural signature: a live Nash-Stigler predictive equilibrium among analysts and institutional actors, a governing mechanism that conventional models do not map, and a structural break point at which synchronized failure concentrates asymmetric advantage for the actor who identified the mechanism in advance. The conditions that defeat conventional prediction are precisely the conditions that define MindCast’s operational territory: live multi-actor conflict, rule mutation, cross-forum strategic interaction, and narrative control functioning as a mechanism of payoff engineering rather than as a communications layer.
Active Coverage Domains
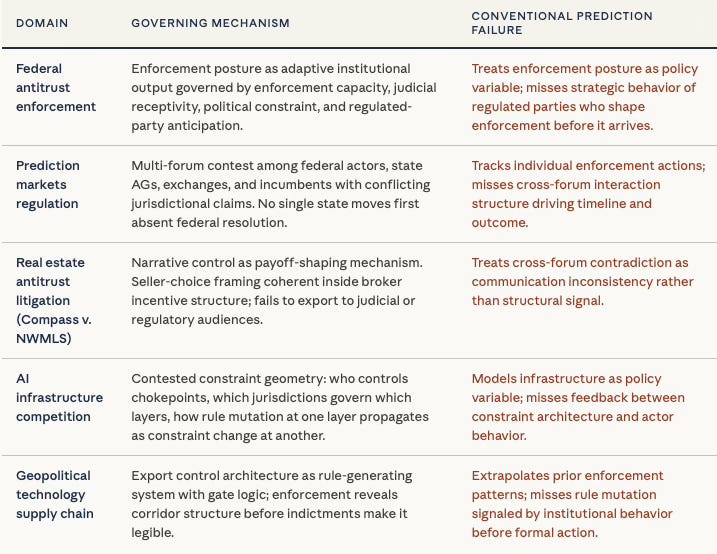
Federal antitrust enforcement architecture presents the signature in its clearest form. The DOJ and FTC operate as rule-generating systems whose enforcement priorities shift with administration, judicial doctrine, and regulated-industry lobbying. Conventional analysis treats enforcement posture as a policy variable. MindCast models it as an adaptive institutional output governed by the interaction between enforcement capacity, judicial receptivity, political constraint, and the strategic behavior of regulated parties who anticipate and shape enforcement before it arrives.
Prediction markets regulation and jurisdictional convergence is an active multi-forum contest in which federal and state actors, exchanges, incumbent financial intermediaries, and tribal gaming operators hold conflicting claims over the same legal territory. The Nash-Stigler equilibrium among regulatory analysts — who track individual enforcement actions rather than the cross-forum interaction structure — produces synchronized misreading of timeline and outcome. MindCast maps the interaction structure and derives the jurisdictional resolution path from the governing mechanism.
Real estate market structure litigation, including the Compass v. NWMLS matter and the broader MLS antitrust architecture, presents a case in which narrative control operates as an explicit strategic asset. Institutional actors deploy internal framing — such as the “seller choice” narrative applied to Washington SSB 6091 — that functions coherently inside the broker incentive structure but fails to export to judicial or regulatory audiences. Mapping the narrative control mechanism produces predictions about cross-forum contradiction that conventional legal analysis treats as inconsistency rather than as a structural signal.
AI infrastructure competition and geopolitical technology supply chain constraint share the structural feature that the contested terrain is constraint geometry itself — who controls the chokepoints, which jurisdictions govern which layers, and how rule mutation at one layer propagates as constraint change at another. Conventional forecasting treats these as policy variables. MindCast models the feedback between constraint architecture and actor behavior as the primary generative mechanism.
The Cross-Domain Transfer
The same structural logic governs all four domains. Antitrust enforcement, prediction markets regulation, real estate litigation, and AI infrastructure competition are not analytically separate problems that happen to share surface features. Each is a manifestation of the same underlying system: concentrated actors with asymmetric information and incentive to shape rules, diffuse actors with delayed coordination capacity, institutions that function as rule-generating feedback systems rather than neutral referees, and narrative control as the mechanism by which constraint geometry is contested before it is formally codified. The Cybernetic Foundations of Predictive Institutional Intelligence: The Architecture of Institutional Foresight maps the theoretical substrate that makes this transfer possible: Ashby’s law of requisite variety establishes the minimum structural complexity a model must carry to govern the system it describes; Beer’s viable system model identifies the feedback layers an institution must maintain to remain adaptive under stress; Wiener’s control theory specifies how loop closure speed determines which actor governs an outcome. These foundations are not decorative. Strip them from the architecture and the cross-domain transfer collapses.
MindCast does not help organizations manage uncertainty. Managing uncertainty presupposes the structure generating uncertainty is sufficiently known. MindCast identifies the structure, models the actors as adaptive systems, and derives what must follow if the mechanism persists — before the equilibrium breaks, not after.
VI. The Institutional Case
The Gap That Remains Open
Institutional decision-makers — regulators, litigants, capital allocators, and strategic operators — face a predictive gap that neither AI tools nor major consulting firms currently close. AI tools optimize for fluency: producing coherent, well-organized outputs that sound authoritative regardless of whether the underlying structure has been correctly identified. Consulting firms optimize for adoptability: producing recommendations calibrated to survive management review, board presentation, and political constraint within the client organization.
Both modes of production select for outputs that conform to what the institution is already prepared to accept. Neither selects for structural truth. The gap is not a criticism of those tools in stable environments. The gap is a precise description of where they break — and where the cost of that break is highest.
The Cost of Staying in the Old Equilibrium
Organizations that remain inside the Nash-Stigler predictive equilibrium do not simply underperform — they absorb compounding structural liability. Regulatory policy lags the mechanism that generates the need for regulation: by the time enforcement posture shifts to match structural reality, the window for proactive positioning has closed, and litigation becomes reactive rather than predictive.
Capital misallocates against a model of institutional behavior that the governing mechanism has already superseded: positions built on conventional timeline estimates are unwound at a loss when the structural break registers in market prices. Litigation strategy is constructed around a narrative of the contest that cross-forum contradiction has already undermined: briefs are filed on premises the opposing forum has already rejected, producing avoidable inconsistency that sophisticated adversaries exploit.
All three failure modes share the same structure: the institution learns about the structural break after the window for asymmetric advantage has closed. Earlier structural diagnosis — by weeks, not months — changes the available action set. Positioning decisions that are irreversible at T+3 are still open at T. The value of structural foresight is not merely better information. The value is access to the action set that closes when the equilibrium breaks.
What MindCast Delivers
MindCast applies the MindCast Simulation directly to live institutional contests — litigation, regulatory proceedings, market structure conflicts, and strategic competition — producing CDT-grounded mechanism maps, falsification-contracted forward derivations, and structural foresight outputs that reach decision-makers before the governing equilibrium breaks. Access is tiered by timing and depth of simulation output: advance access to forward-locked predictions prior to public resolution is the primary value delivery point. MindCast publishes selected framework applications against live-fire events at www.mindcast-ai.com, generating the empirical track record that validates the methodology and surfaces the architecture to institutional actors operating inside the domains it covers.
MindCast optimizes for equilibrium. Every foresight output is a scientific claim subject to empirical validation, not a recommendation shaped to survive management review. Each prediction is timestamped, published, and cross-referenced to the underlying structural record before the outcome resolves. The full validation corpus is archived at www.mindcast-ai.com/t/validation.
Judicial Deconstruction of Compass’s Narrative Arbitrage v. Zillow — Compass v. Zillow, SDNY, Feb. 6, 2026. Four confirmed holdings against four published CDT predictions. The cross-forum incoherence mechanism was identified and published months before Judge Vargas ruled.
The Compass–Zillow Antitrust Litigation Arc Is Closed — March 2026. Compass’s two years of litigation generated the evidentiary record subsequently used against it — the self-inflicted structural failure mode the CDT identified at the outset.
How MindCast AI Predicted the Slater Ouster Before the DOJ Executed It — The access-arbitrage architecture governing the removal was published before the DOJ executed it. The architecture was already in the record.
The US DOJ–Live Nation Settlement and the New Era of Distributed Antitrust Enforcement — March 2026. A 26-state coalition activated the competitive federalism migration the CDT modeled. Nash–Stigler behavioral normalization confirmed.
H200 China Policy Validation — How MindCast AI’s Six-Publication Series Predicted the ‘Gate Without Fence’ Architecture — January 2026. Six publications predicted the policy architecture before the announcement. Confirmed on publication.
Foresight on Trial — The Diageo Litigation Validation — Three parallel cases (EDNY, NDCA, SDFL) transferred December 2025, matching the predicted consolidation path via first-to-file rule.
SSB 6091 Passes the Washington Senate 49-0 — Compass’s Private Exclusive Model Faces Institutional Convergence — Passage trajectory and Astroturf Coefficient (17:1 among Compass-affiliated opposition witnesses) confirmed before the vote. Cross-forum synthesis identified seven months before institutional convergence.
Prediction Markets — Legislative Regime Conversion and the Collapse of Preemption — Three of six CDT trigger predictions activated within five days of publication: Arizona criminalized the conflict, Nevada secured a multiplatform ban extending the enforcement model, and Kalshi narrowed its contract universe. Each trigger was specified in advance with observable falsification conditions.
The National Kalshi Prediction Market Litigation Map — Removal asymmetry and cascade mechanic confirmed across sixteen state enforcement actions. P45 modal outcome assignment to gambling classification validated as the structurally predicted equilibrium. PRGA behavioral signal — Kalshi’s voluntary contract screening as a private probability compression indicator — published before the behavior occurred and confirmed.
Kalshi’s Prediction Market Litigation Architecture, the CFTC Amicus, and the Strategic Framework for State Enforcement — Circuit-split engineering strategy confirmed by DOJ federal override filing and Arizona criminal prosecution consolidation. CFTC amicus as political accelerant confirmed by bipartisan state AG coalition activation.
Super Bowl LX and Seahawks 2025–2026 Season Validation — Seven Simulations. Seven Winners. One Architecture. — Seattle 29, New England 13. Seven consecutive correct structural predictions. Published falsification contracts, time gates, and a transparent mid-season model revision after the NFC Championship falsified the compression thesis. Zero falsification triggers activated.
The architecture delivers the same structural diagnosis across every domain because the same governing mechanism — constraint, feedback, strategic interaction, rule mutation — operates across every domain.
The standard for institutional foresight is not fluency. The standard is whether the prediction identifies the governing mechanism, models the actors correctly, locks the falsification window before the outcome resolves, and updates the model when the falsification condition fires.
MindCast either meets that standard or does not publish.